Coupled Variational Reinforcement Learning for Language Model General Reasoning
作者: Xueru Wen, Jie Lou, Yanjiang Liu, Hongyu Lin, Ben He, Xianpei Han, Le Sun, Yaojie Lu, Debing Zhang
分类: cs.CL, cs.AI
发布日期: 2025-12-14 (更新: 2026-01-27)
💡 一句话要点
提出耦合变分强化学习CoVRL,提升语言模型通用推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 语言模型 通用推理 变分推理 耦合学习
📋 核心要点
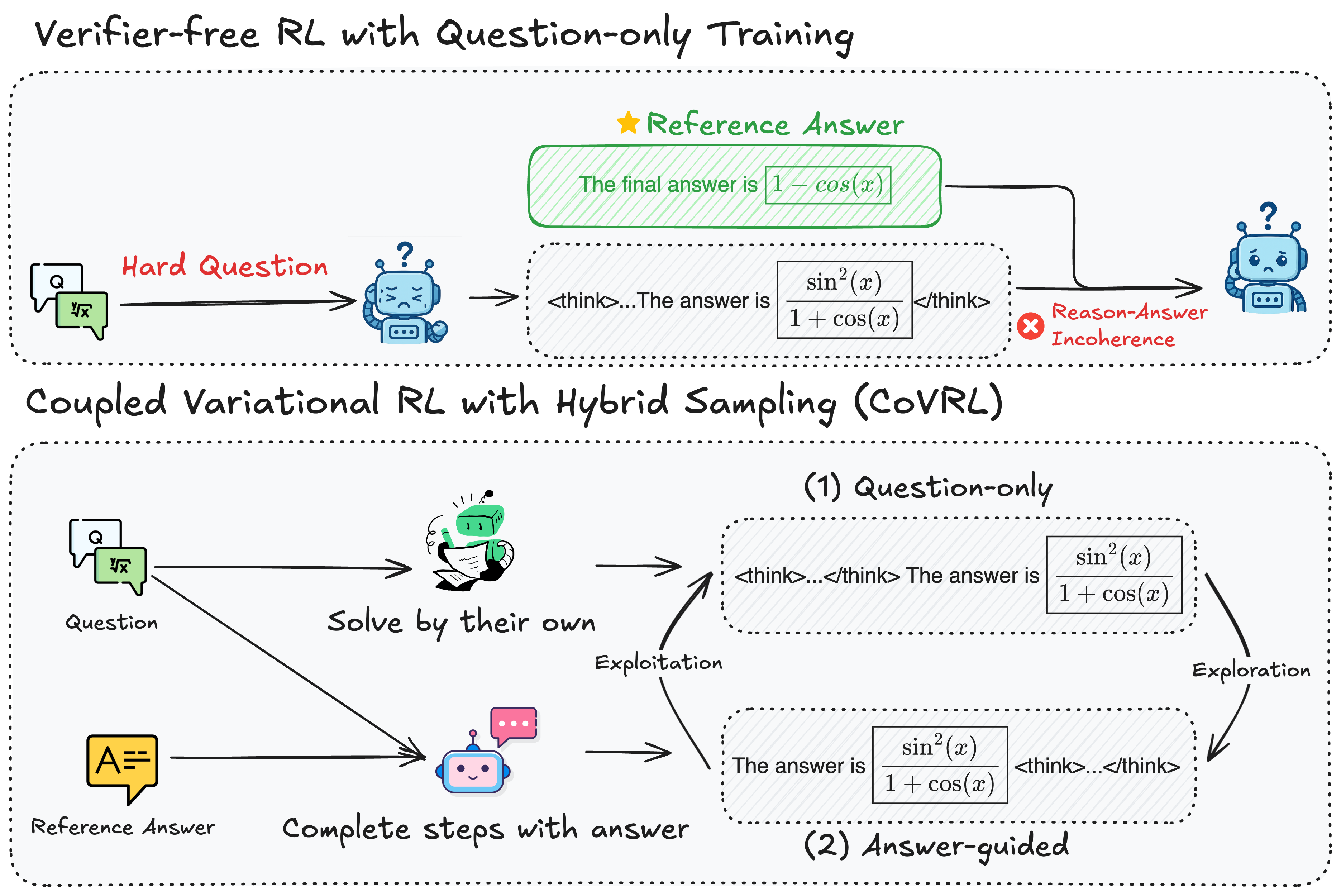
- 现有语言模型推理方法依赖可验证奖励或忽略答案信息,导致探索效率低和推理不连贯。
- CoVRL通过耦合先验和后验分布,构建复合分布,实现高效探索并保持思想-答案一致性。
- 实验表明,CoVRL在推理任务上显著优于现有方法,提升高达12.4%。
📝 摘要(中文)
强化学习在语言模型推理方面取得了显著进展,但受到可验证奖励的限制。最近的无验证器强化学习方法通过利用LLM生成参考答案的概率作为奖励信号来解决这一限制。然而,这些方法通常仅根据问题来采样推理轨迹,导致推理轨迹采样与答案信息解耦,造成低效探索和轨迹与最终答案之间的不一致。本文提出了耦合变分强化学习(CoVRL),通过混合采样策略耦合先验和后验分布,从而桥接变分推理和强化学习。通过构建和优化集成这两个分布的复合分布,CoVRL能够实现高效探索,同时保持强大的思想-答案一致性。在数学和通用推理基准上的大量实验表明,CoVRL比基础模型提高了12.4%的性能,并且比最先进的无验证器强化学习基线额外提高了2.3%,为增强语言模型的通用推理能力提供了一个原则性框架。
🔬 方法详解
问题定义:论文旨在解决语言模型在通用推理任务中,使用强化学习方法时面临的探索效率低和推理轨迹与最终答案不一致的问题。现有方法要么依赖于外部验证器提供奖励信号,限制了应用场景;要么使用无验证器的方法,但这些方法通常只基于问题采样推理轨迹,忽略了答案信息,导致探索效率低下,并且推理过程与最终答案缺乏内在联系。
核心思路:论文的核心思路是通过耦合变分推理和强化学习,利用变分推理生成高质量的推理轨迹,并利用强化学习优化策略,从而实现高效的探索和推理。具体来说,通过构建一个复合分布,该分布结合了基于问题的先验分布和基于答案的后验分布,从而在采样推理轨迹时同时考虑问题和答案信息,保证推理过程的连贯性。
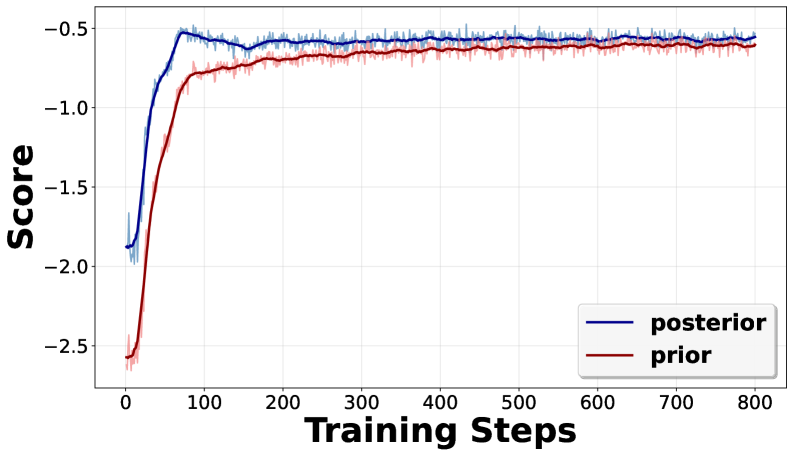
技术框架:CoVRL的整体框架包含以下几个主要模块:1) 先验分布建模:使用语言模型对给定问题生成推理轨迹的概率进行建模。2) 后验分布建模:使用语言模型对给定问题和答案生成推理轨迹的概率进行建模。3) 复合分布构建:将先验分布和后验分布进行加权组合,得到一个复合分布。4) 策略优化:使用强化学习算法(如Policy Gradient)优化策略,目标是最大化复合分布下的期望奖励。5) 混合采样:从复合分布中采样推理轨迹,用于训练强化学习模型。
关键创新:论文最关键的创新点在于提出了耦合变分推理和强化学习的框架,通过构建复合分布,将问题和答案信息融入到推理轨迹的采样过程中,从而解决了现有方法中推理轨迹与答案信息解耦的问题。与现有方法相比,CoVRL能够更有效地探索推理空间,并生成更连贯的推理轨迹。
