SCIR: A Self-Correcting Iterative Refinement Framework for Enhanced Information Extraction Based on Schema
作者: Yushen Fang, Jianjun Li, Mingqian Ding, Chang Liu, Xinchi Zou, Wenqi Yang
分类: cs.CL, cs.AI
发布日期: 2025-12-13
💡 一句话要点
提出SCIR框架,通过自校正迭代优化提升信息抽取性能并降低训练成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息抽取 自校正 迭代优化 大型语言模型 低成本训练
📋 核心要点
- 现有微调范式训练成本高昂,且难以与大型语言模型(LLM)的偏好对齐。
- SCIR框架通过双路径自校正和反馈优化,实现与LLM和IE系统的即插即用兼容。
- 实验表明,SCIR在信息抽取任务上显著优于现有方法,并大幅降低了训练成本。
📝 摘要(中文)
本文提出了一种新颖的通用信息抽取(IE)范式,即自校正迭代优化(SCIR)框架,以及一个包含超过10万条数据的多任务双语(中英文)自校正(MBSC)数据集。SCIR框架通过其双路径自校正模块和反馈驱动的优化,实现了与现有LLM和IE系统的即插即用兼容性,从而显著降低了训练成本。同时,MBSC数据集通过间接将GPT-4的能力提炼到IE结果检测模型中,解决了偏好对齐的挑战。实验结果表明,SCIR在命名实体识别、关系抽取和事件抽取这三个关键任务上优于最先进的IE方法,在基于span的Micro-F1上平均提高了5.27%,同时与基线方法相比,训练成本降低了87%。这些进步不仅提高了IE系统的灵活性和准确性,而且为轻量级和高效的IE范式铺平了道路。
🔬 方法详解
问题定义:现有基于大型语言模型的信息抽取系统面临两个主要问题:一是微调训练成本过高,二是难以使模型输出与大型语言模型的偏好对齐,导致抽取结果不准确。这些问题限制了信息抽取系统的实际应用。
核心思路:论文的核心思路是通过自校正迭代优化来提升信息抽取性能,同时降低训练成本。具体来说,利用一个轻量级的自校正模块来纠正初始抽取结果,并通过反馈机制不断优化抽取过程,从而逐步逼近理想的抽取结果。这种迭代优化的方式可以有效利用大型语言模型的知识,同时避免了昂贵的微调过程。
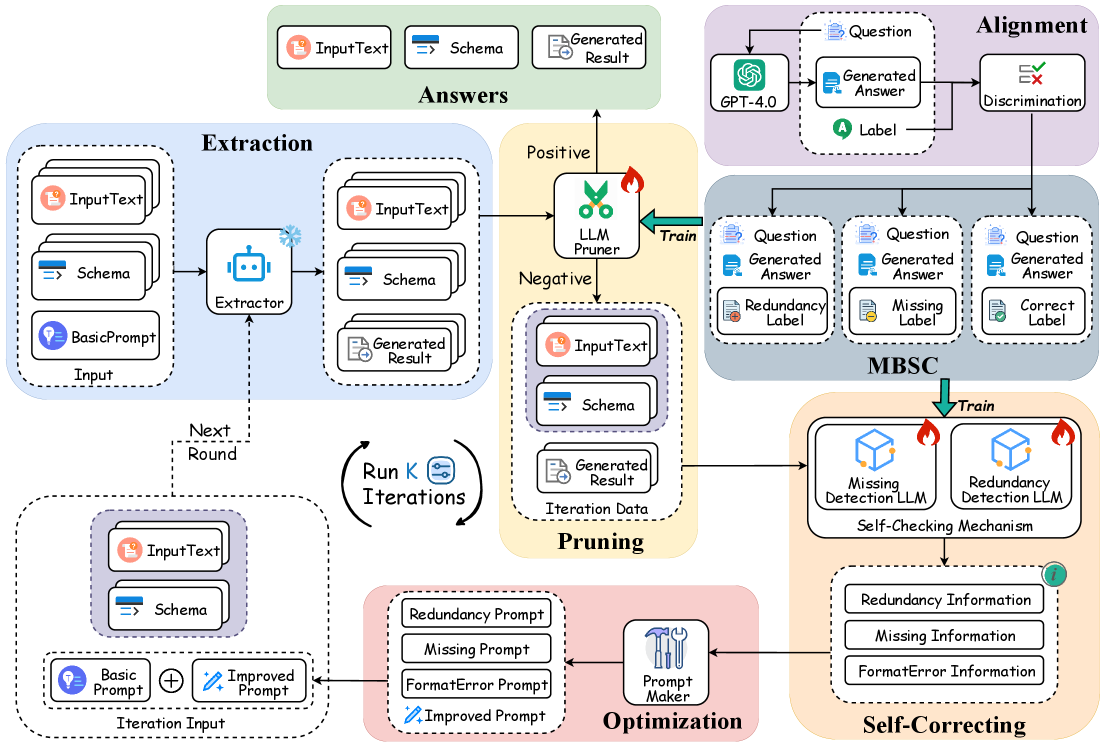
技术框架:SCIR框架包含两个主要模块:双路径自校正模块和反馈驱动优化模块。双路径自校正模块同时利用原始输入和初始抽取结果进行自校正,提高校正的准确性。反馈驱动优化模块则根据校正结果调整抽取策略,实现迭代优化。整个框架可以与现有的LLM和IE系统无缝集成,实现即插即用。
关键创新:SCIR框架的关键创新在于其自校正迭代优化的思想。与传统的微调方法不同,SCIR不需要对整个大型语言模型进行微调,而是通过一个轻量级的自校正模块来逐步优化抽取结果。这种方法不仅降低了训练成本,而且提高了抽取的准确性和鲁棒性。此外,MBSC数据集的构建也为解决偏好对齐问题提供了新的思路。
关键设计:双路径自校正模块的设计是关键。它同时考虑了原始输入和初始抽取结果,利用上下文信息进行更准确的校正。反馈驱动优化模块则通过调整抽取策略,例如调整抽取概率阈值或修改抽取规则,来实现迭代优化。具体的参数设置和网络结构细节在论文中进行了详细描述,但此处未知。
🖼️ 关键图片

📊 实验亮点
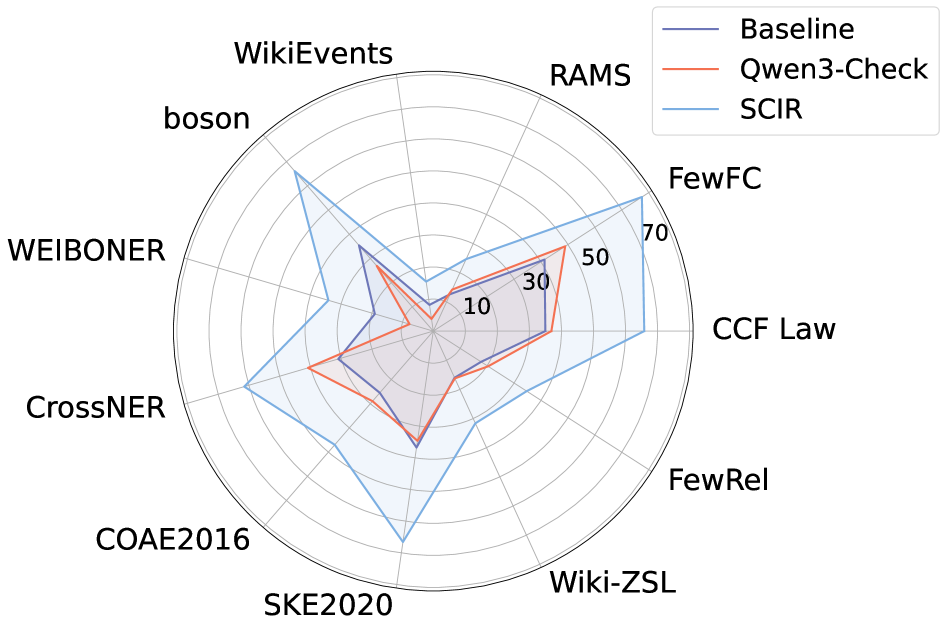
