MedBioRAG: Semantic Search and Retrieval-Augmented Generation with Large Language Models for Medical and Biological QA
作者: Seonok Kim
分类: cs.CL, cs.AI
发布日期: 2025-12-10
备注: Submitted to ACL 2025. 9 pages, 4 figures, 5 tables (including 2 appendix tables)
💡 一句话要点
MedBioRAG:利用大型语言模型进行医学和生物问答的语义搜索和检索增强生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生物医学问答 检索增强生成 语义搜索 大型语言模型 医学信息检索
📋 核心要点
- 现有生物医学问答系统在处理复杂问题时,缺乏对相关信息的有效检索和利用,导致答案质量不高。
- MedBioRAG结合语义和词汇搜索,高效检索生物医学文档,并利用大型语言模型生成上下文感知的答案。
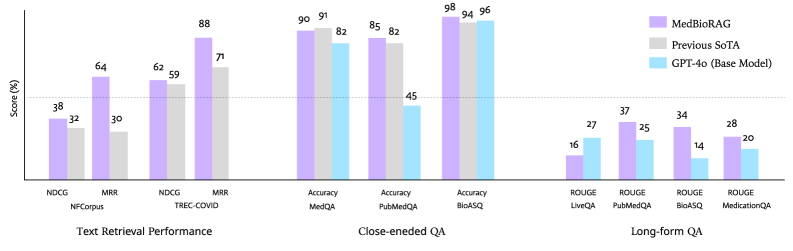
- 实验表明,MedBioRAG在多个生物医学QA数据集上超越了现有SOTA模型和GPT-4o,显著提升了检索和问答性能。
📝 摘要(中文)
本文介绍了一种名为MedBioRAG的检索增强模型,旨在通过结合语义和词汇搜索、文档检索以及监督微调来提高生物医学问答(QA)的性能。MedBioRAG能够高效地检索和排序相关的生物医学文档,从而实现精确且上下文感知的响应生成。我们在文本检索、封闭式QA和长篇QA任务上,使用NFCorpus、TREC-COVID、MedQA、PubMedQA和BioASQ等基准数据集对MedBioRAG进行了评估。实验结果表明,MedBioRAG在所有评估任务中均优于先前的最先进(SoTA)模型和GPT-4o基础模型。值得注意的是,我们的方法提高了文档检索的NDCG和MRR分数,同时在封闭式QA中实现了更高的准确率,并在长篇QA中实现了更高的ROUGE分数。我们的研究结果突出了基于语义搜索的检索和LLM微调在生物医学应用中的有效性。
🔬 方法详解
问题定义:现有生物医学问答系统面临的挑战在于如何从海量的医学文献中准确、高效地检索到与问题相关的知识,并利用这些知识生成高质量的答案。传统的词汇搜索方法无法理解问题的语义信息,导致检索结果不准确。此外,直接使用大型语言模型进行问答,由于缺乏领域知识,容易产生幻觉或不准确的答案。
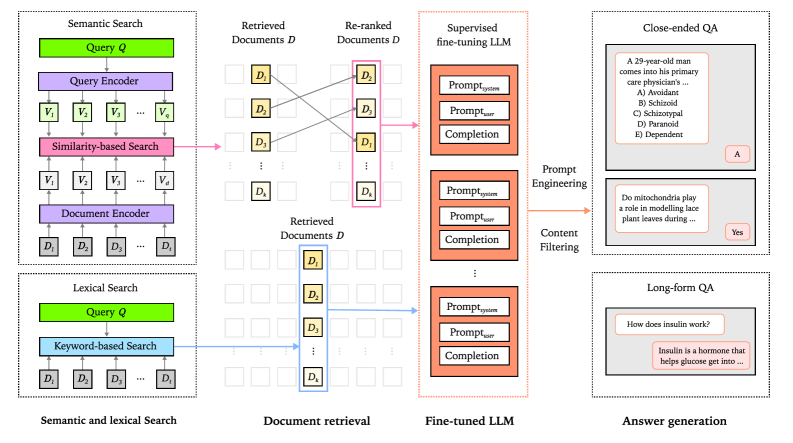
核心思路:MedBioRAG的核心思路是结合语义搜索和检索增强生成(RAG)技术,利用语义搜索技术更准确地检索相关文档,然后利用检索到的文档作为上下文,指导大型语言模型生成答案。这种方法既能提高检索的准确性,又能增强语言模型的领域知识,从而提高问答的质量。
技术框架:MedBioRAG的整体框架包括以下几个主要模块:1) 查询编码器:将用户问题编码成语义向量。2) 文档索引:构建生物医学文档的向量索引。3) 检索模块:利用查询向量在文档索引中检索相关文档。4) 语言模型:利用检索到的文档作为上下文,生成答案。5) 微调模块:使用生物医学问答数据集对整个模型进行微调。
关键创新:MedBioRAG的关键创新在于结合了语义搜索和检索增强生成,并针对生物医学领域进行了优化。与传统的词汇搜索方法相比,语义搜索能够更好地理解问题的语义信息,从而提高检索的准确性。此外,通过对大型语言模型进行微调,可以使其更好地适应生物医学领域的问答任务。