关键设计:CoVRL的关键设计包括:1) 混合采样策略:通过调整先验分布和后验分布的权重,控制探索的程度和推理的连贯性。2) 奖励函数设计:使用语言模型生成参考答案的概率作为奖励信号,鼓励模型生成更接近正确答案的推理轨迹。3) 损失函数设计:除了强化学习的策略梯度损失外,还引入了变分推理的KL散度损失,用于约束后验分布接近先验分布,防止模型过度拟合答案信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CoVRL在数学和通用推理基准上显著优于现有方法。具体来说,CoVRL比基础模型提高了12.4%的性能,并且比最先进的无验证器强化学习基线额外提高了2.3%。这些结果表明,CoVRL能够有效地提升语言模型的推理能力,并为无验证器强化学习提供了一个有前景的方向。
🎯 应用场景
该研究成果可应用于各种需要复杂推理的自然语言处理任务,例如数学问题求解、常识推理、知识图谱推理等。通过提升语言模型的推理能力,可以改善智能客服、智能问答、机器翻译等应用的性能,并为开发更强大的通用人工智能系统奠定基础。未来,该方法还可以扩展到其他模态,例如视觉推理和多模态推理。
📄 摘要(原文)
While reinforcement learning has achieved impressive progress in language model reasoning, it is constrained by the requirement for verifiable rewards. Recent verifier-free RL methods address this limitation by utilizing the probabilities that LLMs generate reference answers as reward signals. However, these approaches typically sample reasoning traces conditioned only on the question. This design decouples reasoning-trace sampling from answer information, leading to inefficient exploration and incoherence between traces and final answers. In this paper, we propose \textit{\b{Co}upled \b{V}ariational \b{R}einforcement \b{L}earning} (CoVRL), which bridges variational inference and reinforcement learning by coupling prior and posterior distributions through a hybrid sampling strategy. By constructing and optimizing a composite distribution that integrates these two distributions, CoVRL enables efficient exploration while preserving strong thought-answer coherence. Extensive experiments on mathematical and general reasoning benchmarks show that CoVRL improves performance by 12.4\% over the base model and achieves an additional 2.3\% improvement over state-of-the-art verifier-free RL baselines, providing a principled framework for enhancing the general reasoning capabilities of language models.