RoleRMBench & RoleRM: Towards Reward Modeling for Profile-Based Role Play in Dialogue Systems
作者: Hang Ding, Qiming Feng, Dongqi Liu, Qi Zhao, Tao Yao, Shuo Wang, Dongsheng Chen, Jian Li, Zhenye Gan, Jiangning Zhang, Chengjie Wang, Yabiao Wang
分类: cs.CL
发布日期: 2025-12-11
💡 一句话要点
提出RoleRMBench与RoleRM,提升角色扮演对话系统中奖励模型的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励建模 角色扮演对话 连续隐式偏好 人机交互 大型语言模型
📋 核心要点
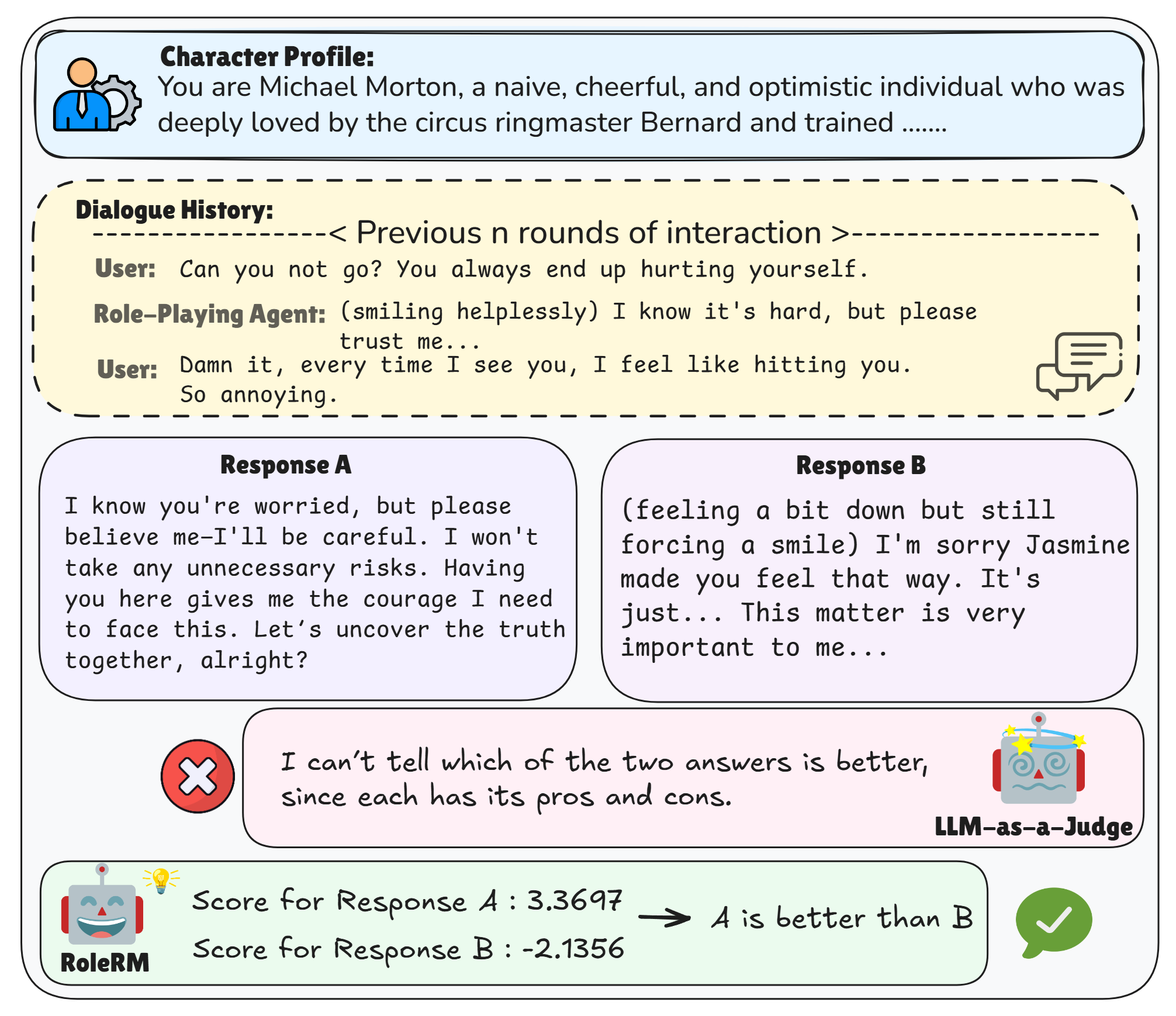
- 现有奖励模型在角色扮演等主观领域表现不佳,无法捕捉细微的人物设定和人类判断。
- 提出RoleRM,使用连续隐式偏好(CIP)训练,将主观评估转化为连续一致的成对监督。
- 实验表明,RoleRM在叙事连贯性和风格保真度方面显著优于现有模型,平均提升超过24%。
📝 摘要(中文)
奖励建模已成为将大型语言模型(LLMs)与人类偏好对齐的基石。然而,当扩展到角色扮演等主观和开放领域时,现有的奖励模型表现出严重的性能下降,难以捕捉细微的、基于人物设定的判断。为了解决这一差距,我们引入了RoleRMBench,这是第一个用于角色扮演对话中奖励建模的系统性基准,涵盖了从叙事管理到角色一致性和参与度的七个细粒度能力。在RoleRMBench上的评估揭示了通用奖励模型与人类判断之间存在巨大且持续的差距,尤其是在叙事和风格维度上。