The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality
作者: Aileen Cheng, Alon Jacovi, Amir Globerson, Ben Golan, Charles Kwong, Chris Alberti, Connie Tao, Eyal Ben-David, Gaurav Singh Tomar, Lukas Haas, Yonatan Bitton, Adam Bloniarz, Aijun Bai, Andrew Wang, Anfal Siddiqui, Arturo Bajuelos Castillo, Aviel Atias, Chang Liu, Corey Fry, Daniel Balle, Deepanway Ghosal, Doron Kukliansky, Dror Marcus, Elena Gribovskaya, Eran Ofek, Honglei Zhuang, Itay Laish, Jan Ackermann, Lily Wang, Meg Risdal, Megan Barnes, Michael Fink, Mohamed Amin, Moran Ambar, Natan Potikha, Nikita Gupta, Nitzan Katz, Noam Velan, Ofir Roval, Ori Ram, Polina Zablotskaia, Prathamesh Bang, Priyanka Agrawal, Rakesh Ghiya, Sanjay Ganapathy, Simon Baumgartner, Sofia Erell, Sushant Prakash, Thibault Sellam, Vikram Rao, Xuanhui Wang, Yaroslav Akulov, Yulong Yang, Zhen Yang, Zhixin Lai, Zhongru Wu, Anca Dragan, Avinatan Hassidim, Fernando Pereira, Slav Petrov, Srinivasan Venkatachary, Tulsee Doshi, Yossi Matias, Sasha Goldshtein, Dipanjan Das
分类: cs.CL, cs.AI
发布日期: 2025-12-11
💡 一句话要点
提出FACTS Leaderboard,全面评估大型语言模型的事实准确性,覆盖多模态、参数知识、搜索和文档 grounding 四个场景。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 事实性评估 基准测试 多模态学习 知识检索 文档 grounding 自动评判 信息搜索
📋 核心要点
- 现有大型语言模型在生成文本时,经常出现事实性错误,缺乏全面评估工具。
- FACTS Leaderboard 旨在通过多场景基准测试,综合评估语言模型的事实准确性,提供更可靠的度量。
- 该 Leaderboard 包含多模态、参数知识、搜索和文档 grounding 四个子任务,并使用自动评判模型进行评估。
📝 摘要(中文)
本文介绍了一个名为FACTS Leaderboard的在线排行榜套件以及相关的基准测试集,旨在全面评估语言模型在各种场景中生成事实准确文本的能力。该套件通过汇总模型在四个不同的子排行榜上的表现来提供事实性的整体度量:(1)FACTS Multimodal,衡量对基于图像的问题的回答的事实性;(2)FACTS Parametric,通过回答来自内部参数的闭卷事实问题来评估模型的世界知识;(3)FACTS Search,评估信息搜索场景中的事实性,其中模型必须使用搜索API;(4)FACTS Grounding(v2),评估长篇回复是否基于提供的文档,并具有显著改进的评判模型。每个子排行榜都采用自动评判模型来对模型响应进行评分,最终的套件分数是四个组成部分的平均值,旨在提供对模型整体事实性的稳健和平衡的评估。FACTS Leaderboard套件将得到积极维护,包含公共和私有拆分,以便在保护其完整性的同时允许外部参与。该套件可在https://www.kaggle.com/benchmarks/google/facts上找到。
🔬 方法详解
问题定义:大型语言模型在生成文本时,经常出现事实性错误,缺乏一个全面、多维度的评估框架。现有方法可能只关注特定类型的事实性问题,无法有效衡量模型在不同场景下的表现,例如多模态理解、知识检索和文档摘要等。
核心思路:FACTS Leaderboard 的核心思路是构建一个包含多个子任务的综合评估体系,每个子任务针对不同类型的事实性问题进行评估。通过对模型在各个子任务上的表现进行加权平均,得到一个整体的事实性得分,从而更全面地反映模型的事实准确性。
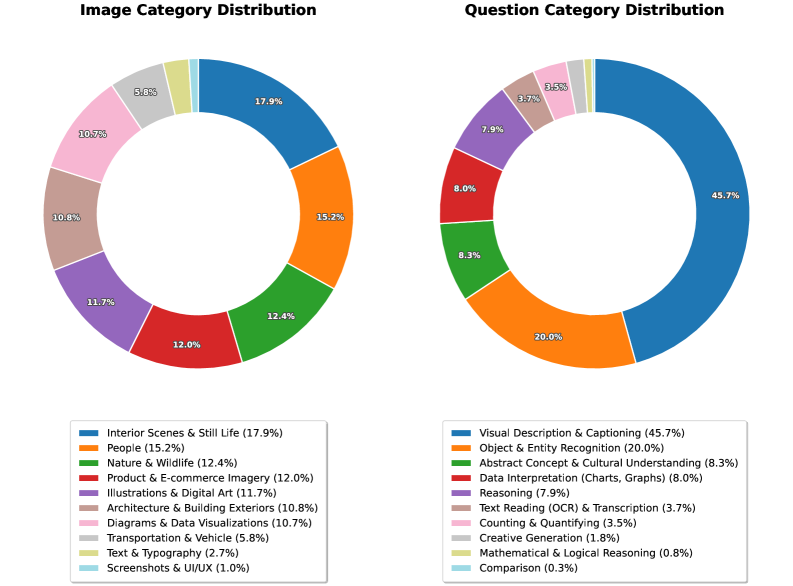
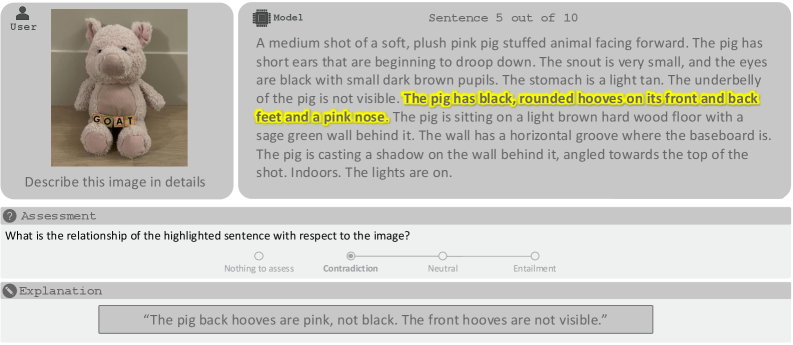
