KBQA-R1: Reinforcing Large Language Models for Knowledge Base Question Answering
作者: Xin Sun, Zhongqi Chen, Xing Zheng, Qiang Liu, Shu Wu, Bowen Song, Zilei Wang, Weiqiang Wang, Liang Wang
分类: cs.CL
发布日期: 2025-12-10 (更新: 2026-01-09)
💡 一句话要点
提出KBQA-R1框架,通过强化学习优化LLM在知识库问答中的推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识库问答 大型语言模型 强化学习 群体相对策略优化 参考拒绝采样
📋 核心要点
- 现有KBQA方法要么生成幻觉查询,要么进行僵化的模板推理,缺乏对知识库环境的真正理解。
- KBQA-R1框架将KBQA视为多轮决策过程,通过强化学习优化LLM与知识库的交互策略。
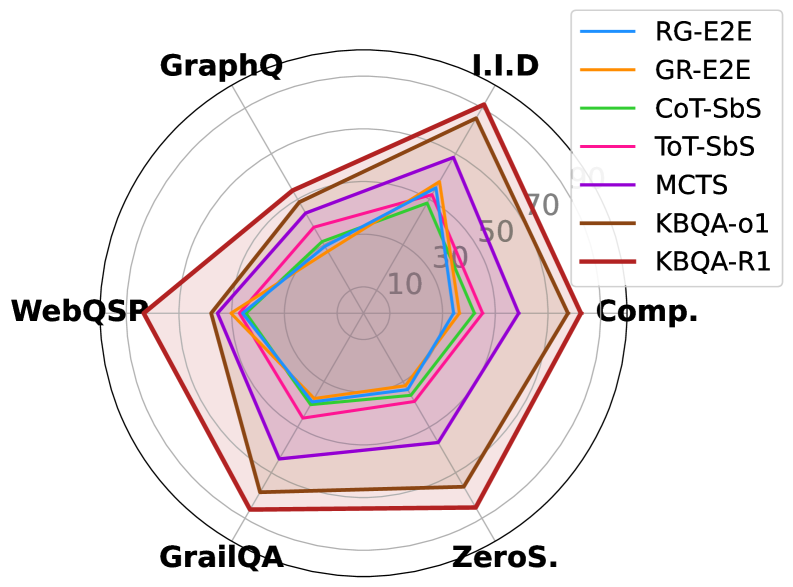
- KBQA-R1在WebQSP、GrailQA和GraphQuestions等数据集上取得了SOTA性能,验证了其有效性。
📝 摘要(中文)
知识库问答(KBQA)旨在弥合自然语言和严格知识图谱模式之间的差距,通过生成可执行的逻辑形式来实现。大型语言模型(LLM)虽然推动了该领域的发展,但现有方法常面临失败的两难境地:要么生成未经模式验证的幻觉查询,要么表现出僵化的、基于模板的推理,模仿合成轨迹而缺乏对环境的真正理解。为了解决这些局限性,我们提出了KBQA-R1,该框架将范式从文本模仿转变为通过强化学习进行交互优化。将KBQA视为一个多轮决策过程,我们的模型学习使用一系列动作来导航知识库,利用群体相对策略优化(GRPO)来根据具体的执行反馈而不是静态监督来改进其策略。此外,我们引入了参考拒绝采样(RRS),这是一种数据合成方法,通过严格地将推理轨迹与真实动作序列对齐来解决冷启动挑战。在WebQSP、GrailQA和GraphQuestions上的大量实验表明,KBQA-R1实现了最先进的性能,有效地将LLM推理建立在可验证的执行基础上。
🔬 方法详解
问题定义:KBQA旨在利用自然语言查询知识库,生成可执行的逻辑形式以获得答案。现有方法,特别是基于大型语言模型的方法,存在两个主要问题:一是容易产生幻觉,生成在知识库中不存在的查询;二是依赖模板,缺乏对知识库的真正理解,无法灵活应对复杂问题。
核心思路:KBQA-R1的核心思路是将KBQA任务建模成一个多轮决策过程,利用强化学习来优化LLM与知识库的交互策略。通过与知识库的交互,模型可以获得执行反馈,从而更好地学习如何生成正确的查询。这种方法避免了对静态监督数据的过度依赖,使模型能够更好地适应不同的知识库和问题。
技术框架:KBQA-R1的整体框架包含以下几个主要模块:1) LLM作为策略网络,负责根据当前状态(问题和知识库信息)生成动作(查询);2) 知识库执行器,负责执行LLM生成的查询,并返回执行结果;3) 强化学习算法,负责根据执行结果更新LLM的策略。具体流程是:给定一个问题,LLM生成一个查询,知识库执行器执行该查询,并将结果反馈给LLM,LLM根据反馈调整策略,重复这个过程直到找到答案或达到最大步数。
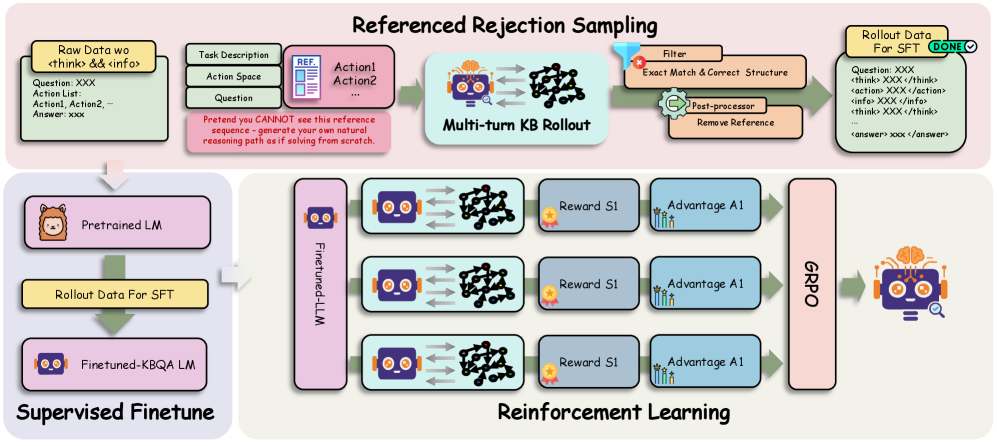
关键创新:KBQA-R1的关键创新点在于以下两个方面:1) 使用强化学习来优化LLM与知识库的交互策略,避免了对静态监督数据的过度依赖;2) 提出了群体相对策略优化(GRPO)方法,用于更有效地利用执行反馈来更新LLM的策略。此外,还提出了参考拒绝采样(RRS)方法,用于解决冷启动问题,即在没有足够训练数据的情况下,如何训练LLM。
关键设计:KBQA-R1的关键设计包括:1) 使用群体相对策略优化(GRPO)算法,该算法通过比较不同策略的性能来更有效地利用执行反馈;2) 引入参考拒绝采样(RRS)方法,通过严格对齐推理轨迹与真实动作序列来合成高质量的训练数据,解决冷启动问题;3) 将KBQA建模为多轮决策过程,允许模型逐步探索知识库,从而更好地解决复杂问题。