我们进一步提出了RoleRM,一个使用连续隐式偏好(CIP)训练的奖励模型,它将主观评估重新定义为在多种结构化策略下的连续一致的成对监督。综合实验表明,RoleRM的性能平均超过了强大的开源和闭源奖励模型24%以上,证明了在叙事连贯性和风格保真度方面的显著提升。我们的研究结果强调了连续偏好表示和标注一致性的重要性,为以人为中心的对话系统中的主观对齐奠定了基础。
🔬 方法详解
问题定义:现有奖励模型在角色扮演对话等主观开放领域表现不佳,无法准确捕捉人物设定和人类偏好,导致生成的内容缺乏叙事连贯性和风格一致性。现有的奖励模型通常是通用的,缺乏针对角色扮演场景的优化,难以处理细粒度的评估标准。
核心思路:论文的核心思路是将主观评估重新定义为连续隐式偏好(CIP),通过连续一致的成对监督来训练奖励模型。这种方法能够更好地捕捉人类在角色扮演对话中的细微偏好,并提高奖励模型的准确性和鲁棒性。通过多种结构化策略,可以更好地利用标注数据,提升模型的泛化能力。
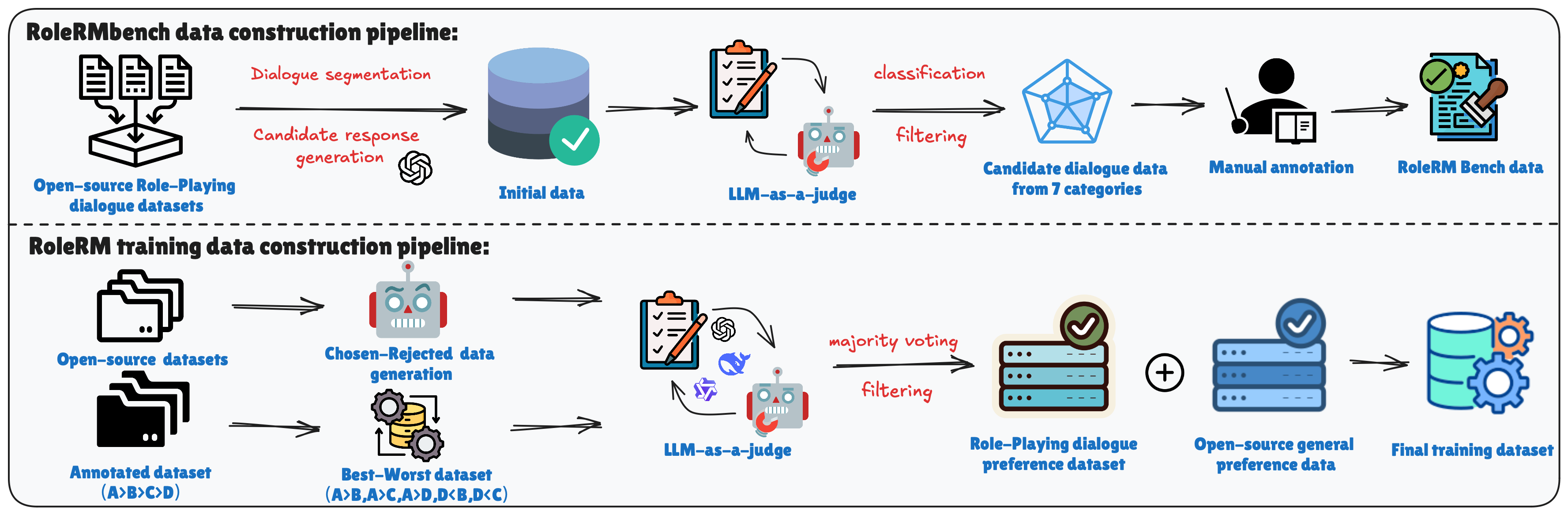
技术框架:整体框架包含两个主要部分:RoleRMBench基准数据集和RoleRM奖励模型。RoleRMBench提供了一个全面的评估平台,用于评估奖励模型在角色扮演对话中的性能。RoleRM则利用RoleRMBench的数据进行训练,通过CIP学习人类偏好。训练过程包括数据预处理、模型训练和评估三个阶段。
关键创新:最重要的技术创新点在于使用连续隐式偏好(CIP)来表示人类对角色扮演对话的偏好。与传统的离散偏好表示相比,CIP能够更细粒度地捕捉人类的主观判断,并提供更丰富的监督信号。此外,论文还提出了多种结构化策略,用于提高标注数据的一致性和模型的泛化能力。
关键设计:RoleRM使用Transformer架构作为基础模型,并引入了CIP损失函数。CIP损失函数旨在最小化模型预测的偏好与人类标注的偏好之间的差异。论文还探索了不同的结构化策略,例如对比学习和排序学习,以提高模型的性能。具体的参数设置包括学习率、batch size、训练轮数等,这些参数通过实验进行调整。
