HyperEdit: Unlocking Instruction-based Text Editing in LLMs via Hypernetworks
作者: Yiming Zeng, Jinghan Cao, Zexin Li, Wanhao Yu, Zhankai Ye, Dawei Xiang, Ting Hua, Xin Liu, Shangqian Gao, Tingting Yu
分类: cs.CL, cs.LG
发布日期: 2025-12-14
💡 一句话要点
HyperEdit:通过超网络解锁LLM中基于指令的文本编辑能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本编辑 大型语言模型 超网络 指令遵循 差异感知正则化
📋 核心要点
- 现有LLM在基于指令的文本编辑中,难以兼顾指令遵循和内容保持,容易过度编辑或未能准确实现编辑意图。
- HyperEdit通过超网络动态生成参数,使模型能根据指令调整编辑策略,并采用差异感知正则化避免过度编辑。
- 实验表明,HyperEdit在3B参数规模下,相比现有方法在编辑区域的BLEU得分提升9%-30%,效果显著。
📝 摘要(中文)
基于指令的文本编辑在代码编辑器等实际应用中日益重要,但大型语言模型(LLM)在该任务上仍然表现不佳。与自由文本生成不同,编辑需要忠实地执行用户指令,同时保留未更改的内容,因为即使是微小的意外修改也可能破坏功能。现有方法将编辑视为通用文本生成,导致两个主要问题:难以忠实地将编辑与不同的用户意图对齐,并且经常过度编辑未更改的区域。我们提出了HyperEdit来解决这两个问题。首先,我们引入了基于超网络的动态适配,生成特定于请求的参数,使模型能够根据每个指令定制其编辑策略。其次,我们开发了差异感知正则化,将监督集中在修改后的跨度上,防止过度编辑,同时确保精确、最小的更改。HyperEdit在修改区域上的BLEU得分比最先进的基线提高了9%--30%,尽管只使用了3B参数。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在基于指令的文本编辑任务中的不足。现有方法通常将编辑视为一般的文本生成,导致两个主要问题:一是难以准确理解并执行用户指令,无法很好地对齐编辑意图;二是容易过度编辑,不必要地修改了原本不需要修改的部分,破坏文本的完整性和功能性。
核心思路:HyperEdit的核心思路是使模型能够根据不同的指令动态调整其编辑策略,并专注于修改需要修改的部分,同时尽可能保留未修改部分的内容。通过引入超网络和差异感知正则化来实现这一目标。超网络负责生成特定于当前指令的参数,从而实现动态调整;差异感知正则化则引导模型关注修改区域,避免过度编辑。
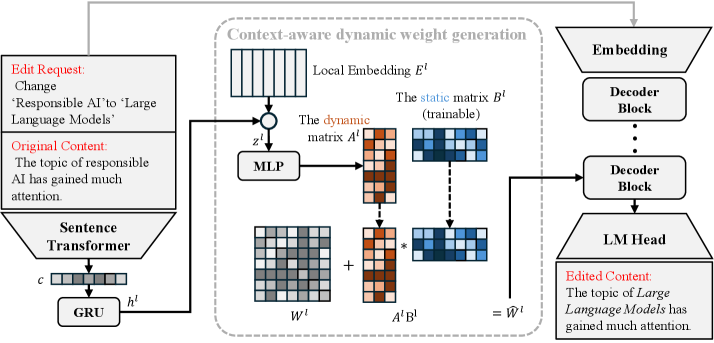
技术框架:HyperEdit的整体框架包含两个主要组成部分:1) 基于超网络的动态参数生成模块:该模块接收输入文本和编辑指令,通过超网络生成主模型的参数。超网络是一个小型神经网络,其输入是指令的嵌入表示,输出是主模型(LLM)的权重。2) 差异感知正则化模块:该模块通过损失函数的设计,引导模型关注修改区域,减少对未修改区域的干扰。
关键创新:HyperEdit的关键创新在于:1) 使用超网络动态生成模型参数,使得模型能够根据不同的指令自适应地调整编辑策略,而不是使用固定的参数进行编辑。2) 引入差异感知正则化,通过损失函数的设计,显式地引导模型关注需要修改的区域,从而避免过度编辑。
关键设计:1) 超网络结构:超网络采用小型Transformer结构,输入是指令的嵌入表示,输出是主模型的权重。2) 差异感知正则化损失函数:该损失函数包含两部分:一部分是标准的交叉熵损失,用于监督模型生成正确的编辑结果;另一部分是正则化项,用于惩罚对未修改区域的过度编辑。具体来说,该正则化项计算模型输出与原始文本在未修改区域的差异,并将其作为惩罚项加入总损失中。
🖼️ 关键图片
📊 实验亮点
HyperEdit在基于指令的文本编辑任务上取得了显著的性能提升。实验结果表明,在修改区域的BLEU得分上,HyperEdit相比最先进的基线方法提升了9%-30%,证明了其在准确性和指令遵循方面的优势。值得注意的是,HyperEdit仅使用了3B参数,相比于更大的模型,具有更高的效率和可部署性。
🎯 应用场景
HyperEdit具有广泛的应用前景,例如在代码编辑器中,可以根据用户的自然语言指令修改代码,提高开发效率。在文档编辑中,可以根据指令进行文本润色、语法纠错等操作。此外,还可以应用于机器翻译、文本摘要等领域,提升生成文本的质量和可控性。该研究有助于推动人机交互的发展,使得用户能够更自然、更高效地与机器进行沟通。
📄 摘要(原文)
Instruction-based text editing is increasingly critical for real-world applications such as code editors (e.g., Cursor), but Large Language Models (LLMs) continue to struggle with this task. Unlike free-form generation, editing requires faithfully implementing user instructions while preserving unchanged content, as even minor unintended modifications can break functionality. Existing approaches treat editing as generic text generation, leading to two key failures: they struggle to faithfully align edits with diverse user intents, and they often over-edit unchanged regions. We propose HyperEdit to address both issues. First, we introduce hypernetwork-based dynamic adaptation that generates request-specific parameters, enabling the model to tailor its editing strategy to each instruction. Second, we develop difference-aware regularization that focuses supervision on modified spans, preventing over-editing while ensuring precise, minimal changes. HyperEdit achieves a 9%--30% relative improvement in BLEU on modified regions over state-of-the-art baselines, despite utilizing only 3B parameters.