Computational emotion analysis with multimodal LLMs: Current evidence on an emerging methodological opportunity
作者: Hauke Licht
分类: cs.CL
发布日期: 2025-12-11 (更新: 2026-01-16)
💡 一句话要点
评估多模态LLM在政治视频情感分析中的可靠性,揭示实验室与实际场景的性能差距。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 情感分析 大型语言模型 政治传播 视频分析
📋 核心要点
- 现有方法难以可靠地分析真实政治场景中视频的情感,缺乏对多模态LLM在实际应用中性能的系统评估。
- 论文核心在于评估多模态LLM在真实政治视频情感分析中的性能,并揭示其在实验室环境和实际场景中的差异。
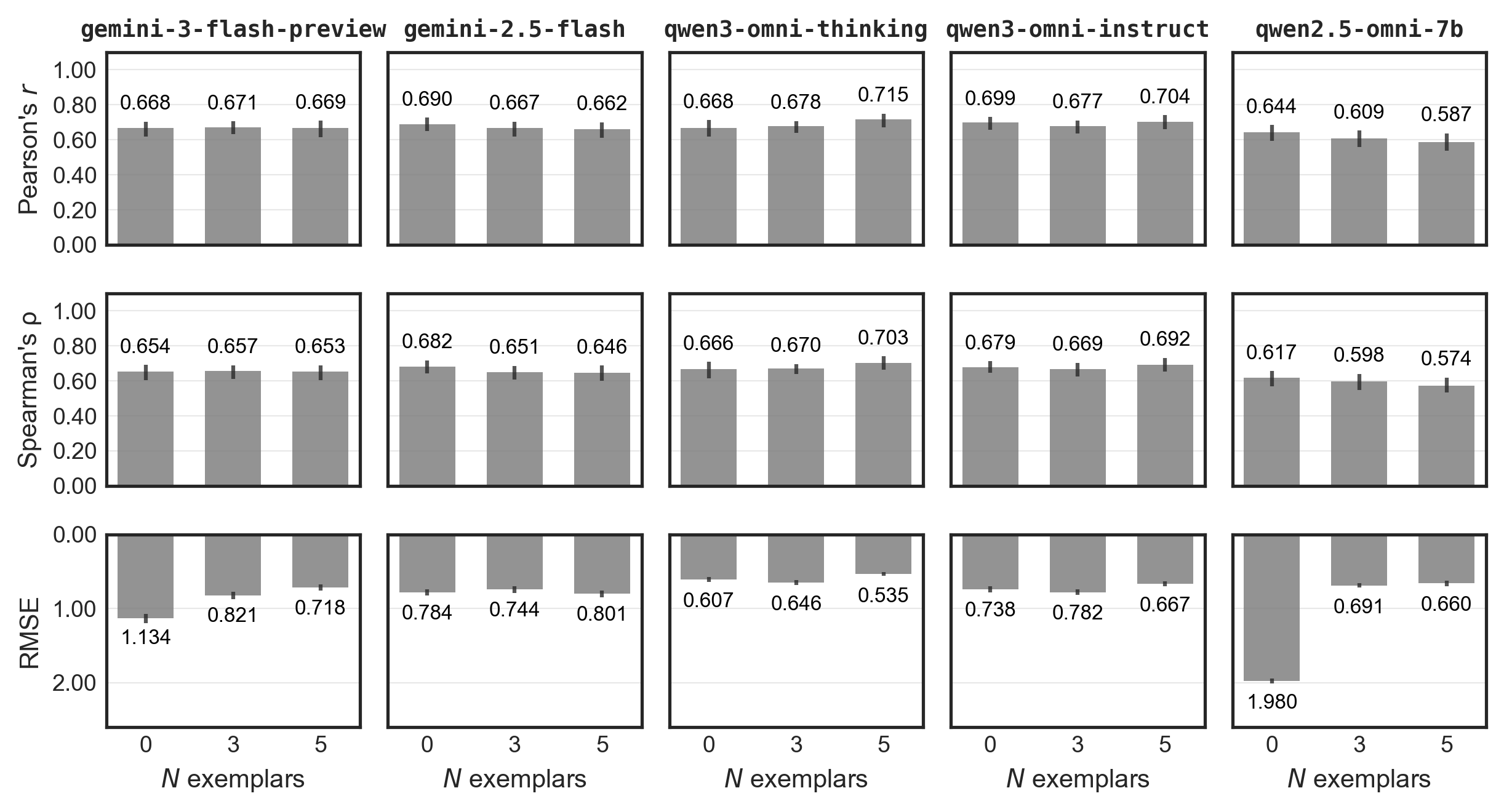
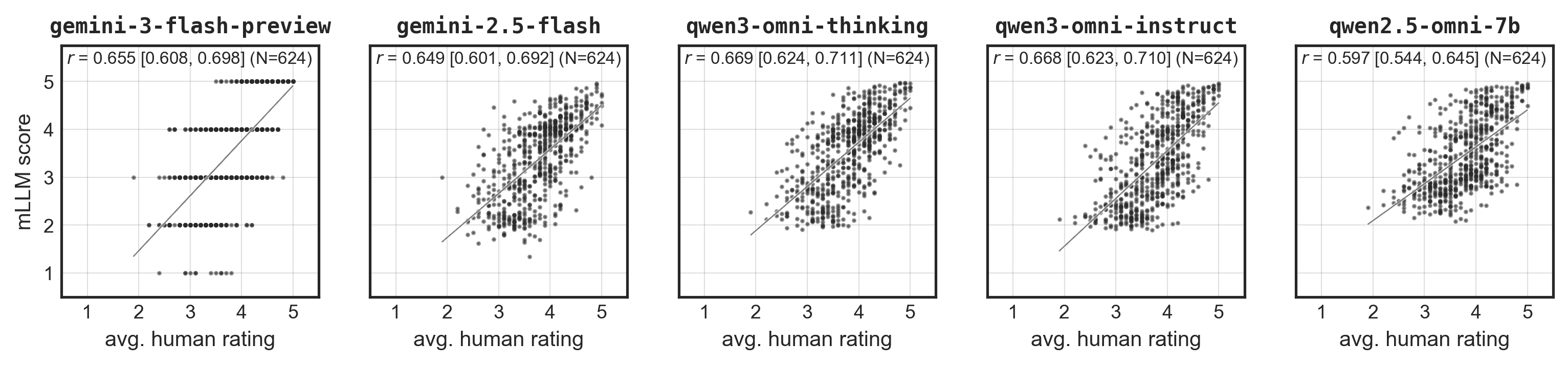
- 实验表明,多模态LLM在实验室数据上表现良好,但在真实议会辩论视频中性能显著下降,并存在偏差。
📝 摘要(中文)
本研究评估了领先的多模态大型语言模型(mLLMs)在基于视频的情感唤醒度测量中的性能,特别关注政治传播领域。通过使用两个互补的人工标注视频数据集:实验室条件下录制的视频和真实的议会辩论视频,发现了一个关键的实验室与实际场景的性能差距。在实验室视频中,mLLMs的唤醒度评分接近人类水平,且几乎没有人口统计学偏差。然而,在议会辩论录音中,所有模型的唤醒度评分与平均人类评分的相关性最多为中等,并且表现出按发言人性别和年龄的系统性偏差。即使依赖领先的闭源mLLMs或计算噪声缓解策略也无法改变这一发现。此外,当使用视频录音而不是相同演讲的文本记录时,mLLMs在情感分析方面的表现甚至更差。这些发现揭示了当前mLLMs在真实政治视频分析中的重要局限性,并建立了一个严格的评估框架,用于跟踪未来的发展。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(mLLMs)在真实政治场景视频情感分析中可靠性不足的问题。现有方法,特别是基于文本的情感分析,无法充分利用视频中的视觉和听觉信息。此外,现有研究缺乏对mLLMs在实验室环境和真实场景下性能差异的系统评估,导致模型在实际应用中表现不佳。
核心思路:论文的核心思路是通过对比mLLMs在实验室控制视频和真实议会辩论视频上的情感唤醒度测量结果,来评估其在真实场景下的性能。通过人工标注数据作为ground truth,分析mLLMs的预测结果与人类判断之间的相关性,并识别潜在的偏差。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建或获取包含实验室视频和真实场景视频的数据集,并进行人工情感标注;2) 选择代表性的mLLMs进行实验,例如闭源的领先模型;3) 使用mLLMs对视频进行情感唤醒度预测;4) 分析mLLMs的预测结果与人工标注之间的相关性,评估模型的性能;5) 识别模型预测结果中存在的偏差,例如按发言人性别和年龄的偏差;6) 尝试使用计算噪声缓解策略来提高模型性能。
关键创新:论文的关键创新在于揭示了mLLMs在实验室环境和真实场景下的性能差距,并指出了其在真实政治视频情感分析中存在的局限性。此外,论文还建立了一个严格的评估框架,可以用于跟踪未来mLLMs在情感分析方面的进展。
关键设计:论文的关键设计包括:1) 使用两个互补的数据集,分别代表实验室环境和真实场景;2) 使用人工情感标注作为ground truth,以评估mLLMs的预测结果;3) 分析模型预测结果中存在的偏差,例如按发言人性别和年龄的偏差;4) 尝试使用计算噪声缓解策略来提高模型性能,但结果表明效果不佳。具体参数设置和网络结构取决于所使用的mLLMs,论文侧重于评估而非模型改进。