🖼️ 关键图片
📊 实验亮点
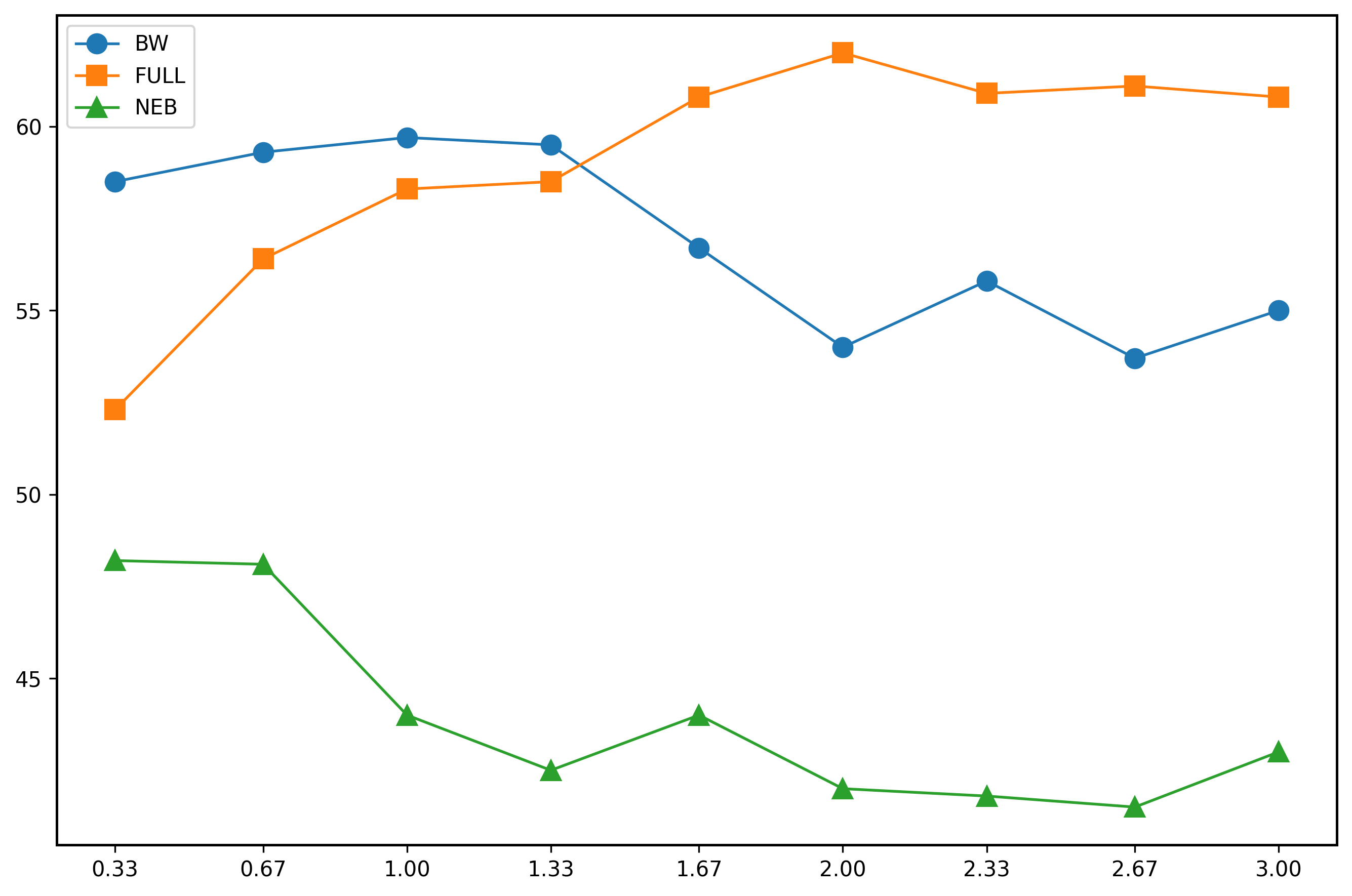
实验结果表明,RoleRM在RoleRMBench基准测试中显著优于现有的开源和闭源奖励模型,平均提升超过24%。尤其在叙事连贯性和风格保真度方面,RoleRM表现出明显的优势。这些结果验证了连续隐式偏好(CIP)表示和标注一致性的有效性,为角色扮演对话系统的奖励建模提供了新的方向。
🎯 应用场景
该研究成果可应用于各种角色扮演对话系统,例如游戏中的NPC对话、虚拟助手、以及教育和娱乐领域的互动应用。通过提升奖励模型的性能,可以生成更具吸引力、更符合人物设定、更贴近人类偏好的对话内容,从而增强用户体验和互动效果。未来,该技术有望扩展到其他主观和开放领域的对话系统。
📄 摘要(原文)
Reward modeling has become a cornerstone of aligning large language models (LLMs) with human preferences. Yet, when extended to subjective and open-ended domains such as role play, existing reward models exhibit severe degradation, struggling to capture nuanced and persona-grounded human judgments. To address this gap, we introduce RoleRMBench, the first systematic benchmark for reward modeling in role-playing dialogue, covering seven fine-grained capabilities from narrative management to role consistency and engagement. Evaluation on RoleRMBench reveals large and consistent gaps between general-purpose reward models and human judgment, particularly in narrative and stylistic dimensions. We further propose RoleRM, a reward model trained with Continuous Implicit Preferences (CIP), which reformulates subjective evaluation as continuous consistent pairwise supervision under multiple structuring strategies. Comprehensive experiments show that RoleRM surpasses strong open- and closed-source reward models by over 24% on average, demonstrating substantial gains in narrative coherence and stylistic fidelity. Our findings highlight the importance of continuous preference representation and annotation consistency, establishing a foundation for subjective alignment in human-centered dialogue systems.