SUMFORU: An LLM-Based Review Summarization Framework for Personalized Purchase Decision Support
作者: Yuming Feng, Xinrui Jiang
分类: cs.CL
发布日期: 2025-12-12
备注: Code available at https://github.com/Harry20030331/SumForU
💡 一句话要点
SUMFORU:一种基于LLM的评论摘要框架,用于个性化购买决策支持
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 评论摘要 个性化推荐 LLM 知识蒸馏 强化学习 用户画像 自然语言处理
📋 核心要点
- 现有基于LLM的评论摘要方法缺乏个性化,无法有效支持用户决策,难以满足用户特定偏好。
- SUMFORU框架通过用户角色建模,利用非对称知识蒸馏和AI反馈强化学习,实现个性化摘要生成。
- 实验表明,SUMFORU在一致性、可信度和偏好对齐方面均优于现有方法,并能推广到新的产品类别。
📝 摘要(中文)
在线产品评论包含丰富但嘈杂的信号,这让用户感到不知所措,并阻碍了有效的决策。现有的基于LLM的摘要器仍然是通用的,并且未能考虑个人偏好,从而限制了它们的实际效用。我们提出了SUMFORU,一个可控的评论摘要框架,该框架将输出与显式的用户角色对齐,以支持个性化的购买决策。我们的方法整合了一个高质量的数据管道(构建自Amazon 2023 Review Dataset)和一个两阶段的对齐过程:(1)通过非对称知识蒸馏进行角色感知的监督微调(SFT),以及(2)使用AI反馈的强化学习(RLAIF),利用偏好估计器来捕获细粒度的、与角色相关的信号。我们在基于规则的、基于LLM的和以人为中心的指标上评估了该模型,证明了在一致性、可信度和偏好对齐方面的持续改进。我们的框架在所有评估设置中都实现了最高的性能,并且可以有效地推广到未见过的产品类别。我们的结果突出了可控的多元对齐在构建下一代个性化决策支持系统中的前景。
🔬 方法详解
问题定义:论文旨在解决在线产品评论信息过载,以及现有LLM摘要方法无法提供个性化购买决策支持的问题。现有方法生成的摘要通常是通用的,忽略了用户的特定偏好,导致用户难以从中提取有用的信息。
核心思路:论文的核心思路是构建一个可控的评论摘要框架,该框架能够根据用户的角色(persona)生成个性化的摘要。通过将用户偏好融入到摘要生成过程中,使得生成的摘要更符合用户的需求,从而更好地支持用户的购买决策。
技术框架:SUMFORU框架包含两个主要阶段:(1) 角色感知的监督微调(SFT):利用非对称知识蒸馏,将通用LLM的知识迁移到角色特定的LLM上。(2) 使用AI反馈的强化学习(RLAIF):使用偏好估计器来捕获细粒度的、与角色相关的信号,并利用强化学习进一步优化摘要生成策略。整个流程从Amazon 2023 Review Dataset构建高质量的数据管道开始,最终输出个性化的摘要。
关键创新:该论文的关键创新在于提出了一个可控的多元对齐框架,能够根据用户的角色生成个性化的摘要。通过结合非对称知识蒸馏和AI反馈强化学习,有效地将用户偏好融入到摘要生成过程中。此外,使用偏好估计器来捕获细粒度的用户偏好信号也是一个重要的创新点。
关键设计:在SFT阶段,使用了非对称知识蒸馏,这意味着教师模型(通用LLM)和学生模型(角色特定的LLM)的结构可能不同。在RLAIF阶段,偏好估计器的设计至关重要,需要能够准确地评估摘要与用户角色之间的匹配程度。损失函数的设计也需要考虑如何平衡一致性、可信度和偏好对齐这三个目标。