关键设计:MedBioRAG的关键设计包括:1) 使用预训练的生物医学语言模型作为查询编码器和语言模型。2) 使用余弦相似度作为检索的相似度度量。3) 使用对比学习损失函数对查询编码器进行微调,以提高语义搜索的准确性。4) 使用交叉熵损失函数对语言模型进行微调,以提高问答的准确性。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
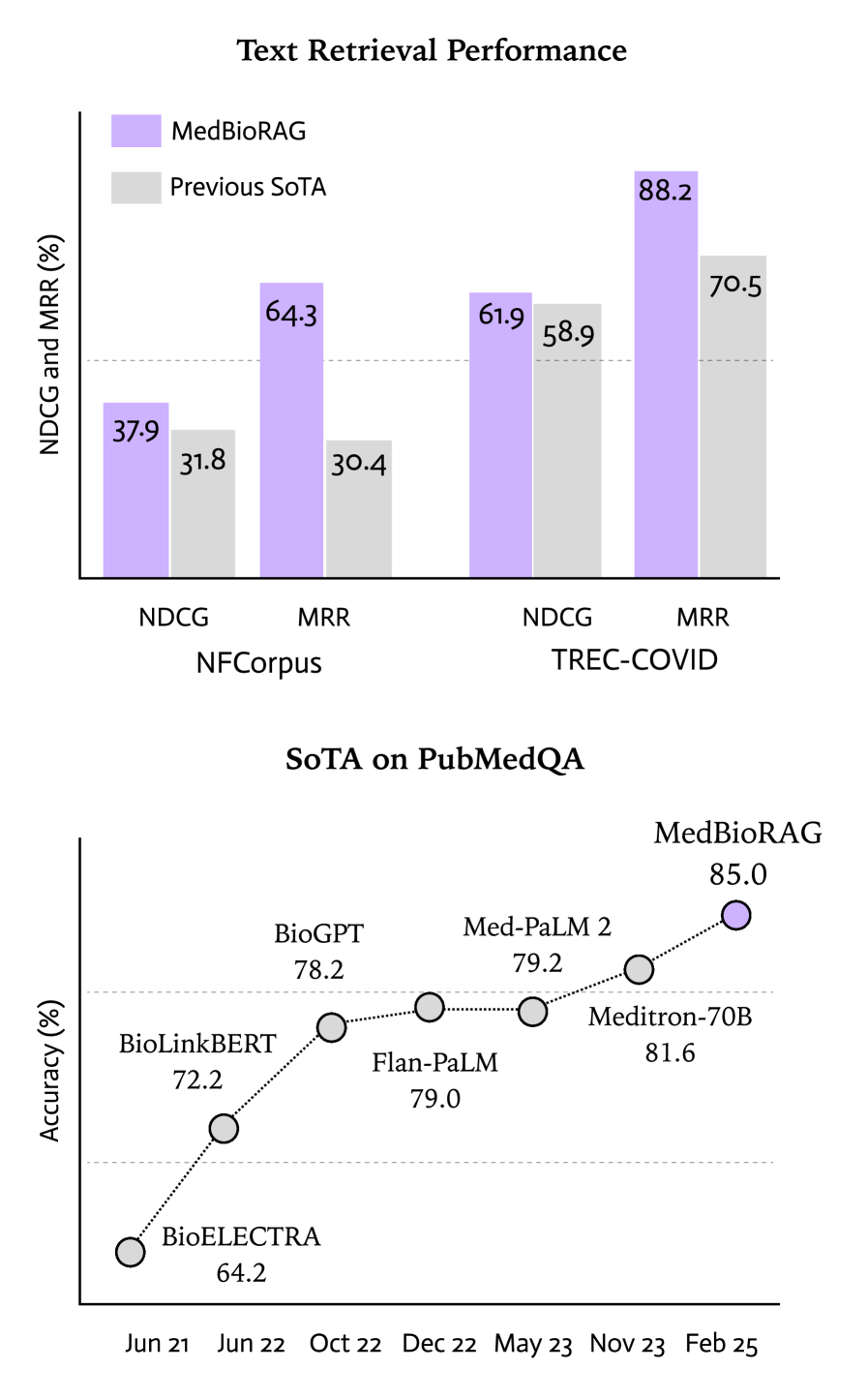
MedBioRAG在NFCorpus、TREC-COVID、MedQA、PubMedQA和BioASQ等多个生物医学QA数据集上进行了评估,实验结果表明,MedBioRAG在所有评估任务中均优于先前的SOTA模型和GPT-4o基础模型。例如,在文档检索任务中,MedBioRAG显著提高了NDCG和MRR分数。在封闭式QA任务中,MedBioRAG实现了更高的准确率。在长篇QA任务中,MedBioRAG实现了更高的ROUGE分数。
🎯 应用场景
MedBioRAG在医疗诊断辅助、医学研究、药物研发等领域具有广泛的应用前景。它可以帮助医生快速检索相关医学文献,辅助诊断和治疗决策。同时,也可以帮助研究人员快速了解最新的研究进展,加速科研进程。此外,MedBioRAG还可以用于构建智能医学问答系统,为患者提供个性化的健康咨询服务。
📄 摘要(原文)
Recent advancements in retrieval-augmented generation (RAG) have significantly enhanced the ability of large language models (LLMs) to perform complex question-answering (QA) tasks. In this paper, we introduce MedBioRAG, a retrieval-augmented model designed to improve biomedical QA performance through a combination of semantic and lexical search, document retrieval, and supervised fine-tuning. MedBioRAG efficiently retrieves and ranks relevant biomedical documents, enabling precise and context-aware response generation. We evaluate MedBioRAG across text retrieval, close-ended QA, and long-form QA tasks using benchmark datasets such as NFCorpus, TREC-COVID, MedQA, PubMedQA, and BioASQ. Experimental results demonstrate that MedBioRAG outperforms previous state-of-the-art (SoTA) models and the GPT-4o base model in all evaluated tasks. Notably, our approach improves NDCG and MRR scores for document retrieval, while achieving higher accuracy in close-ended QA and ROUGE scores in long-form QA. Our findings highlight the effectiveness of semantic search-based retrieval and LLM fine-tuning in biomedical applications.