Understanding Syllogistic Reasoning in LLMs from Formal and Natural Language Perspectives
作者: Aheli Poddar, Saptarshi Sahoo, Sujata Ghosh
分类: cs.CL, cs.AI
发布日期: 2025-12-14 (更新: 2025-12-29)
备注: 9 pages, 4 figures, 5 tables. Accepted at AAAI 2026 Bridge Program on Logic & AI. Code available at https://github.com/XAheli/Logic-in-LLMs
💡 一句话要点
研究大型语言模型在形式语言和自然语言视角下的三段论推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 三段论推理 符号推理 自然语言理解 逻辑推理 形式语言 推理能力评估
📋 核心要点
- 现有方法难以充分理解LLMs在逻辑推理和自然语言理解方面的综合能力,尤其是在三段论推理任务中。
- 本文通过分析LLMs在符号推理和自然语言理解上的表现,揭示其三段论推理能力,并探讨其与人类推理的差异。
- 实验结果表明,不同LLMs的三段论推理能力存在差异,部分模型在符号推理上表现出色,但与人类推理的细微差别仍有差距。
📝 摘要(中文)
本文从逻辑和自然语言的角度研究了大型语言模型(LLMs)中的三段论推理。在此过程中,我们探索了LLMs的基本推理能力以及该研究领域的发展方向。为了辅助我们的研究,我们使用了14个大型语言模型,并从符号推理和自然语言理解两个方面考察了它们的三段论推理能力。尽管这种推理机制并非LLMs普遍涌现的属性,但某些模型在符号推理方面的完美表现让我们不禁思考,LLMs是否正变得越来越像形式推理机制,而不是明确地表达人类推理的细微差别。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在三段论推理任务中的表现,并分析其推理能力与人类推理的异同。现有方法通常侧重于评估LLMs在特定任务上的性能,而忽略了从形式语言和自然语言两个角度综合评估其推理能力。此外,现有研究较少关注LLMs在三段论推理中是否能够体现人类推理的细微差别。
核心思路:论文的核心思路是从形式语言(符号推理)和自然语言理解两个角度,全面评估LLMs的三段论推理能力。通过分析LLMs在不同推理模式下的表现,揭示其推理机制的特点,并探讨其与人类推理的差异。这种双重视角有助于更深入地理解LLMs的推理能力,并为改进LLMs的推理性能提供指导。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择14个具有代表性的大型语言模型;2) 构建包含符号推理和自然语言理解两种类型的三段论推理数据集;3) 使用这些数据集对LLMs进行评估,并记录其推理结果;4) 分析LLMs在不同推理模式下的表现,比较其与人类推理的差异;5) 总结LLMs的三段论推理能力特点,并探讨其未来发展方向。
关键创新:论文的关键创新在于从形式语言和自然语言两个角度综合评估LLMs的三段论推理能力。这种双重视角有助于更全面地理解LLMs的推理机制,并揭示其与人类推理的差异。此外,论文还通过实验分析了不同LLMs在三段论推理上的表现差异,为改进LLMs的推理性能提供了有价值的参考。
关键设计:论文的关键设计包括:1) 构建包含符号推理和自然语言理解两种类型的三段论推理数据集,以全面评估LLMs的推理能力;2) 选择具有代表性的LLMs,以保证研究结果的普适性;3) 采用合适的评估指标,以准确衡量LLMs的推理性能;4) 对LLMs的推理结果进行深入分析,以揭示其推理机制的特点。
🖼️ 关键图片


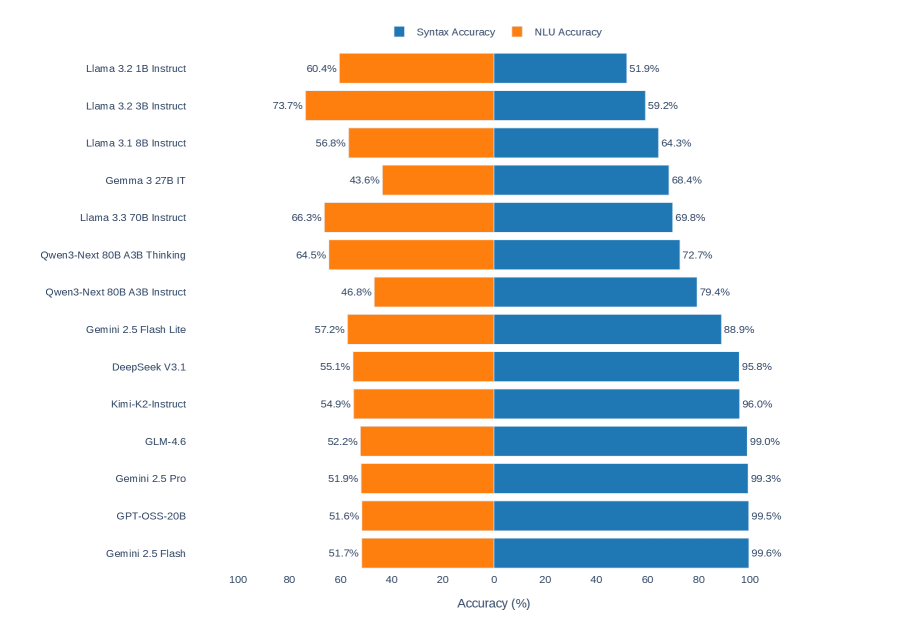
📊 实验亮点
实验结果表明,不同LLMs的三段论推理能力存在显著差异。部分模型在符号推理方面表现出色,甚至达到了完美的性能。然而,在自然语言理解方面,LLMs的推理能力仍有待提高。此外,研究还发现,LLMs在三段论推理中存在一些与人类推理不同的特点,例如对某些推理模式的偏好等。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、智能问答系统、逻辑推理引擎等。通过深入理解LLMs的推理能力,可以开发出更智能、更可靠的AI系统。此外,该研究还可以为改进LLMs的推理性能提供指导,使其更好地模拟人类的推理过程,从而在更广泛的应用场景中发挥作用。
📄 摘要(原文)
We study syllogistic reasoning in LLMs from the logical and natural language perspectives. In process, we explore fundamental reasoning capabilities of the LLMs and the direction this research is moving forward. To aid in our studies, we use 14 large language models and investigate their syllogistic reasoning capabilities in terms of symbolic inferences as well as natural language understanding. Even though this reasoning mechanism is not a uniform emergent property across LLMs, the perfect symbolic performances in certain models make us wonder whether LLMs are becoming more and more formal reasoning mechanisms, rather than making explicit the nuances of human reasoning.