Hold Onto That Thought: Assessing KV Cache Compression On Reasoning
作者: Minghui Liu, Aadi Palnitkar, Tahseen Rabbani, Hyunwoo Jae, Kyle Rui Sang, Dixi Yao, Shayan Shabihi, Fuheng Zhao, Tian Li, Ce Zhang, Furong Huang, Kunpeng Zhang
分类: cs.CL, cs.AI, cs.PF
发布日期: 2025-12-12
💡 一句话要点
针对长推理任务,评估KV缓存压缩算法对LLM性能的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 长推理任务 大型语言模型 解码阶段 H2O算法
📋 核心要点
- 现有KV缓存压缩算法主要针对预填充阶段,缺乏对长推理任务的有效评估。
- 论文提出解码增强版SnapKV,并对比多种压缩策略在推理任务上的性能。
- 实验表明H2O和解码增强版SnapKV在推理模型上表现突出,并揭示了缓存大小与推理成本的权衡。
📝 摘要(中文)
大型语言模型(LLMs)在长上下文任务中表现出色,但常受限于内存。KV缓存用于加速注意力计算,其大小随上下文长度线性增长。现有压缩算法通过移除不重要的token来缓解缓存增长,但多针对预填充阶段,即处理长提示上下文,且在长解码推理任务上的性能评估不足。本文评估了几种流行压缩策略在长推理任务上的性能。对于非推理模型Llama-3.1-8B-Instruct,没有单一策略适用于所有情况,性能受数据集类型影响。但H2O和本文提出的解码增强版SnapKV在推理模型上表现优异,表明重度追踪对推理轨迹的效用。此外,低预算下的驱逐策略可产生更长的推理轨迹,揭示了缓存大小和推理成本之间的权衡。
🔬 方法详解
问题定义:大型语言模型在处理长上下文推理任务时,KV缓存会线性增长,导致内存瓶颈。现有的KV缓存压缩算法主要针对预填充阶段,缺乏对长推理任务(例如需要多步推理和自我反思的GSM8K和MATH500)的有效评估,这些任务通常需要数千个token的推理序列。因此,如何有效地压缩KV缓存,同时保持甚至提升LLM在长推理任务中的性能,是一个亟待解决的问题。
核心思路:论文的核心思路是评估和优化现有的KV缓存压缩策略,使其更适用于长推理任务。特别地,论文关注于在解码阶段进行KV缓存压缩,并提出了一种解码增强版的SnapKV算法。通过实验分析不同压缩策略在推理任务上的表现,从而找到更适合推理场景的压缩方法。
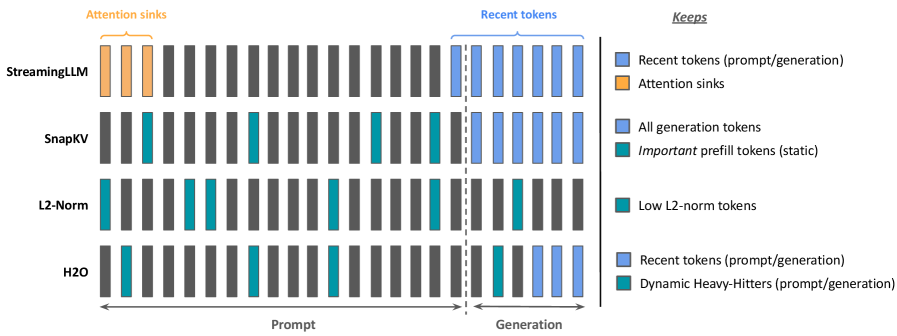
技术框架:论文的技术框架主要包括以下几个部分:1)选择一系列流行的KV缓存压缩策略,包括H2O、SnapKV等;2)构建长推理任务的评估基准,例如GSM8K和MATH500;3)提出解码增强版的SnapKV算法,使其更适用于解码阶段的KV缓存压缩;4)在不同的模型(如Llama-3.1-8B-Instruct)和数据集上进行实验,评估不同压缩策略的性能;5)分析实验结果,探讨缓存大小和推理成本之间的权衡。
关键创新:论文的关键创新点在于:1)首次系统性地评估了多种KV缓存压缩策略在长推理任务上的性能;2)提出了解码增强版的SnapKV算法,该算法在推理任务上表现优于原始的SnapKV算法;3)揭示了在低预算下,驱逐策略可以产生更长的推理轨迹,从而发现了缓存大小和推理成本之间的权衡。
关键设计:解码增强版SnapKV的关键设计在于,它在解码阶段也进行KV缓存的压缩,而不仅仅是在预填充阶段。具体来说,该算法会跟踪每个token的重要性,并根据其重要性来决定是否将其保留在KV缓存中。此外,论文还探索了不同的驱逐策略,例如基于token的注意力权重或频率等。具体的参数设置和损失函数等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
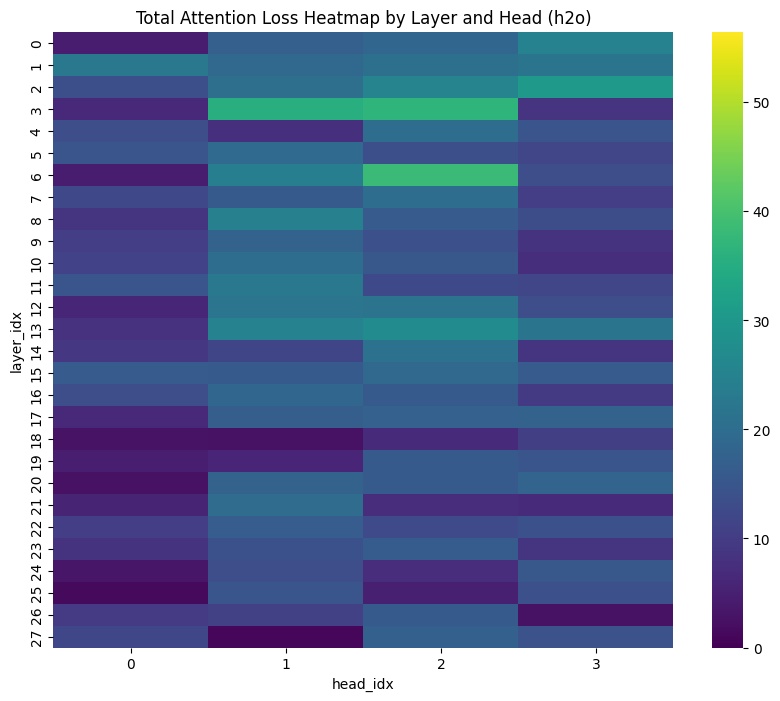
