AdaSD: Adaptive Speculative Decoding for Efficient Language Model Inference
作者: Kuan-Wei Lu, Ding-Yong Hong, Pangfeng Liu
分类: cs.CL
发布日期: 2025-12-12
💡 一句话要点
提出AdaSD自适应推测解码,无需调参提升大语言模型推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推测解码 自适应解码 模型推理加速 无超参数 token熵 Jensen-Shannon距离
📋 核心要点
- 现有推测解码方法需要额外训练、超参数调整或预先分析,部署成本高。
- AdaSD动态调整生成长度和接受标准,无需超参数,即插即用。
- 实验表明,AdaSD在精度损失小于2%的情况下,推理速度提升高达49%。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中表现出色,但其不断增长的参数规模显著降低了推理速度。推测解码通过利用较小的draft模型预测候选token,然后由较大的target模型验证,从而缓解了这个问题。然而,现有方法通常需要额外的训练、大量的超参数调整或部署前的模型和任务的预先分析。本文提出了自适应推测解码(AdaSD),这是一种无需超参数的解码方案,可在推理过程中动态调整生成长度和接受标准。AdaSD引入了两个自适应阈值:一个用于确定何时停止候选token生成,另一个用于决定token接受,这两个阈值都基于token熵和Jensen-Shannon距离实时更新。这种方法无需预分析或微调,并且与现成的模型兼容。在基准数据集上的实验表明,AdaSD比标准推测解码实现了高达49%的加速,同时将精度下降限制在2%以内,使其成为高效自适应LLM推理的实用解决方案。
🔬 方法详解
问题定义:现有推测解码方法在提升大语言模型推理效率时,通常需要针对特定模型和任务进行额外的训练、精细的超参数调整,或者在部署前进行大量的预分析,这增加了部署和使用的复杂性,限制了其通用性和易用性。这些方法难以适应不同模型和任务之间的差异,需要耗费大量时间和资源进行优化。
核心思路:AdaSD的核心思路是在推理过程中动态地调整候选token的生成长度和接受标准,从而避免了对超参数的依赖。它利用token的熵和Jensen-Shannon距离来实时评估生成质量,并根据这些指标自适应地调整阈值,以决定何时停止生成候选token以及接受哪些token。这种自适应的方法使得AdaSD能够根据当前模型的行为和任务的特点进行调整,从而在保证精度的前提下最大化推理速度。
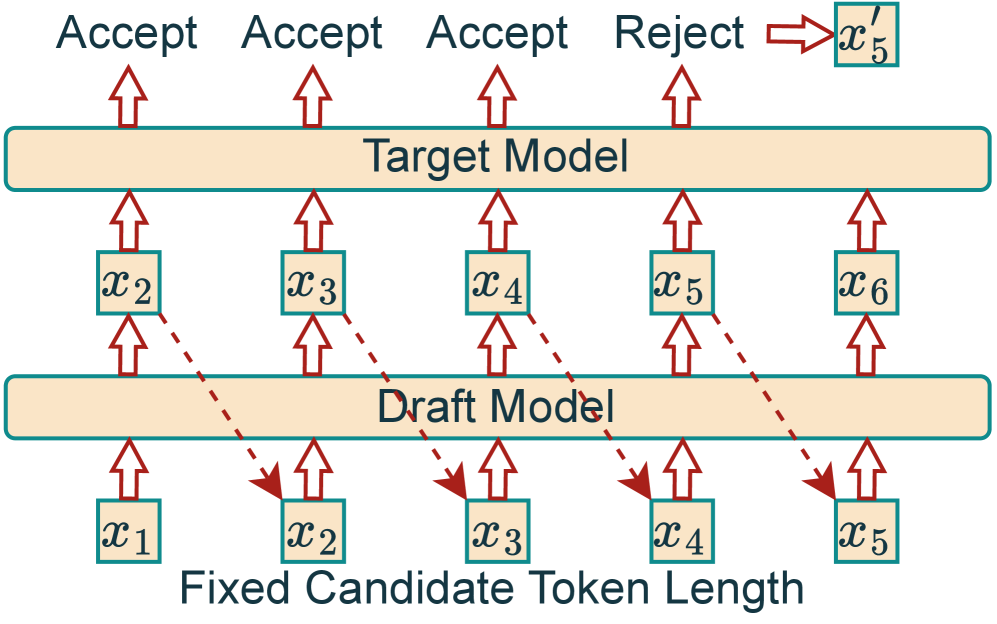
技术框架:AdaSD的整体流程如下:首先,使用draft模型生成一系列候选token。然后,使用target模型对这些候选token进行验证。在验证过程中,AdaSD会计算每个token的熵和Jensen-Shannon距离,并根据这两个指标动态地调整生成长度和接受阈值。如果token的熵较低或与target模型的预测结果差异较大,则会提前停止生成或拒绝接受该token。这个过程会一直重复,直到生成足够数量的token或达到最大生成长度。
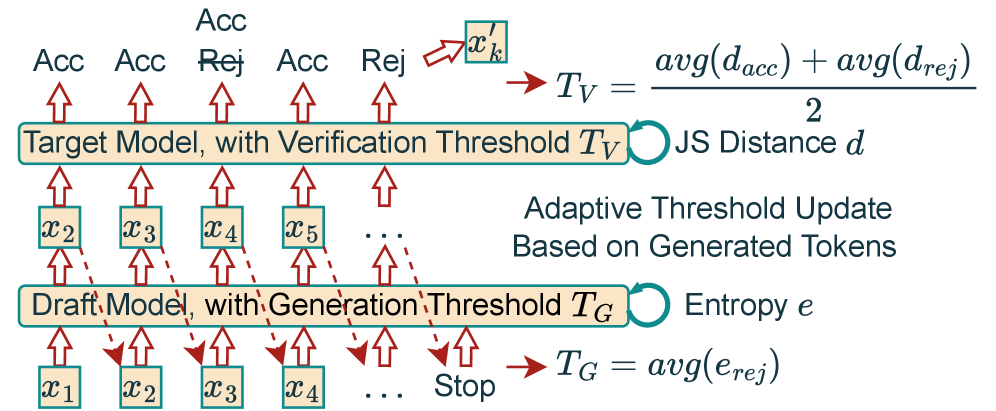
关键创新:AdaSD最重要的技术创新点在于其自适应性。它通过引入两个自适应阈值,分别控制候选token的生成长度和接受标准,从而避免了对超参数的依赖。这两个阈值基于token熵和Jensen-Shannon距离实时更新,使得AdaSD能够根据当前模型的行为和任务的特点进行调整。与现有方法相比,AdaSD无需预分析或微调,并且与现成的模型兼容,具有更高的通用性和易用性。
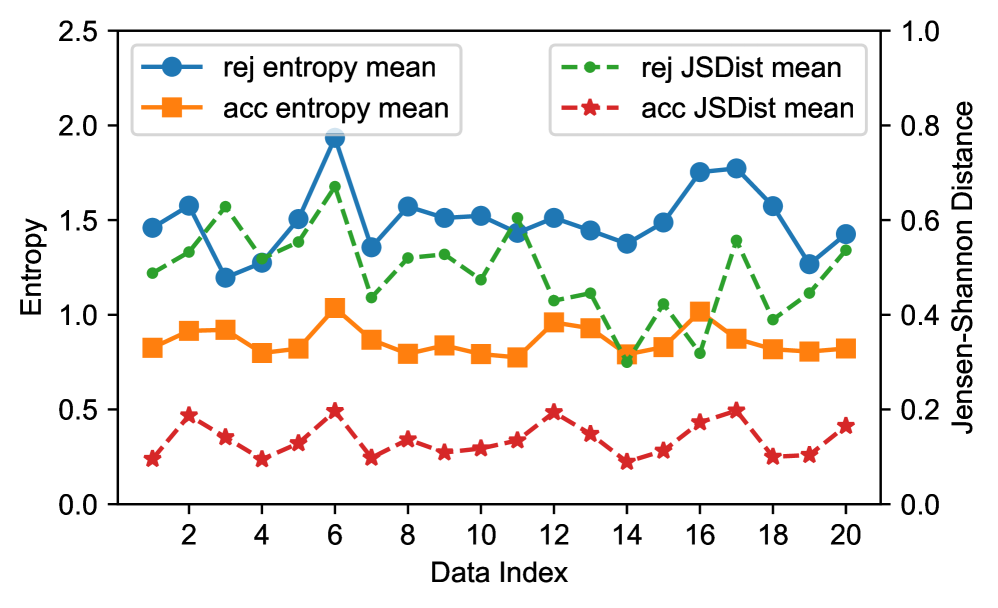
