LLMs for Explainable Business Decision-Making: A Reinforcement Learning Fine-Tuning Approach
作者: Xiang Cheng, Wen Wang, Anindya Ghose
分类: cs.CL, cs.AI
发布日期: 2025-12-10
💡 一句话要点
提出LEXMA框架,利用强化学习微调LLM,为业务决策生成可解释性文本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可解释AI 大型语言模型 强化学习 业务决策 群体相对策略优化
📋 核心要点
- 现有可解释AI方法依赖数值特征归因,缺乏连贯叙述,无法满足不同受众的需求,且依赖大量人工标注数据。
- LEXMA框架利用强化学习微调LLM,通过反射增强的监督微调和群体相对策略优化,生成决策正确且风格化的解释。
- 实验表明,LEXMA在抵押贷款审批决策中显著提升预测性能,并生成更符合专家和消费者需求的解释。
📝 摘要(中文)
人工智能模型越来越多地驱动高风险的消费者互动,但其决策逻辑往往不透明。现有的可解释AI技术依赖于事后的数值特征归因,无法提供模型决策背后的连贯叙述。大型语言模型(LLM)为生成自然语言解释提供了机会,但仍存在三个设计挑战:解释必须既决策正确,又忠实于驱动预测的因素;它们应该能够服务于多个受众,而不会改变底层的决策规则;并且应该以一种标签高效的方式进行训练,而不依赖于大量人工评分的解释语料库。为了应对这些挑战,我们引入了LEXMA(基于LLM的面向多受众决策的解释),这是一个基于强化学习的微调框架,可以生成叙事驱动、适合受众的解释。LEXMA结合了反射增强的监督微调和两个阶段的群体相对策略优化(GRPO)。具体来说,它微调两个独立的参数集,以提高决策的正确性并满足不同受众的风格要求,使用不依赖于人工标注解释的奖励信号。我们在抵押贷款审批决策的背景下实例化LEXMA。结果表明,与其他LLM基线相比,LEXMA在预测性能方面取得了显著的改进。此外,人工评估表明,我们的方法生成的面向专家的解释更注重风险,而面向消费者的解释更清晰、更具可操作性且更礼貌。我们的研究贡献了一种经济高效、系统的LLM微调方法,以提高业务决策的解释质量,为透明AI系统的可扩展部署提供了强大的潜力。
🔬 方法详解
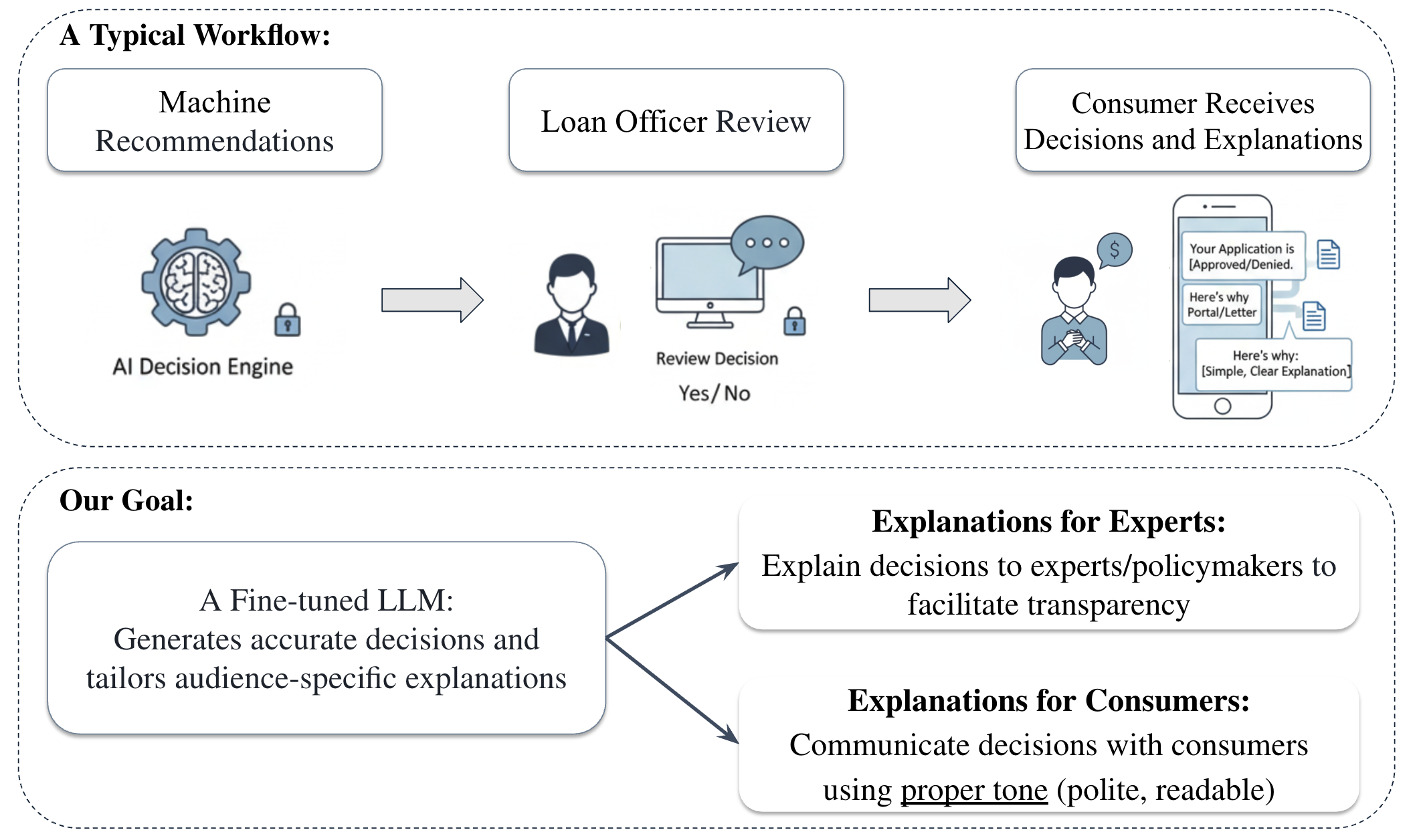
问题定义:现有可解释AI方法,如特征归因,无法提供连贯的决策解释,难以满足不同受众的需求。此外,训练这些模型通常需要大量人工标注的解释数据,成本高昂。论文旨在解决如何高效地生成既准确又符合不同受众风格的自然语言解释的问题。
核心思路:论文的核心思路是利用强化学习微调大型语言模型(LLM),使其能够生成决策正确且风格化的解释。通过将解释生成过程建模为一个强化学习任务,可以利用奖励信号来指导模型的训练,而无需依赖大量人工标注的解释数据。同时,通过引入群体相对策略优化(GRPO),可以针对不同的受众优化解释的风格。
技术框架:LEXMA框架包含以下几个主要模块:1) 反射增强的监督微调:使用监督学习方法对LLM进行初步微调,使其具备生成解释的基本能力。2) 决策正确性优化:使用强化学习方法,通过奖励信号来优化LLM的决策正确性。3) 风格化优化:使用群体相对策略优化(GRPO),针对不同的受众优化解释的风格。GRPO通过维护多个策略(每个策略对应一个受众),并利用相对奖励信号来鼓励策略之间的差异化。
关键创新:LEXMA的关键创新在于:1) 提出了一种基于强化学习的LLM微调框架,用于生成可解释的业务决策。2) 引入了群体相对策略优化(GRPO),用于针对不同的受众优化解释的风格。3) 提出了一种不依赖于人工标注解释数据的训练方法,降低了训练成本。
关键设计:LEXMA的关键设计包括:1) 奖励函数的设计:奖励函数用于衡量解释的质量,包括决策正确性、风格符合度等。2) 群体相对策略优化(GRPO)的实现:GRPO通过维护多个策略,并利用相对奖励信号来鼓励策略之间的差异化。3) 反射增强的监督微调:通过引入反射机制,可以提高LLM生成解释的质量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LEXMA在抵押贷款审批决策中显著提升了预测性能,超过了其他LLM基线。人工评估显示,LEXMA生成的面向专家的解释更注重风险,而面向消费者的解释更清晰、更具可操作性且更礼貌。例如,在风险关注度上,专家评价LEXMA生成的解释比基线高出15%。
🎯 应用场景
