VOYAGER: A Training Free Approach for Generating Diverse Datasets using LLMs
作者: Avinash Amballa, Yashas Malur Saidutta, Chi-Heng Lin, Vivek Kulkarni, Srinivas Chappidi
分类: cs.CL, cs.LG
发布日期: 2025-12-12
备注: Arxiv Submission
💡 一句话要点
VOYAGER:一种利用LLM生成多样化数据集的免训练方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数据集生成 数据多样性 行列式点过程 免训练方法
📋 核心要点
- 现有方法利用LLM生成数据集时,数据多样性不足,限制了下游模型的泛化能力。
- Voyager通过迭代优化行列式点过程,直接最大化数据集的多样性,无需额外训练。
- 实验表明,Voyager在数据集多样性方面显著优于现有基线方法,提升幅度达1.5-3倍。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地被用于生成合成数据集,以评估和训练下游模型。然而,先前的工作指出,这种生成的数据缺乏多样性。在本文中,我们提出了一种新颖的、有原则的方法Voyager,用于生成多样化的数据集。我们的方法是迭代的,并直接优化一个数学量,该数学量使用行列式点过程的机制来优化数据集的多样性。此外,我们的方法是免训练的,适用于闭源模型,并且可扩展。除了为我们方法的工作原理提供理论依据外,我们还通过全面的实验证明,Voyager显著优于流行的基线方法,在多样性方面提供了1.5-3倍的改进。
🔬 方法详解
问题定义:论文旨在解决使用大型语言模型(LLMs)生成合成数据集时,数据多样性不足的问题。现有的基于LLM的数据生成方法往往产生相似的样本,缺乏覆盖真实数据分布的能力,从而限制了下游模型训练的效果和泛化能力。
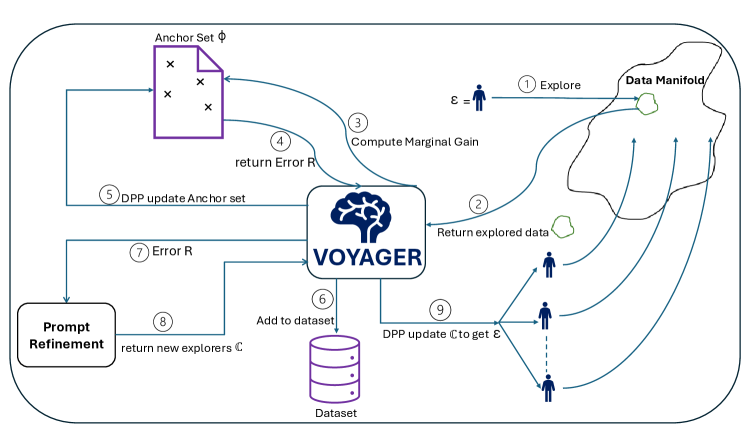
核心思路:Voyager的核心思路是利用行列式点过程(Determinantal Point Processes, DPPs)来建模数据集的多样性。DPPs能够有效地选择具有代表性和多样性的样本子集。通过迭代地从LLM生成的数据中选择样本,并最大化DPP定义的概率,从而生成一个多样性高的数据集。
技术框架:Voyager的整体流程如下:1. 使用LLM生成初始数据集。2. 利用DPP计算数据集中每个样本的多样性得分。3. 根据多样性得分选择一部分样本加入最终数据集。4. 基于已选样本,调整LLM的prompt,生成新的样本。5. 重复步骤2-4,直到数据集达到预定大小。
关键创新:Voyager的关键创新在于将DPP与LLM结合,实现了一种免训练的数据集多样性优化方法。与需要额外训练或微调LLM的方法不同,Voyager可以直接应用于现有的闭源LLM,具有更强的通用性和易用性。此外,Voyager通过迭代的方式逐步构建数据集,能够更好地控制数据集的多样性和质量。