🖼️ 关键图片

📊 实验亮点
实验结果表明,多模态LLM在实验室环境下视频的情感唤醒度测量中表现接近人类水平,但在真实议会辩论视频中,其性能显著下降,与人类评分的相关性最多为中等,并存在明显的性别和年龄偏差。即使采用领先的闭源模型和计算噪声缓解策略,也无法有效解决这些问题。视频情感分析效果甚至不如使用文本转录。
🎯 应用场景
该研究成果可应用于政治传播分析、舆情监控、人机交互等领域。通过更准确地理解视频中的情感信息,可以帮助研究人员分析政治人物的情感表达,监控社会舆论的变化,并改善人机交互的自然性和有效性。未来的研究可以基于此评估框架,开发更鲁棒、更可靠的多模态情感分析模型。
📄 摘要(原文)
Research increasingly leverages audio-visual materials to analyze emotions in political communication. Multimodal large language models (mLLMs) promise to enable such analyses through in-context learning. However, we lack systematic evidence on whether these models can reliably measure emotions in real-world political settings. This paper evaluates leading mLLMs for video-based emotional arousal measurement using two complementary human-labeled video datasets: recordings created under laboratory conditions and real-world parliamentary debates. I find a critical lab-vs-field performance gap. In video created under laboratory conditions, mLLMs arousal scores approach human-level reliability with little to no demographic bias. However, in parliamentary debate recordings, all examined models' arousal scores correlate at best moderately with average human ratings and exhibit systematic bias by speaker gender and age. Neither relying on leading closed-source mLLMs nor computational noise mitigation strategies change this finding. Further, mLLMs underperform even in sentiment analysis when using video recordings instead of text transcripts of the same speeches. These findings reveal important limitations of current mLLMs for real-world political video analysis and establish a rigorous evaluation framework for tracking future developments.