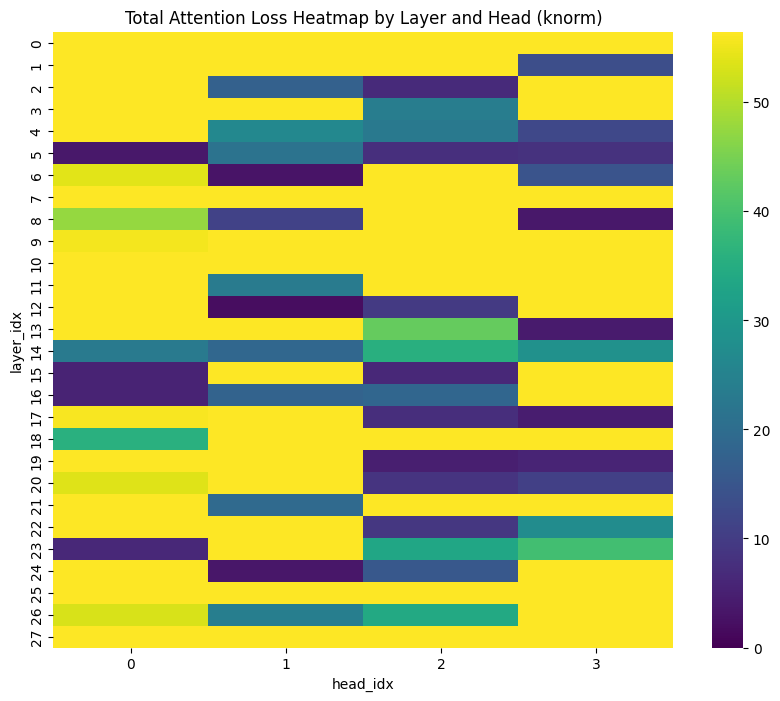
实验结果表明,对于非推理模型Llama-3.1-8B-Instruct,没有单一的压缩策略适用于所有数据集。然而,H2O和解码增强版的SnapKV在推理模型上表现优异。此外,研究发现,在低预算下,驱逐策略可以产生更长的推理轨迹,揭示了缓存大小和推理成本之间的权衡。具体性能提升数据未在摘要中给出,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要长上下文推理的场景,例如对话系统、代码生成、数学问题求解等。通过有效压缩KV缓存,可以降低LLM的内存需求,使其能够在资源受限的设备上运行,并提高推理效率。未来的研究可以进一步探索更高效的KV缓存压缩算法,以及如何根据不同的任务类型自动选择合适的压缩策略。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable performance on long-context tasks, but are often bottlenecked by memory constraints. Namely, the KV cache, which is used to significantly speed up attention computations, grows linearly with context length. A suite of compression algorithms has been introduced to alleviate cache growth by evicting unimportant tokens. However, several popular strategies are targeted towards the prefill phase, i.e., processing long prompt context, and their performance is rarely assessed on reasoning tasks requiring long decoding. In particular, short but complex prompts, such as those in benchmarks like GSM8K and MATH500, often benefit from multi-step reasoning and self-reflection, resulting in thinking sequences thousands of tokens long. In this work, we benchmark the performance of several popular compression strategies on long-reasoning tasks. For the non-reasoning Llama-3.1-8B-Instruct, we determine that no singular strategy fits all, and that performance is heavily influenced by dataset type. However, we discover that H2O and our decoding-enabled variant of SnapKV are dominant strategies for reasoning models, indicating the utility of heavy-hitter tracking for reasoning traces. We also find that eviction strategies at low budgets can produce longer reasoning traces, revealing a tradeoff between cache size and inference costs.