Complexity Agnostic Recursive Decomposition of Thoughts
作者: Kaleem Ullah Qasim, Jiashu Zhang, Hafiz Saif Ur Rehman
分类: cs.CL, cs.AI, cs.IT
发布日期: 2025-12-10
备注: 4
💡 一句话要点
提出CARD框架,通过预判问题复杂度自适应分解思路,提升大语言模型推理效率与准确率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 多步推理 复杂度估计 递归分解 自适应推理
📋 核心要点
- 现有大语言模型在多步推理中表现欠佳,主要原因是其推理策略固定,无法适应不同问题的难度。
- CARD框架通过预先估计问题复杂度,自适应地调整问题分解策略,从而优化推理过程。
- 实验表明,CARD在提升推理准确率的同时,显著降低了token使用量,提高了推理效率。
📝 摘要(中文)
大型语言模型在多步推理任务中表现不佳,原因在于其固定的推理策略忽略了问题的具体难度。本文提出了复杂性无关的递归分解框架CARD,该框架在生成答案之前预测问题复杂度,并据此调整分解策略。CARD包含多维推理复杂度估计器MRCE,这是一个0.6B的Qwen模型,用于从问题文本中预测30个细粒度特征。CARD还包含一个两阶段递归求解器:(1) 基于任务特征进行分层分解为K步;(2) 通过递归MRCE分析,为每一步分配不同的思考预算(1, 5-9, 或10个思路)。在GSM8K数据集上,CARD使用Qwen3-0.6B、DeepSeek-R1-Distill-Qwen-1.5B和Qwen3-1.7B模型进行评估,实现了81.4%到89.2%的准确率,同时相比于固定分解基线,token成本降低了1.88倍到2.40倍。在MATH-500数据集上,CARD达到了75.1%到86.8%的准确率,使用的token数量减少了1.71倍到5.74倍。实验结果表明,预先进行复杂度估计能够显著提高准确率并提升效率。
🔬 方法详解
问题定义:现有大语言模型在解决多步推理问题时,通常采用固定的推理步骤和计算资源分配,无法根据问题的实际难度进行调整。这种固定策略导致简单问题资源浪费,复杂问题则因资源不足而失败。因此,如何根据问题复杂度动态调整推理策略是亟待解决的问题。
核心思路:CARD的核心思路是在推理之前,先对问题的复杂度进行估计,然后根据估计结果自适应地调整推理过程。具体来说,CARD通过一个专门的复杂度估计器MRCE来预测问题的多个维度的复杂度特征,并利用这些特征来指导问题的分解和每一步的计算资源分配。这种自适应的方法能够更有效地利用计算资源,提高推理的准确率和效率。
技术框架:CARD框架主要包含两个核心模块:多维推理复杂度估计器(MRCE)和两阶段递归求解器。首先,MRCE模型(基于Qwen)分析问题文本,预测30个细粒度的复杂度特征。然后,两阶段递归求解器首先根据任务特征将问题分层分解为K个步骤,接着通过递归调用MRCE,为每个步骤分配不同的思考预算(即token数量)。整个过程是一个递归的分解和求解过程,直到问题被完全解决。
关键创新:CARD的关键创新在于引入了预先的复杂度估计机制,并将其与递归分解策略相结合。与传统的固定分解方法相比,CARD能够根据问题的实际难度动态地调整推理过程,从而更有效地利用计算资源。此外,MRCE模型能够预测多个维度的复杂度特征,为更精细的资源分配提供了可能。
关键设计:MRCE模型是一个基于Qwen的0.6B参数模型,通过训练来预测30个细粒度的复杂度特征。两阶段递归求解器中,第一阶段进行分层分解,第二阶段通过递归调用MRCE来分配每一步的思考预算。思考预算被设置为离散值(1, 5-9, 或10),以简化资源分配策略。损失函数的设计旨在优化MRCE的预测精度,并鼓励模型学习到与问题难度相关的特征。
