BLASST: Dynamic BLocked Attention Sparsity via Softmax Thresholding
作者: Jiayi Yuan, Cameron Shinn, Kai Xu, Jingze Cui, George Klimiashvili, Guangxuan Xiao, Perkz Zheng, Bo Li, Yuxin Zhou, Zhouhai Ye, Weijie You, Tian Zheng, Dominic Brown, Pengbo Wang, Richard Cai, Julien Demouth, John D. Owens, Xia Hu, Song Han, Timmy Liu, Huizi Mao
分类: cs.CL
发布日期: 2025-12-12
💡 一句话要点
BLASST:通过Softmax阈值动态剪枝Attention矩阵,加速长文本LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏注意力 长文本推理 大型语言模型 动态剪枝 Softmax阈值
📋 核心要点
- 现有注意力机制在处理长文本时面临计算和内存瓶颈,限制了大型语言模型的推理能力。
- BLASST通过softmax阈值动态剪枝不重要的注意力权重,减少计算量和内存访问,无需额外预计算。
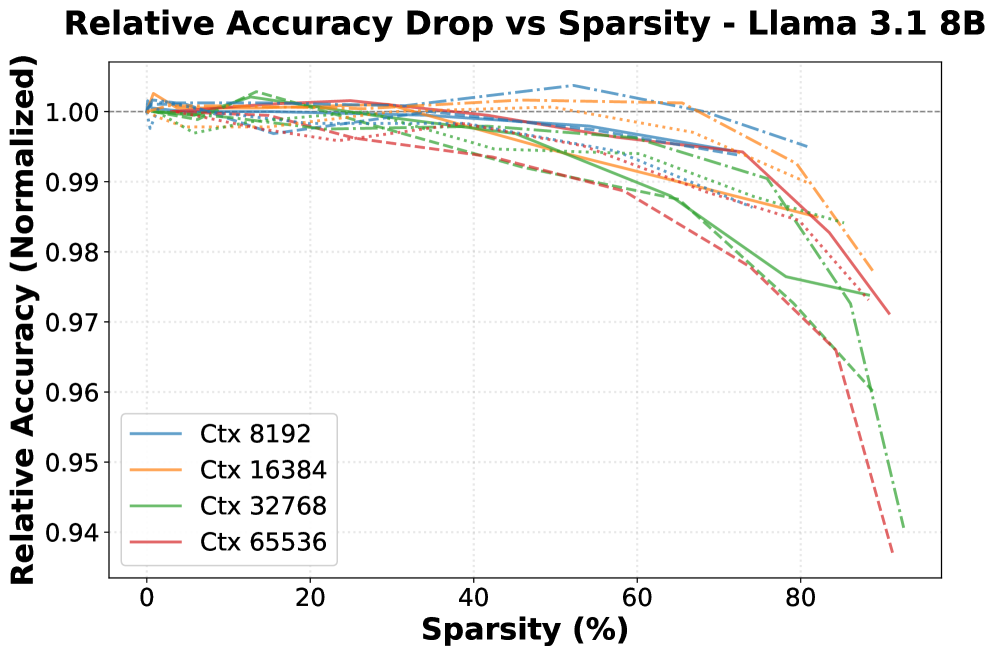
- 实验表明,BLASST在保持高精度的情况下,显著加速了预填充和解码阶段,并可进一步通过稀疏感知训练提升性能。
📝 摘要(中文)
针对大型语言模型(LLM)中日益增长的长上下文推理需求带来的计算和内存瓶颈,我们提出了BLASST,一种即插即用的稀疏注意力方法,无需预计算或代理分数即可动态剪枝注意力矩阵。我们的方法使用固定阈值和在线softmax的现有信息来识别可忽略的注意力分数,从而跳过softmax计算、Value块加载和后续的矩阵乘法。这种方法可以无缝集成到现有的FlashAttention内核设计中,且延迟开销可忽略不计。该方法适用于所有注意力变体(MHA、GQA、MQA和MLA)的预填充和解码阶段,为加速长上下文推理提供了一个统一的解决方案。我们开发了一种自动校准程序,揭示了最佳阈值与上下文长度之间简单的反比关系,从而能够在各种场景中实现稳健的部署。在保持高精度的前提下,我们证明了在现代GPU上,预填充阶段的速度提升了1.62倍(稀疏度为74.7%),解码阶段的速度提升了1.48倍(稀疏度为73.2%)。此外,我们探索了稀疏感知训练作为一种自然扩展,表明模型可以通过训练变得对稀疏注意力模式具有更强的鲁棒性,从而进一步推进精度-稀疏度边界。
🔬 方法详解
问题定义:大型语言模型在处理长文本时,标准的Attention机制面临着计算复杂度和内存消耗的挑战。具体来说,需要计算所有token之间的Attention权重,并加载所有Value块,这在长文本场景下变得非常耗时和耗资源。现有的稀疏Attention方法通常需要预计算或代理分数来估计Attention权重的重要性,引入了额外的计算开销和复杂性。
