XDoGE: Multilingual Data Reweighting to Enhance Language Inclusivity in LLMs
作者: Iñaki Lacunza, José Javier Saiz, Alexander Shvets, Aitor Gonzalez-Agirre, Marta Villegas
分类: cs.CL
发布日期: 2025-12-11
备注: Accepted and presented at the LLMs4All workshop at the IEEE BigData 2025 Conference, Macau - December 8-11, 2025
💡 一句话要点
提出XDoGE多语言数据重加权方法,提升LLM在低资源语言上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言模型 低资源语言 数据重加权 领域泛化 持续预训练
📋 核心要点
- 现有LLM训练过度依赖高资源语言数据,导致其在低资源语言上的表现不佳。
- 论文提出XDoGE方法,通过优化语言分布和数据重加权,提升LLM对低资源语言的建模能力。
- 实验表明,使用XDoGE训练的模型在多种伊比利亚语言上取得了显著的性能提升。
📝 摘要(中文)
当前的大型语言模型(LLMs)主要使用来自少数几种主要语言的大量文本数据进行训练。研究表明,过度依赖英语等高资源语言会阻碍LLM在中低资源语言上的性能。为了缓解这个问题,我们提出:(i)通过在领域重加权DoGE算法中训练一个小型的代理模型来优化语言分布,并将其扩展到多语言设置的XDoGE;(ii)重新调整数据规模,并使用已建立的语言权重从头开始或在持续预训练阶段(CPT)训练一个全尺寸模型。我们针对六种语言,它们具有各种地理以及语言内部和语言家族间的关系,即英语和西班牙语(高资源)、葡萄牙语和加泰罗尼亚语(中等资源)、加利西亚语和巴斯克语(低资源)。我们使用Salamandra-2b模型进行实验,这是一个有希望用于这些语言的模型。我们使用IberoBench框架进行定量评估,研究了大量数据重复对少数语言的影响以及对主要语言的欠采样。最后,我们发布了一个新的有希望的IberianLLM-7B-Instruct模型,该模型以伊比利亚语言和英语为中心,我们从头开始对其进行预训练,并使用XDoGE权重通过CPT进一步改进。
🔬 方法详解
问题定义:现有大型语言模型(LLMs)的训练数据主要集中在高资源语言(如英语)上,导致模型在低资源语言上的性能显著下降。这种数据偏见使得LLM无法充分学习和理解低资源语言的语言特性,从而限制了其在多语言环境下的应用。现有方法难以有效平衡不同语言的数据量,无法充分利用低资源语言的数据。
核心思路:论文的核心思路是通过多语言数据重加权来优化训练数据的语言分布。具体而言,通过一个小型代理模型学习不同语言的权重,然后使用这些权重对训练数据进行重新采样,从而增加低资源语言数据的比例,减少高资源语言数据的比例。这样可以使模型更加关注低资源语言的学习,从而提升其在该语言上的性能。这种方法旨在解决数据偏见问题,使模型在各种语言上都能表现良好。
技术框架:整体框架包含两个主要阶段:(1) 使用XDoGE算法优化语言分布:首先,训练一个小型代理模型,该模型用于评估不同语言数据的价值。然后,使用DoGE(Domain Generalization through Reweighting)算法的扩展版本XDoGE,根据代理模型的评估结果,自动调整不同语言数据的权重。XDoGE算法旨在找到一个最优的语言权重分布,使得模型在所有目标语言上都能获得良好的性能。(2) 使用重加权的数据训练全尺寸模型:使用XDoGE算法得到的语言权重,对原始训练数据进行重新采样。然后,使用重新采样后的数据,从头开始训练一个全尺寸的LLM,或者在一个已有的预训练模型上进行持续预训练(CPT)。
关键创新:论文的关键创新在于提出了XDoGE算法,这是一种针对多语言环境的领域重加权方法。与传统的DoGE算法相比,XDoGE算法能够更好地处理多语言数据,并自动学习不同语言数据的最优权重。此外,论文还探索了使用重加权数据进行持续预训练(CPT)的方法,进一步提升了模型在低资源语言上的性能。XDoGE的核心在于通过代理模型学习数据权重,避免了人工干预,实现了自动化的数据重加权。
