Causal Reasoning Favors Encoders: On The Limits of Decoder-Only Models
作者: Amartya Roy, Elamparithy M, Kripabandhu Ghosh, Ponnurangam Kumaraguru, Adrian de Wynter
分类: cs.CL, cs.LG
发布日期: 2025-12-11
💡 一句话要点
因果推理更青睐编码器:解码器模型的局限性研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果推理 上下文学习 编码器-解码器模型 大语言模型 泛化能力
📋 核心要点
- 现有大语言模型在因果推理中依赖上下文学习,但易受输入中虚假词汇关系误导,缺乏可靠性。
- 论文提出编码器和编码器-解码器架构,通过潜在空间投影,增强模型在多步合取推理中的能力。
- 实验表明,微调后的编码器类模型在自然语言和非自然语言场景中,泛化能力优于仅解码器模型。
📝 摘要(中文)
本文研究了上下文学习(ICL)在大语言模型(LLMs)中的作用,尤其是在因果推理方面的表现。因果推理需要多步组合和严格的合取控制,而依赖输入中虚假的词汇关系可能导致误导性结果。作者假设,由于编码器和编码器-解码器架构能够将输入投影到潜在空间,因此它们比仅解码器模型更适合多步合取推理。通过比较微调后的各种架构与零样本和少样本ICL在自然语言和非自然语言场景中的表现,发现ICL本身不足以进行可靠的因果推理,常常过度关注不相关的输入特征。特别是,仅解码器模型对分布偏移非常敏感,而微调后的编码器和编码器-解码器模型在测试中表现出更强的泛化能力,包括非自然语言分割。两种架构只有在大规模下才能与仅解码器架构相媲美或超越。结论是,对于经济高效、短视距的鲁棒因果推理,具有针对性微调的编码器或编码器-解码器架构是更优选择。
🔬 方法详解
问题定义:论文旨在解决大语言模型在因果推理中,由于过度依赖输入文本的表面词汇关系而导致的推理错误问题。现有方法,特别是基于上下文学习的仅解码器模型,在面对分布偏移时表现脆弱,难以进行可靠的多步合取推理。
核心思路:论文的核心思路是利用编码器和编码器-解码器架构的优势,将输入投影到更抽象的潜在空间,从而减少对表面词汇关系的依赖,增强模型对因果关系的理解和推理能力。这种设计旨在提高模型在不同场景下的泛化能力和鲁棒性。
技术框架:论文采用对比实验的方法,比较了三种不同的架构:仅解码器模型、编码器模型和编码器-解码器模型。这些模型在自然语言和非自然语言场景下,分别使用零样本、少样本上下文学习以及微调的方式进行训练和测试。通过对比不同架构在不同设置下的表现,评估其因果推理能力。
关键创新:论文的关键创新在于强调了编码器架构在因果推理中的优势。与仅解码器模型相比,编码器能够更好地提取输入中的关键信息,并将其编码到潜在空间中,从而减少对表面词汇关系的依赖。此外,论文还通过非自然语言实验,验证了编码器架构在更抽象的推理任务中的泛化能力。
关键设计:论文的关键设计包括:1) 使用微调策略来提升模型的因果推理能力;2) 在自然语言和非自然语言场景下进行实验,以评估模型的泛化能力;3) 对比不同架构在零样本、少样本上下文学习以及微调设置下的表现,以确定最佳的架构和训练策略。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

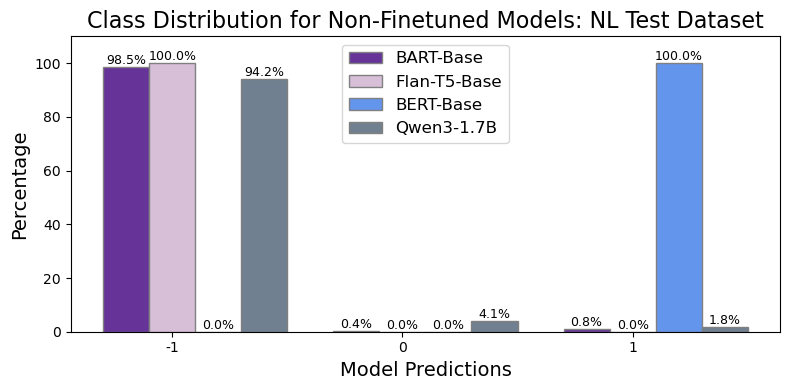
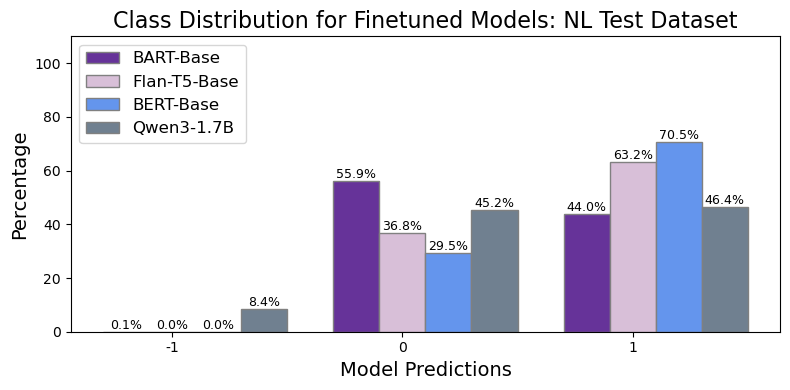
📊 实验亮点
实验结果表明,仅解码器模型在因果推理任务中对分布偏移非常敏感,而微调后的编码器和编码器-解码器模型表现出更强的泛化能力。在非自然语言分割实验中,编码器类模型也展现出优越的性能。仅当模型规模足够大时,仅解码器模型才能与编码器类模型相媲美或超越。
🎯 应用场景
该研究成果可应用于需要可靠因果推理的领域,如医疗诊断、金融风险评估、智能决策支持系统等。通过采用编码器或编码器-解码器架构,并进行针对性微调,可以构建更鲁棒、更可靠的因果推理模型,从而提高决策的准确性和可靠性,并降低风险。
📄 摘要(原文)
In context learning (ICL) underpins recent advances in large language models (LLMs), although its role and performance in causal reasoning remains unclear. Causal reasoning demands multihop composition and strict conjunctive control, and reliance on spurious lexical relations of the input could provide misleading results. We hypothesize that, due to their ability to project the input into a latent space, encoder and encoder decoder architectures are better suited for said multihop conjunctive reasoning versus decoder only models. To do this, we compare fine-tuned versions of all the aforementioned architectures with zero and few shot ICL in both natural language and non natural language scenarios. We find that ICL alone is insufficient for reliable causal reasoning, often overfocusing on irrelevant input features. In particular, decoder only models are noticeably brittle to distributional shifts, while finetuned encoder and encoder decoder models can generalize more robustly across our tests, including the non natural language split. Both architectures are only matched or surpassed by decoder only architectures at large scales. We conclude by noting that for cost effective, short horizon robust causal reasoning, encoder or encoder decoder architectures with targeted finetuning are preferable.