技术框架:FACTS Leaderboard 包含四个主要的子排行榜:FACTS Multimodal (评估多模态事实性)、FACTS Parametric (评估参数知识)、FACTS Search (评估搜索增强的事实性) 和 FACTS Grounding (评估文档 grounding 的事实性)。每个子排行榜都包含数据集和评估指标。模型需要针对每个子排行榜中的问题生成答案,然后使用自动评判模型对答案的事实性进行评分。最终的 Leaderboard 得分是四个子排行榜得分的平均值。
关键创新:FACTS Leaderboard 的关键创新在于其综合性和多维度。它不仅考虑了传统的事实性问题,还涵盖了多模态、搜索增强和文档 grounding 等更复杂的场景。此外,FACTS Grounding (v2) 使用了显著改进的评判模型,提高了评估的准确性。
关键设计:每个子排行榜都有其特定的数据集和评估指标。例如,FACTS Multimodal 使用图像和问题对,要求模型根据图像回答问题;FACTS Search 使用搜索 API,要求模型检索相关信息并生成答案;FACTS Grounding 使用文档和问题对,要求模型根据文档生成答案。评估指标包括准确率、召回率和 F1 值等。具体参数设置和损失函数取决于每个子排行榜所使用的自动评判模型。
🖼️ 关键图片

📊 实验亮点
FACTS Leaderboard 通过四个子任务综合评估语言模型的事实性,涵盖多模态、参数知识、搜索和文档 grounding 等多个维度。FACTS Grounding (v2) 采用了显著改进的评判模型,提高了评估的准确性。该 Leaderboard 提供了一个公开的平台,方便研究人员和开发者进行模型评估和比较。
🎯 应用场景
FACTS Leaderboard 可用于评估和比较不同大型语言模型的事实准确性,帮助研究人员和开发者选择更可靠的模型。此外,该 Leaderboard 还可以促进对语言模型事实性问题的研究,推动相关技术的进步,例如提高模型知识的准确性、增强模型的多模态理解能力和改进模型的文档摘要能力。
📄 摘要(原文)
We introduce The FACTS Leaderboard, an online leaderboard suite and associated set of benchmarks that comprehensively evaluates the ability of language models to generate factually accurate text across diverse scenarios. The suite provides a holistic measure of factuality by aggregating the performance of models on four distinct sub-leaderboards: (1) FACTS Multimodal, which measures the factuality of responses to image-based questions; (2) FACTS Parametric, which assesses models' world knowledge by answering closed-book factoid questions from internal parameters; (3) FACTS Search, which evaluates factuality in information-seeking scenarios, where the model must use a search API; and (4) FACTS Grounding (v2), which evaluates whether long-form responses are grounded in provided documents, featuring significantly improved judge models. Each sub-leaderboard employs automated judge models to score model responses, and the final suite score is an average of the four components, designed to provide a robust and balanced assessment of a model's overall factuality. The FACTS Leaderboard Suite will be actively maintained, containing both public and private splits to allow for external participation while guarding its integrity. It can be found at https://www.kaggle.com/benchmarks/google/facts .