🖼️ 关键图片

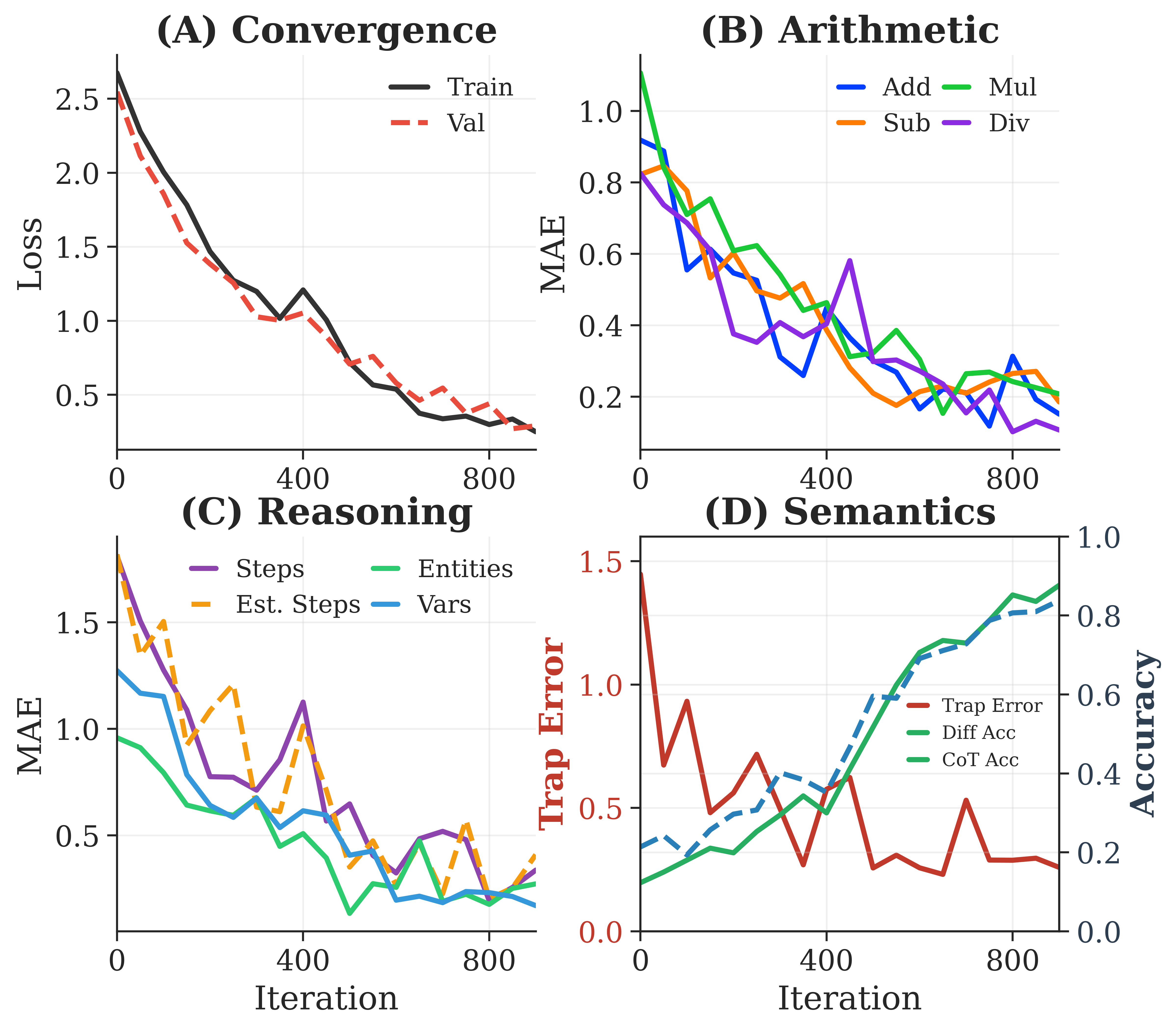
📊 实验亮点
CARD在GSM8K数据集上,使用Qwen3-0.6B、DeepSeek-R1-Distill-Qwen-1.5B和Qwen3-1.7B模型,实现了81.4%到89.2%的准确率,同时相比于固定分解基线,token成本降低了1.88倍到2.40倍。在MATH-500数据集上,CARD达到了75.1%到86.8%的准确率,使用的token数量减少了1.71倍到5.74倍。这些结果表明,CARD在提升准确率的同时,显著降低了计算成本。
🎯 应用场景
CARD框架可应用于各种需要复杂推理的场景,例如数学问题求解、代码生成、知识图谱推理等。通过自适应地调整推理策略,CARD能够提高这些任务的准确率和效率,降低计算成本。未来,该框架有望应用于智能客服、教育辅导等领域,提升人工智能系统的智能化水平。
📄 摘要(原文)
Large language models often fail on multi-step reasoning due to fixed reasoning strategies that ignore problem specific difficulty. We introduce CARD (Complexity Agnostic Recursive Decomposition), a framework that predicts problem complexity before generation and adapts decomposition accordingly. Our system comprises MRCE (Multi-dimensional Reasoning Complexity Estimator), a 0.6B Qwen model predicting 30 fine-grained features from question text and a two-stage recursive solver: (1) hierarchical decomposition into K steps based on task profile and (2) per-step thought budget allocation (1, 5-9, or 10 thoughts) via recursive MRCE profiling. Evaluated on three reasoning models (Qwen3-0.6B, DeepSeek-R1-Distill-Qwen-1.5B, Qwen3-1.7B), CARD achieves 81.4% to 89.2% accuracy on GSM8K while reducing token cost by 1.88x to 2.40x compared to fixed decomposition baselines. On MATH-500, CARD reaches 75.1 to 86.8% accuracy using 1.71x to 5.74x fewer tokens. Our results demonstrate that preemptive complexity estimation enables both higher accuracy and significant efficiency gains.