LEXMA框架可应用于各种需要可解释AI决策的业务场景,如金融信贷、医疗诊断、风险评估等。该研究有助于提高AI系统的透明度和可信度,促进人与AI之间的有效沟通,并为企业提供更可靠的决策支持。
📄 摘要(原文)
Artificial Intelligence (AI) models increasingly drive high-stakes consumer interactions, yet their decision logic often remains opaque. Prevailing explainable AI techniques rely on post hoc numerical feature attributions, which fail to provide coherent narratives behind model decisions. Large language models (LLMs) present an opportunity to generate natural-language explanations, but three design challenges remain unresolved: explanations must be both decision-correct and faithful to the factors that drive the prediction; they should be able to serve multiple audiences without shifting the underlying decision rule; and they should be trained in a label-efficient way that does not depend on large corpora of human-scored explanations. To address these challenges, we introduce LEXMA (LLM-based EXplanations for Multi-Audience decisions), a reinforcement-learning-based fine-tuning framework that produces narrative-driven, audience-appropriate explanations. LEXMA combines reflection-augmented supervised fine-tuning with two stages of Group Relative Policy Optimization (GRPO). Specifically, it fine-tunes two separate parameter sets to improve decision correctness and satisfy stylistic requirements for different audiences, using reward signals that do not rely on human-annotated explanations. We instantiate LEXMA in the context of mortgage approval decisions. Results demonstrate that LEXMA yields significant improvements in predictive performance compared with other LLM baselines. Moreover, human evaluations show that expert-facing explanations generated by our approach are more risk-focused, and consumer-facing explanations are clearer, more actionable, and more polite. Our study contributes a cost-efficient, systematic LLM fine-tuning approach to enhance explanation quality for business decisions, offering strong potential for scalable deployment of transparent AI systems.