AgriGPT-Omni: A Unified Speech-Vision-Text Framework for Multilingual Agricultural Intelligence
作者: Bo Yang, Lanfei Feng, Yunkui Chen, Yu Zhang, Jianyu Zhang, Xiao Xu, Nueraili Aierken, Shijian Li
分类: cs.CL
发布日期: 2025-12-11
💡 一句话要点
AgriGPT-Omni:构建统一的多语言农业智能语音-视觉-文本框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 农业智能 多模态学习 语音识别 自然语言处理 计算机视觉 多语言 强化学习
📋 核心要点
- 现有农业应用受限于多语言语音数据不足、缺乏统一的多模态架构和全面的评估基准。
- AgriGPT-Omni通过数据合成、多模态对齐和强化学习,构建统一的语音-视觉-文本框架。
- 实验表明,AgriGPT-Omni在多语言和多模态推理及语音理解方面优于通用基线。
📝 摘要(中文)
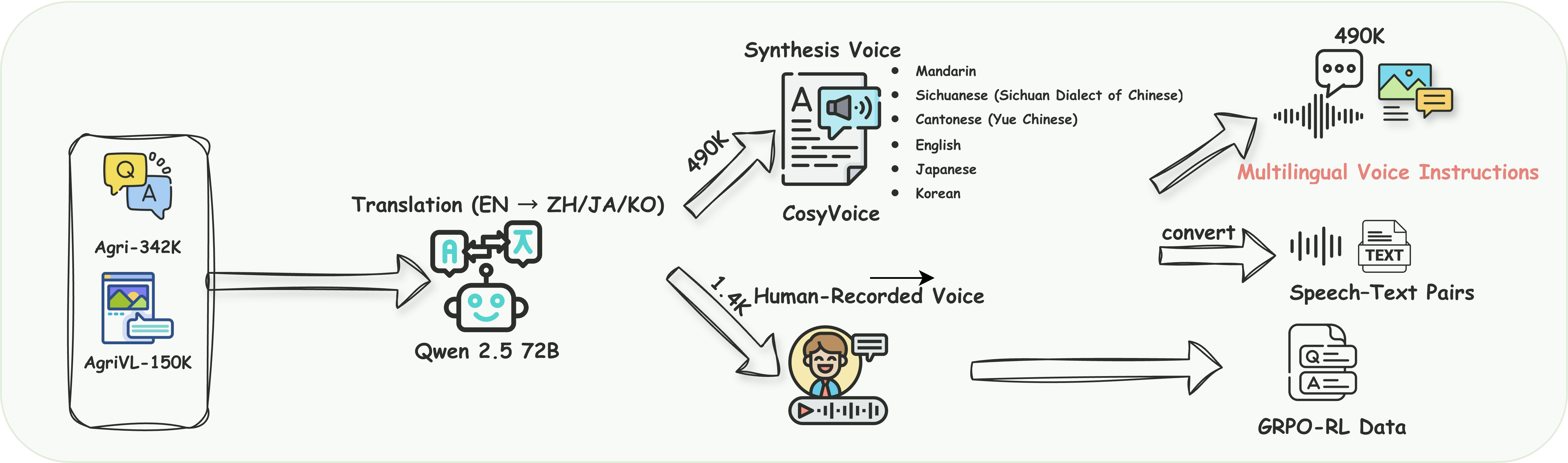
本文提出了AgriGPT-Omni,一个集成了语音、视觉和文本的农业全能框架,旨在解决农业应用中多语言语音数据匮乏、统一多模态架构缺失以及缺乏全面评估基准的问题。首先,构建了一个可扩展的数据合成和收集流程,将农业文本和图像转换为训练数据,从而产生了迄今为止最大的农业语音数据集,包括六种语言的492K合成语音样本和1.4K真实语音样本。其次,在此基础上,通过文本知识注入、渐进式多模态对齐和基于GRPO的强化学习的三阶段范式,训练了第一个农业全能模型,实现了跨语言和模态的统一推理。第三,提出了AgriBench-Omni-2K,这是第一个农业三模态基准,涵盖了各种语音-视觉-文本任务和多语言切片,具有标准化的协议和可复现的工具。实验表明,AgriGPT-Omni在多语言和多模态推理以及真实语音理解方面显著优于通用基线模型。所有模型、数据、基准和代码都将发布,以促进可复现的研究、包容性农业智能以及低资源地区的可持续人工智能发展。
🔬 方法详解
问题定义:现有方法在农业领域的多模态应用中,面临着缺乏足够的多语言语音数据、难以构建统一的多模态架构以及缺乏全面评估基准的挑战。这限制了农业智能在多语言环境下的发展,也难以充分利用语音、视觉和文本信息进行综合推理。
核心思路:论文的核心思路是通过数据合成和收集,构建大规模多语言农业语音数据集;然后,利用该数据集训练一个统一的多模态模型,使其能够进行跨语言和跨模态的推理。通过渐进式多模态对齐和强化学习,提升模型在真实场景下的性能。
技术框架:AgriGPT-Omni框架包含三个主要阶段:1) 文本知识注入:利用农业文本数据预训练模型,使其具备初步的农业知识;2) 渐进式多模态对齐:逐步将语音和视觉模态的信息与文本模态对齐,使模型能够理解和关联不同模态的信息;3) 基于GRPO的强化学习:使用GRPO(未知)算法对模型进行强化学习,以优化其在特定任务上的性能。
关键创新:该论文的关键创新在于:1) 构建了迄今为止最大的多语言农业语音数据集;2) 提出了一个统一的多模态框架,能够处理语音、视觉和文本信息,并进行跨语言和跨模态的推理;3) 设计了一个三阶段的训练范式,包括文本知识注入、渐进式多模态对齐和基于GRPO的强化学习。
关键设计:论文中涉及的关键设计细节包括:数据合成和收集流程的具体方法、多模态对齐的具体策略、GRPO强化学习算法的参数设置以及损失函数的设计。由于论文摘要中未提供具体细节,这些部分目前未知。
🖼️ 关键图片


📊 实验亮点
