Speculative Decoding Speed-of-Light: Optimal Lower Bounds via Branching Random Walks
作者: Sergey Pankratov, Dan Alistarh
分类: cs.CL
发布日期: 2025-12-12
💡 一句话要点
提出确定性推测生成算法的运行时间下界
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测生成 大型语言模型 运行时间下界 分支随机游走 并行处理
📋 核心要点
- 现有推测生成技术在加速大型语言模型推理方面存在基本限制,尤其是对可实现加速的理解不足。
- 本文通过将标记生成过程与分支随机游走相联系,提出了确定性推测生成算法的运行时间下界,揭示了并行生成的极限。
- 实证评估显示,所提出的理论下界在Llama模型中得到了验证,确认了其在实际应用中的有效性。
📝 摘要(中文)
推测生成作为加速大型语言模型推理的有效技术,通过并行验证多个草稿标记。然而,现有对可实现加速的基本限制理解不足。本文首次建立了任何确定性推测生成算法的“紧”下界,借助将标记生成过程与分支随机游走相联系,分析了最优草稿树选择问题。在基本假设下,我们证明了每次推测迭代成功预测的标记数量的期望值受到限制,提供了对并行标记生成极限的新见解,并为未来推测解码系统的设计提供指导。对Llama模型的实证评估验证了我们的理论预测,确认了下界在实际设置中的紧密性。
🔬 方法详解
问题定义:本文旨在解决推测生成算法在大型语言模型推理中的运行时间下界问题。现有方法对加速的基本限制理解不足,导致无法优化推测生成过程。
核心思路:通过将标记生成过程与分支随机游走相联系,分析最优草稿树选择问题,建立了运行时间的紧下界。这种设计使得我们能够在理论上界定推测生成的极限。
技术框架:整体架构包括推测生成的迭代过程,主要模块包括标记生成、验证和草稿树选择。通过并行处理多个草稿标记,提升了生成效率。
关键创新:本文的主要创新在于首次建立了确定性推测生成算法的运行时间下界,与现有方法相比,提供了更为严谨的理论基础和分析框架。
关键设计:关键参数包括验证者的容量$P$、输出分布的期望熵$μ$及其二阶对数矩,损失函数设计基于标记生成的期望成功率,确保了理论分析的准确性。
🖼️ 关键图片
📊 实验亮点
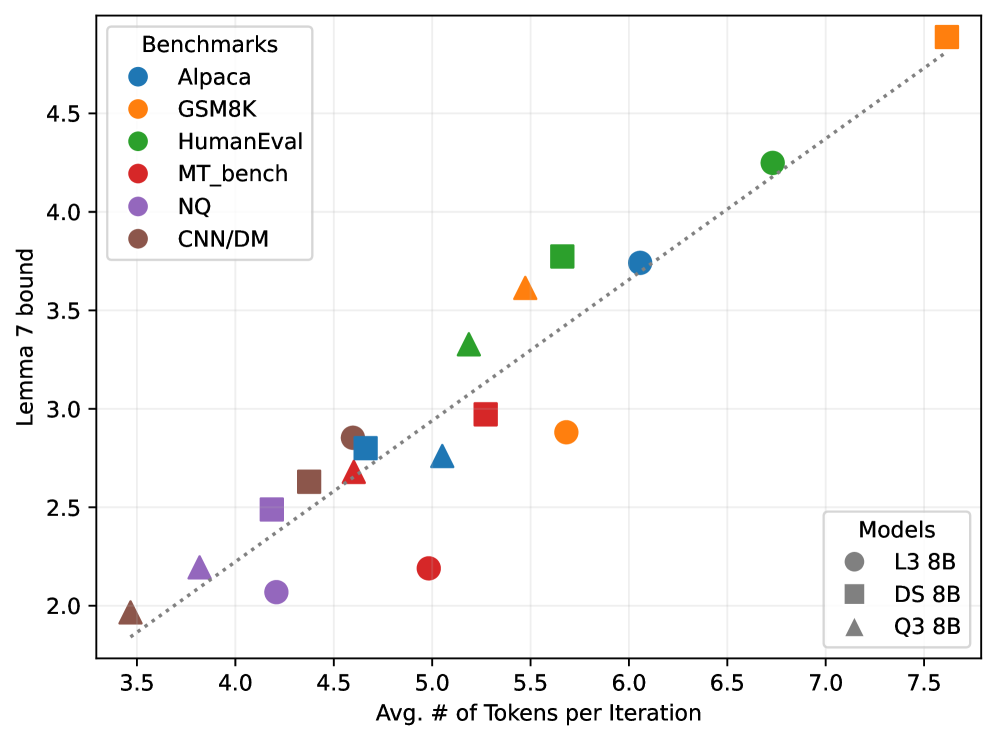
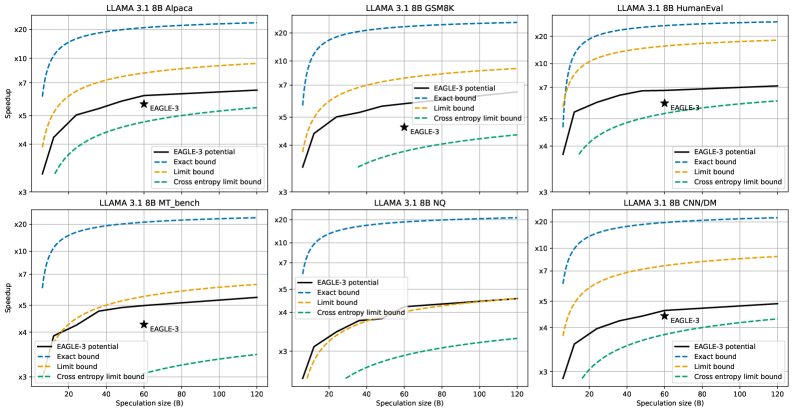
实验结果表明,所提出的理论下界在Llama模型中得到了验证,成功预测的标记数量在推测迭代中达到了理论预期,确认了下界的紧密性。这为推测生成技术的实际应用提供了重要的参考。
🎯 应用场景
该研究的潜在应用领域包括大型语言模型的推理加速、自然语言处理任务的优化以及智能对话系统的改进。通过提供理论基础,未来可以设计出更高效的推测解码系统,提升模型的响应速度和准确性。
📄 摘要(原文)
Speculative generation has emerged as a promising technique to accelerate inference in large language models (LLMs) by leveraging parallelism to verify multiple draft tokens simultaneously. However, the fundamental limits on the achievable speedup remain poorly understood. In this work, we establish the first ``tight'' lower bounds on the runtime of any deterministic speculative generation algorithm. This is achieved by drawing a parallel between the token generation process and branching random walks, which allows us to analyze the optimal draft tree selection problem. We prove, under basic assumptions, that the expected number of tokens successfully predicted per speculative iteration is bounded as $\mathbb{E}[X] \leq (μ+ μ_{(2)})\log(P )/μ^2 + O(1)$, where $P$ is the verifier's capacity, $μ$ is the expected entropy of the verifier's output distribution, and $μ_{(2)}$ is the expected second log-moment. This result provides new insights into the limits of parallel token generation, and could guide the design of future speculative decoding systems. Empirical evaluations on Llama models validate our theoretical predictions, confirming the tightness of our bounds in practical settings.