🖼️ 关键图片
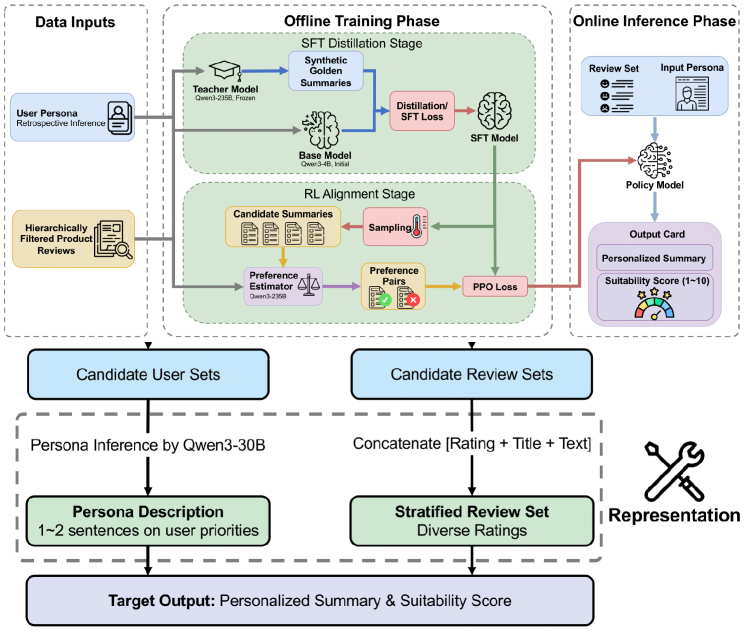
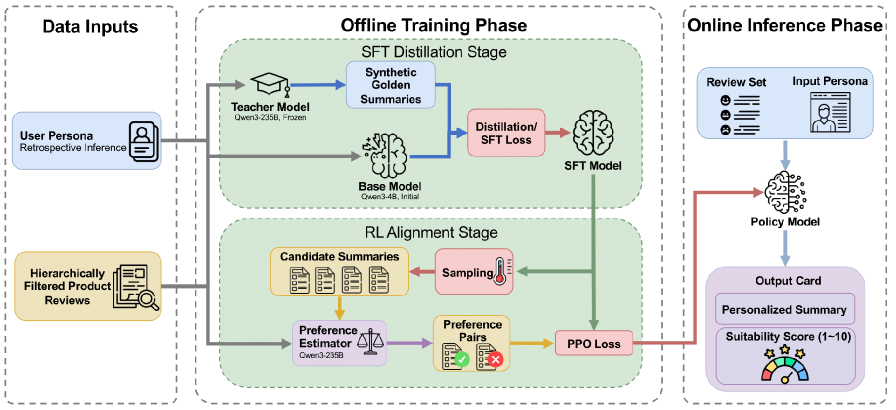
📊 实验亮点
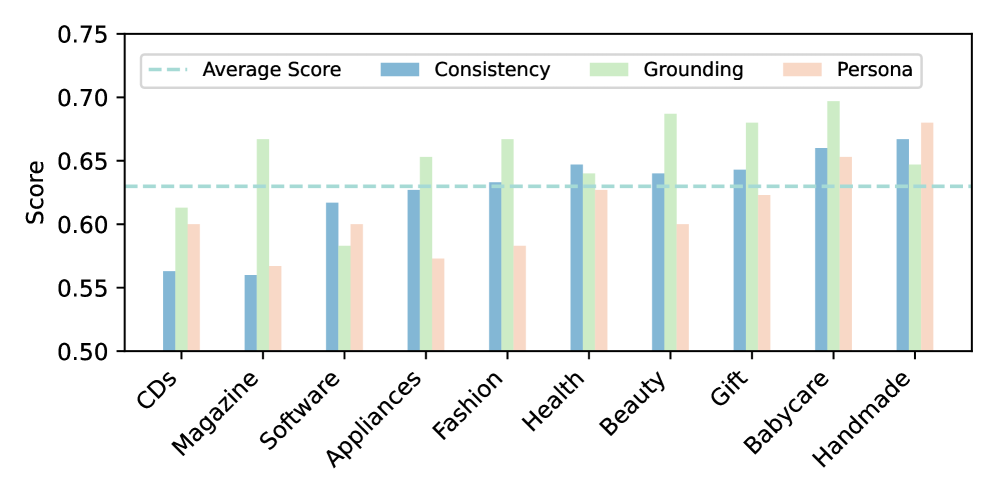
实验结果表明,SUMFORU框架在一致性、可信度和偏好对齐方面均优于现有方法。具体而言,SUMFORU在各项指标上都取得了显著提升,并且能够有效地推广到未见过的产品类别,证明了其良好的泛化能力。该框架在所有评估设置中都实现了最高的性能。
🎯 应用场景
该研究成果可应用于电商平台、产品推荐系统等领域,为用户提供个性化的产品评论摘要,帮助用户快速了解产品特点,提高购买决策效率。未来,该技术可扩展到其他领域,如新闻摘要、文档摘要等,为用户提供更高效的信息获取方式。
📄 摘要(原文)
Online product reviews contain rich but noisy signals that overwhelm users and hinder effective decision-making. Existing LLM-based summarizers remain generic and fail to account for individual preferences, limiting their practical utility. We propose SUMFORU, a steerable review summarization framework that aligns outputs with explicit user personas to support personalized purchase decisions. Our approach integrates a high-quality data pipeline built from the Amazon 2023 Review Dataset with a two-stage alignment procedure: (1) persona-aware Supervised Fine-Tuning (SFT) via asymmetric knowledge distillation, and (2) Reinforcement Learning with AI Feedback (RLAIF) using a preference estimator to capture fine-grained, persona-relevant signals. We evaluate the model across rule-based, LLM-based, and human-centered metrics, demonstrating consistent improvements in consistency, grounding, and preference alignment. Our framework achieves the highest performance across all evaluation settings and generalizes effectively to unseen product categories. Our results highlight the promise of steerable pluralistic alignment for building next-generation personalized decision-support systems.