AgriGPT-Omni在多语言和多模态推理以及真实语音理解方面显著优于通用基线模型。论文提出了AgriBench-Omni-2K,这是第一个农业三模态基准,涵盖了各种语音-视觉-文本任务和多语言切片,具有标准化的协议和可复现的工具。具体的性能数据和提升幅度需要在论文全文中查找。
🎯 应用场景
AgriGPT-Omni在农业领域具有广泛的应用前景,例如智能农机控制、农作物病虫害诊断、农业知识问答、多语言农业技术推广等。该研究有助于提升农业生产效率,促进农业可持续发展,特别是在低资源地区,可以帮助农民获取农业知识和技术支持。
📄 摘要(原文)
Despite rapid advances in multimodal large language models, agricultural applications remain constrained by the lack of multilingual speech data, unified multimodal architectures, and comprehensive evaluation benchmarks. To address these challenges, we present AgriGPT-Omni, an agricultural omni-framework that integrates speech, vision, and text in a unified framework. First, we construct a scalable data synthesis and collection pipeline that converts agricultural texts and images into training data, resulting in the largest agricultural speech dataset to date, including 492K synthetic and 1.4K real speech samples across six languages. Second, based on this, we train the first agricultural omni-model via a three-stage paradigm: textual knowledge injection, progressive multimodal alignment, and GRPO-based reinforcement learning, enabling unified reasoning across languages and modalities. Third, we propose AgriBench-Omni-2K, the first tri-modal benchmark for agriculture, covering diverse speech-vision-text tasks and multilingual slices, with standardized protocols and reproducible tools. Experiments show that AgriGPT-Omni significantly outperforms general-purpose baselines on multilingual and multimodal reasoning as well as real-world speech understanding. All models, data, benchmarks, and code will be released to promote reproducible research, inclusive agricultural intelligence, and sustainable AI development for low-resource regions.