🖼️ 关键图片

📊 实验亮点
KBQA-R1在WebQSP、GrailQA和GraphQuestions三个benchmark数据集上均取得了state-of-the-art的结果。例如,在GrailQA数据集上,KBQA-R1的性能显著优于之前的最佳模型,证明了其在复杂知识库问答任务上的有效性。实验结果表明,通过强化学习优化LLM的交互策略,可以显著提升KBQA的性能。
🎯 应用场景
KBQA-R1具有广泛的应用前景,包括智能问答系统、知识图谱构建与维护、以及基于知识的决策支持系统。该研究能够提升问答系统的准确性和可靠性,减少幻觉现象,并促进知识图谱的自动化构建和完善。未来,该技术有望应用于医疗、金融、教育等多个领域,为用户提供更智能、更精准的信息服务。
📄 摘要(原文)
Knowledge Base Question Answering (KBQA) challenges models to bridge the gap between natural language and strict knowledge graph schemas by generating executable logical forms. While Large Language Models (LLMs) have advanced this field, current approaches often struggle with a dichotomy of failure: they either generate hallucinated queries without verifying schema existence or exhibit rigid, template-based reasoning that mimics synthesized traces without true comprehension of the environment. To address these limitations, we present \textbf{KBQA-R1}, a framework that shifts the paradigm from text imitation to interaction optimization via Reinforcement Learning. Treating KBQA as a multi-turn decision process, our model learns to navigate the knowledge base using a list of actions, leveraging Group Relative Policy Optimization (GRPO) to refine its strategies based on concrete execution feedback rather than static supervision. Furthermore, we introduce \textbf{Referenced Rejection Sampling (RRS)}, a data synthesis method that resolves cold-start challenges by strictly aligning reasoning traces with ground-truth action sequences. Extensive experiments on WebQSP, GrailQA, and GraphQuestions demonstrate that KBQA-R1 achieves state-of-the-art performance, effectively grounding LLM reasoning in verifiable execution.