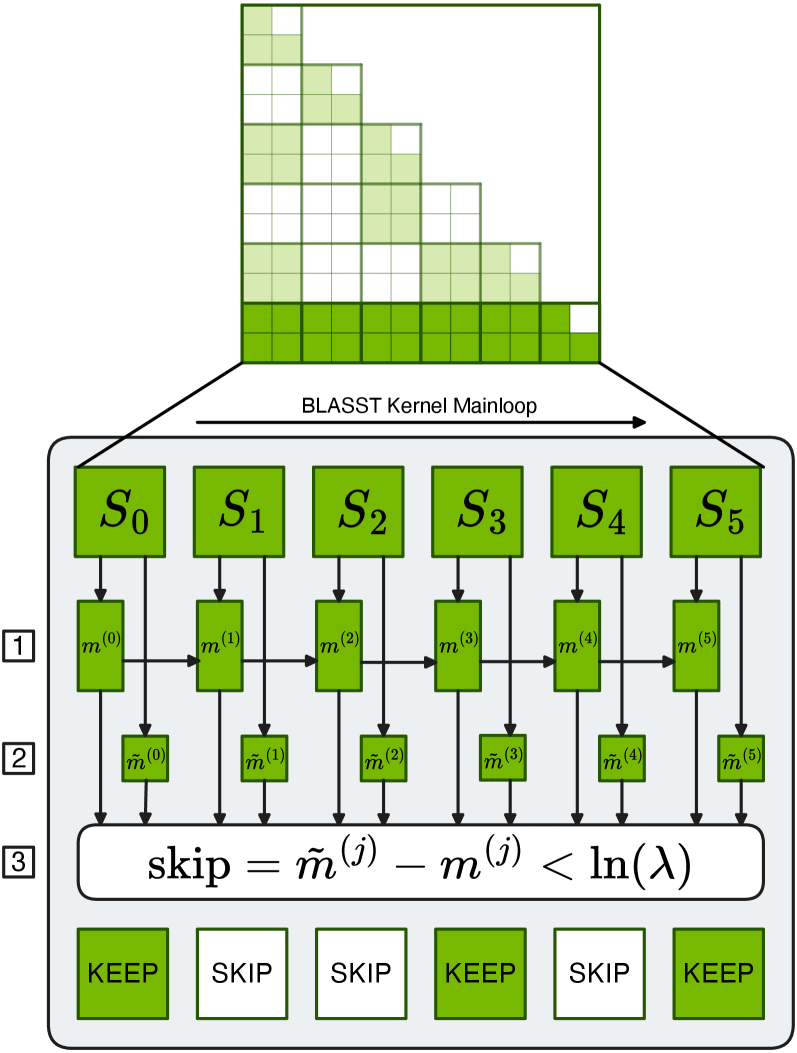
核心思路:BLASST的核心思路是利用softmax函数本身的特性,通过设置一个固定的阈值,直接从softmax的输出中识别出可以忽略的Attention权重。这些权重对应的计算和内存访问可以被安全地跳过,从而加速Attention计算过程。这种方法无需额外的预计算或代理分数,降低了计算开销。
技术框架:BLASST方法可以无缝集成到现有的FlashAttention内核设计中。整体流程如下:首先,计算标准的Attention权重;然后,应用softmax函数;接着,将softmax的输出与预设的阈值进行比较,低于阈值的权重被认为是可忽略的,并被设置为零;最后,只对剩余的非零权重进行后续的Value块加载和矩阵乘法。该方法适用于MHA、GQA、MQA和MLA等多种Attention变体,以及预填充和解码阶段。
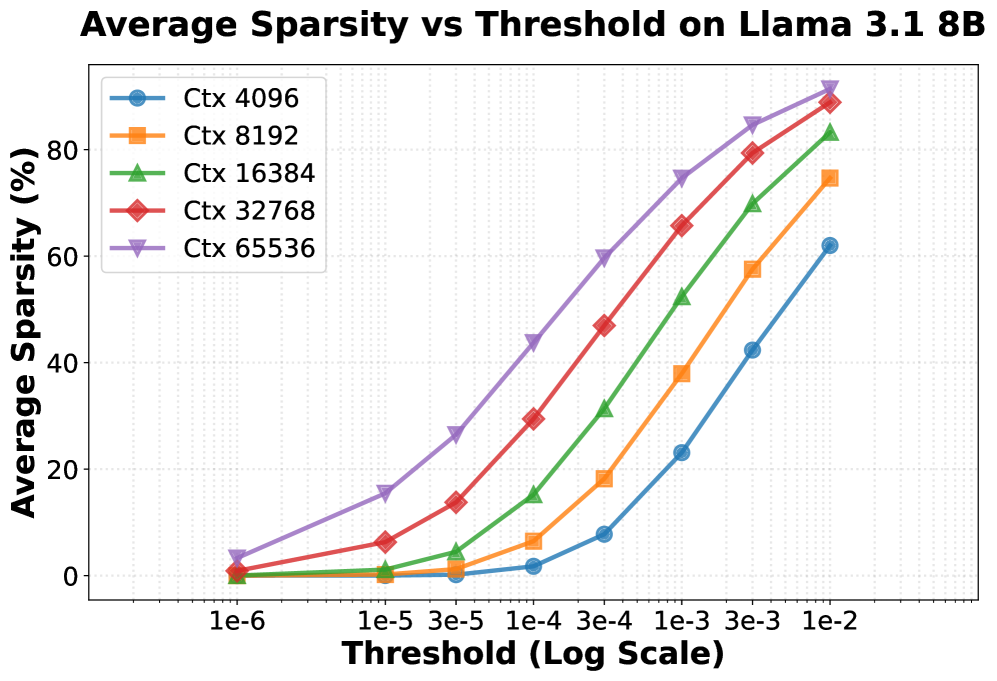
关键创新:BLASST的关键创新在于动态地、在线地剪枝Attention矩阵,而无需任何预计算或代理分数。它直接利用softmax的输出来判断Attention权重的重要性,避免了额外的计算开销。此外,BLASST还提出了一种自动校准程序,用于确定最佳的阈值,该阈值与上下文长度之间存在简单的反比关系,从而能够在不同的场景中实现鲁棒的部署。
关键设计:BLASST的关键设计包括:1) 使用固定的阈值来剪枝Attention权重;2) 开发自动校准程序来确定最佳阈值;3) 将该方法集成到现有的FlashAttention内核设计中,以减少延迟开销;4) 探索稀疏感知训练,以进一步提高模型的稀疏度和精度。
🖼️ 关键图片
📊 实验亮点
BLASST在现代GPU上实现了显著的加速效果。在预填充阶段,BLASST在74.7%的稀疏度下实现了1.62倍的速度提升。在解码阶段,BLASST在73.2%的稀疏度下实现了1.48倍的速度提升。这些结果表明,BLASST可以在保持高精度的前提下,显著加速长文本推理。此外,稀疏感知训练可以进一步提高模型的稀疏度和精度。
🎯 应用场景
BLASST可应用于各种需要处理长文本的自然语言处理任务,例如长文档摘要、机器翻译、问答系统和代码生成等。通过加速长文本推理,BLASST可以降低计算成本,提高模型响应速度,并支持更大规模的语言模型部署。该方法还有助于在资源受限的设备上运行大型语言模型,例如移动设备和边缘设备。
📄 摘要(原文)
The growing demand for long-context inference capabilities in Large Language Models (LLMs) has intensified the computational and memory bottlenecks inherent to the standard attention mechanism. To address this challenge, we introduce BLASST, a drop-in sparse attention method that dynamically prunes the attention matrix without any pre-computation or proxy scores. Our method uses a fixed threshold and existing information from online softmax to identify negligible attention scores, skipping softmax computation, Value block loading, and the subsequent matrix multiplication. This fits seamlessly into existing FlashAttention kernel designs with negligible latency overhead. The approach is applicable to both prefill and decode stages across all attention variants (MHA, GQA, MQA, and MLA), providing a unified solution for accelerating long-context inference. We develop an automated calibration procedure that reveals a simple inverse relationship between optimal threshold and context length, enabling robust deployment across diverse scenarios. Maintaining high accuracy, we demonstrate a 1.62x speedup for prefill at 74.7% sparsity and a 1.48x speedup for decode at 73.2% sparsity on modern GPUs. Furthermore, we explore sparsity-aware training as a natural extension, showing that models can be trained to be inherently more robust to sparse attention patterns, pushing the accuracy-sparsity frontier even further.