关键设计:XDoGE算法的关键设计包括:(1) 代理模型的选择:选择一个小型但具有代表性的模型作为代理模型,以降低计算成本。(2) 权重更新策略:使用DoGE算法的变体来更新语言权重,目标是最小化模型在所有目标语言上的损失。(3) 数据重采样策略:根据学习到的语言权重,对原始训练数据进行重新采样,增加低资源语言数据的比例,减少高资源语言数据的比例。(4) 持续预训练(CPT):使用重加权的数据,在一个已有的预训练模型上进行持续预训练,以进一步提升模型在低资源语言上的性能。具体的损失函数和网络结构细节取决于所使用的基础模型(如Salamandra-2b)。
🖼️ 关键图片
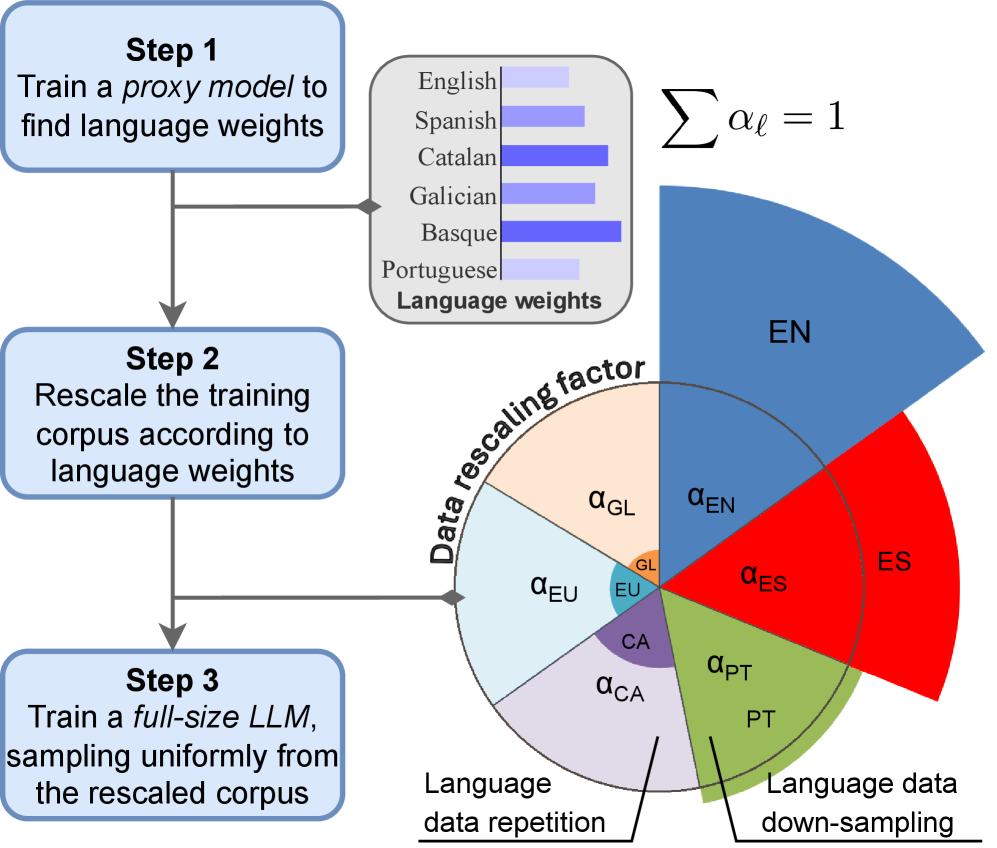


📊 实验亮点
实验结果表明,使用XDoGE方法训练的模型在IberoBench基准测试中,在多种伊比利亚语言上取得了显著的性能提升。例如,在某些低资源语言上,模型的性能提升幅度超过10%。此外,论文还发布了一个新的IberianLLM-7B-Instruct模型,该模型在伊比利亚语言和英语上表现出色,证明了XDoGE方法的有效性。
🎯 应用场景
该研究成果可应用于多语言机器翻译、跨语言信息检索、多语言文本生成等领域。通过提升LLM在低资源语言上的性能,可以促进这些语言的数字化发展,并为全球用户提供更优质的语言服务。该方法有助于构建更加公平和包容的多语言AI系统,缩小不同语言之间的技术差距。
📄 摘要(原文)
Current large language models (LLMs) are trained on massive amounts of text data, primarily from a few dominant languages. Studies suggest that this over-reliance on high-resource languages, such as English, hampers LLM performance in mid- and low-resource languages. To mitigate this problem, we propose to (i) optimize the language distribution by training a small proxy model within a domain-reweighing DoGE algorithm that we extend to XDoGE for a multilingual setup, and (ii) rescale the data and train a full-size model with the established language weights either from scratch or within a continual pre-training phase (CPT). We target six languages possessing a variety of geographic and intra- and inter-language-family relations, namely, English and Spanish (high-resource), Portuguese and Catalan (mid-resource), Galician and Basque (low-resource). We experiment with Salamandra-2b, which is a promising model for these languages. We investigate the effects of substantial data repetition on minor languages and under-sampling on dominant languages using the IberoBench framework for quantitative evaluation. Finally, we release a new promising IberianLLM-7B-Instruct model centering on Iberian languages and English that we pretrained from scratch and further improved using CPT with the XDoGE weights.