实验结果表明,SCIR框架在命名实体识别、关系抽取和事件抽取三个任务上均取得了显著的性能提升,平均F1值提高了5.27%。同时,与传统的微调方法相比,SCIR框架的训练成本降低了87%。这些结果表明,SCIR框架在提升信息抽取性能的同时,显著降低了训练成本,具有很强的实用价值。
🎯 应用场景
该研究成果可广泛应用于各种信息抽取场景,例如新闻事件抽取、金融风险分析、医疗信息挖掘等。通过提升信息抽取的准确性和效率,可以帮助人们更好地理解和利用海量信息,为决策提供支持。未来,该框架有望扩展到更多自然语言处理任务中,例如文本摘要、机器翻译等。
📄 摘要(原文)
Although Large language Model (LLM)-powered information extraction (IE) systems have shown impressive capabilities, current fine-tuning paradigms face two major limitations: high training costs and difficulties in aligning with LLM preferences. To address these issues, we propose a novel universal IE paradigm, the Self-Correcting Iterative Refinement (SCIR) framework, along with a Multi-task Bilingual (Chinese-English) Self-Correcting (MBSC) dataset containing over 100,000 entries. The SCIR framework achieves plug-and-play compatibility with existing LLMs and IE systems through its Dual-Path Self-Correcting module and feedback-driven optimization, thereby significantly reducing training costs. Concurrently, the MBSC dataset tackles the challenge of preference alignment by indirectly distilling GPT-4's capabilities into IE result detection models. Experimental results demonstrate that SCIR outperforms state-of-the-art IE methods across three key tasks: named entity recognition, relation extraction, and event extraction, achieving a 5.27 percent average improvement in span-based Micro-F1 while reducing training costs by 87 percent compared to baseline approaches. These advancements not only enhance the flexibility and accuracy of IE systems but also pave the way for lightweight and efficient IE paradigms.