关键设计:AdaSD的关键设计包括:1) 使用token熵来衡量生成token的不确定性,熵越低表示生成质量越高;2) 使用Jensen-Shannon距离来衡量draft模型和target模型预测结果之间的差异,距离越小表示draft模型的预测越准确;3) 基于token熵和Jensen-Shannon距离动态调整生成长度和接受阈值,具体调整策略未知,论文中可能包含相关公式或算法描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AdaSD在多个基准数据集上实现了显著的性能提升。与标准推测解码相比,AdaSD能够实现高达49%的加速,同时将精度下降限制在2%以内。这些结果表明,AdaSD是一种高效且实用的LLM推理加速方案,能够在保证精度的前提下显著提升推理速度。
🎯 应用场景
AdaSD可广泛应用于各种需要高效大语言模型推理的场景,例如在线对话系统、文本生成、机器翻译等。它能够显著提升推理速度,降低计算成本,使得大语言模型能够更广泛地应用于资源受限的环境中,例如移动设备或边缘计算设备。此外,AdaSD的自适应性使其能够更好地适应不同的模型和任务,从而提高其通用性和易用性。
📄 摘要(原文)
Large language models (LLMs) have achieved remarkable performance across a wide range of tasks, but their increasing parameter sizes significantly slow down inference. Speculative decoding mitigates this issue by leveraging a smaller draft model to predict candidate tokens, which are then verified by a larger target model. However, existing approaches often require additional training, extensive hyperparameter tuning, or prior analysis of models and tasks before deployment. In this paper, we propose Adaptive Speculative Decoding (AdaSD), a hyperparameter-free decoding scheme that dynamically adjusts generation length and acceptance criteria during inference. AdaSD introduces two adaptive thresholds: one to determine when to stop candidate token generation and another to decide token acceptance, both updated in real time based on token entropy and Jensen-Shannon distance. This approach eliminates the need for pre-analysis or fine-tuning and is compatible with off-the-shelf models. Experiments on benchmark datasets demonstrate that AdaSD achieves up to 49\% speedup over standard speculative decoding while limiting accuracy degradation to under 2\%, making it a practical solution for efficient and adaptive LLM inference.