关键设计:Voyager的关键设计包括:1. 使用余弦相似度来衡量样本之间的相似性,构建DPP的核矩阵。2. 设计了一种基于贪心算法的样本选择策略,以高效地最大化DPP的概率。3. 通过调整LLM的prompt,引导LLM生成与已选样本不同的新样本,从而进一步提高数据集的多样性。
🖼️ 关键图片
📊 实验亮点
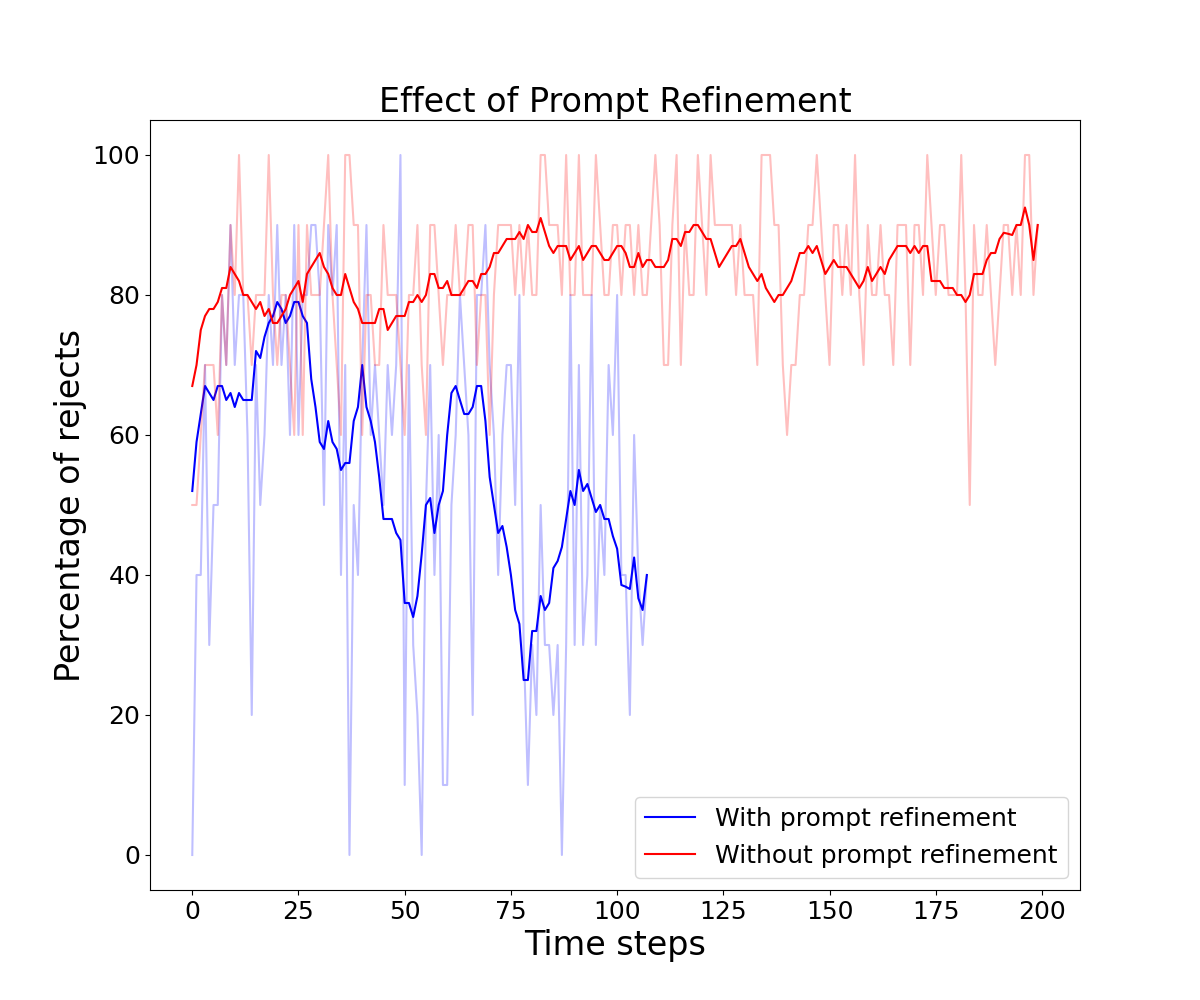
实验结果表明,Voyager在多个数据集上显著优于现有的数据生成方法。具体而言,Voyager生成的数据集在多样性方面提升了1.5-3倍,并且能够有效提升下游模型的性能。例如,在使用Voyager生成的数据集训练图像分类模型时,模型的准确率得到了显著提升。
🎯 应用场景
Voyager可广泛应用于各种需要合成数据集的场景,例如:训练计算机视觉模型、自然语言处理模型、强化学习智能体等。该方法尤其适用于数据获取成本高昂或数据隐私敏感的领域。通过生成多样化的合成数据,可以有效提升模型的泛化能力和鲁棒性,降低对真实数据的依赖。
📄 摘要(原文)
Large language models (LLMs) are increasingly being used to generate synthetic datasets for the evaluation and training of downstream models. However, prior work has noted that such generated data lacks diversity. In this paper, we propose Voyager, a novel principled approach to generate diverse datasets. Our approach is iterative and directly optimizes a mathematical quantity that optimizes the diversity of the dataset using the machinery of determinantal point processes. Furthermore, our approach is training-free, applicable to closed-source models, and scalable. In addition to providing theoretical justification for the working of our method, we also demonstrate through comprehensive experiments that Voyager significantly outperforms popular baseline approaches by providing a 1.5-3x improvement in diversity.