Mitigating Social Bias in English and Urdu Language Models Using PRM-Guided Candidate Selection and Sequential Refinement
作者: Muneeb Ur Raheem Khan
分类: cs.CL
发布日期: 2025-12-10
💡 一句话要点
提出PRM引导的候选选择与序列精炼方法,缓解英乌语言模型中的社会偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社会偏见缓解 大型语言模型 低资源语言 偏好排序模型 推理时干预
📋 核心要点
- 现有大型语言模型在处理社会敏感语言时,容易产生偏见和刻板印象,尤其是在低资源语言中,训练数据不足加剧了这一问题。
- 论文提出一种基于偏好排序模型(PRM)的推理时偏见缓解策略,无需重新训练或微调,直接作用于模型输出,降低偏见。
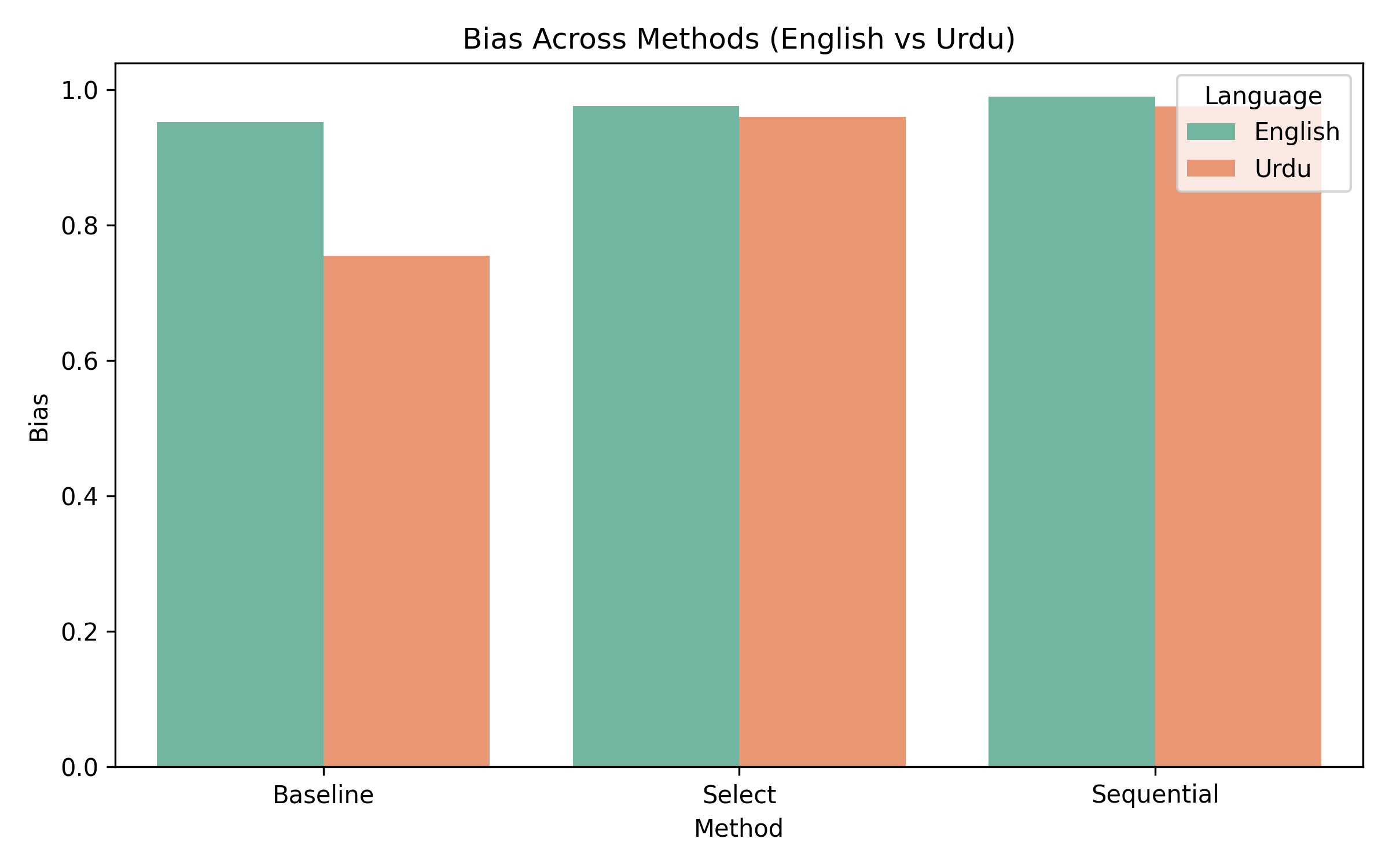
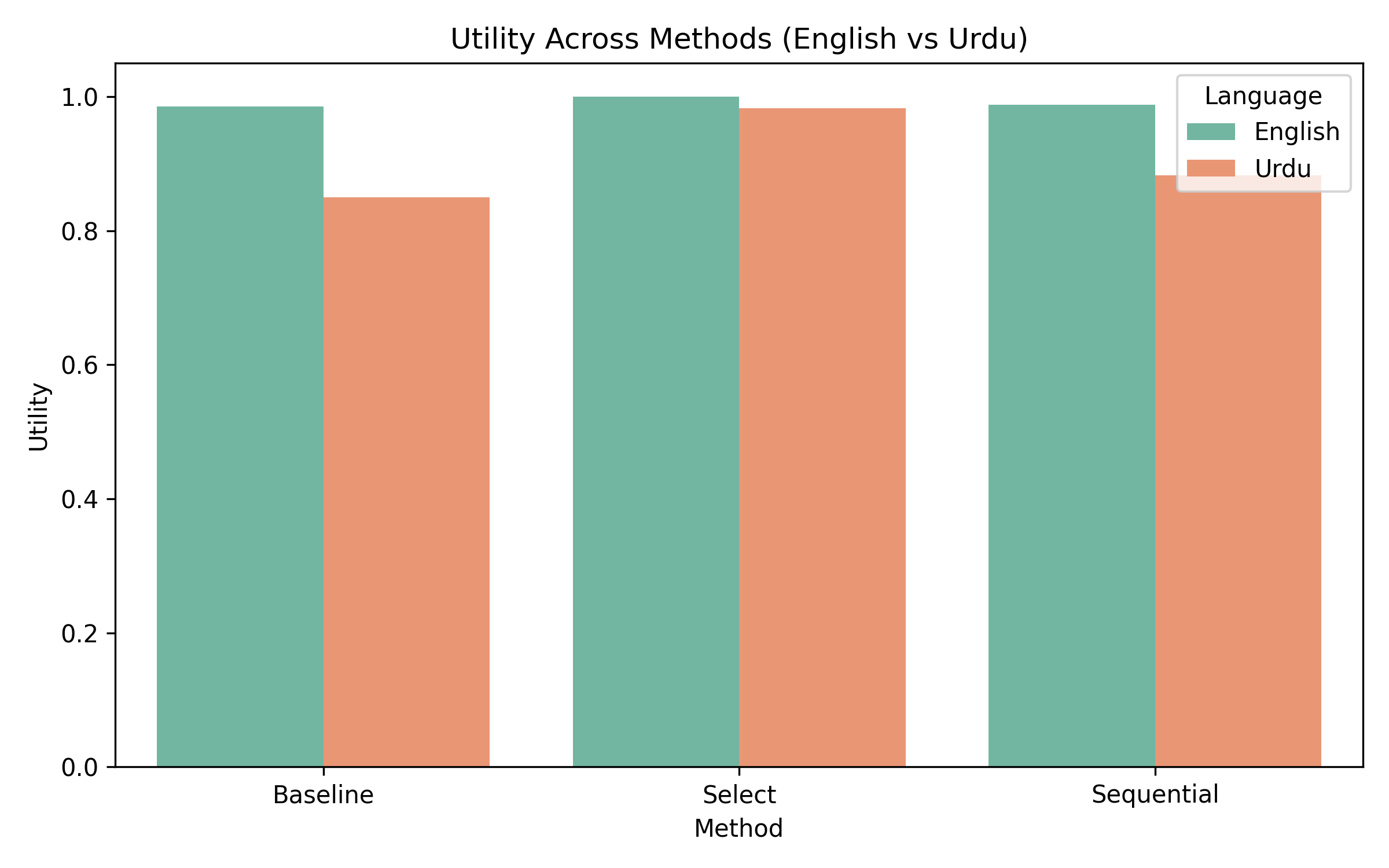
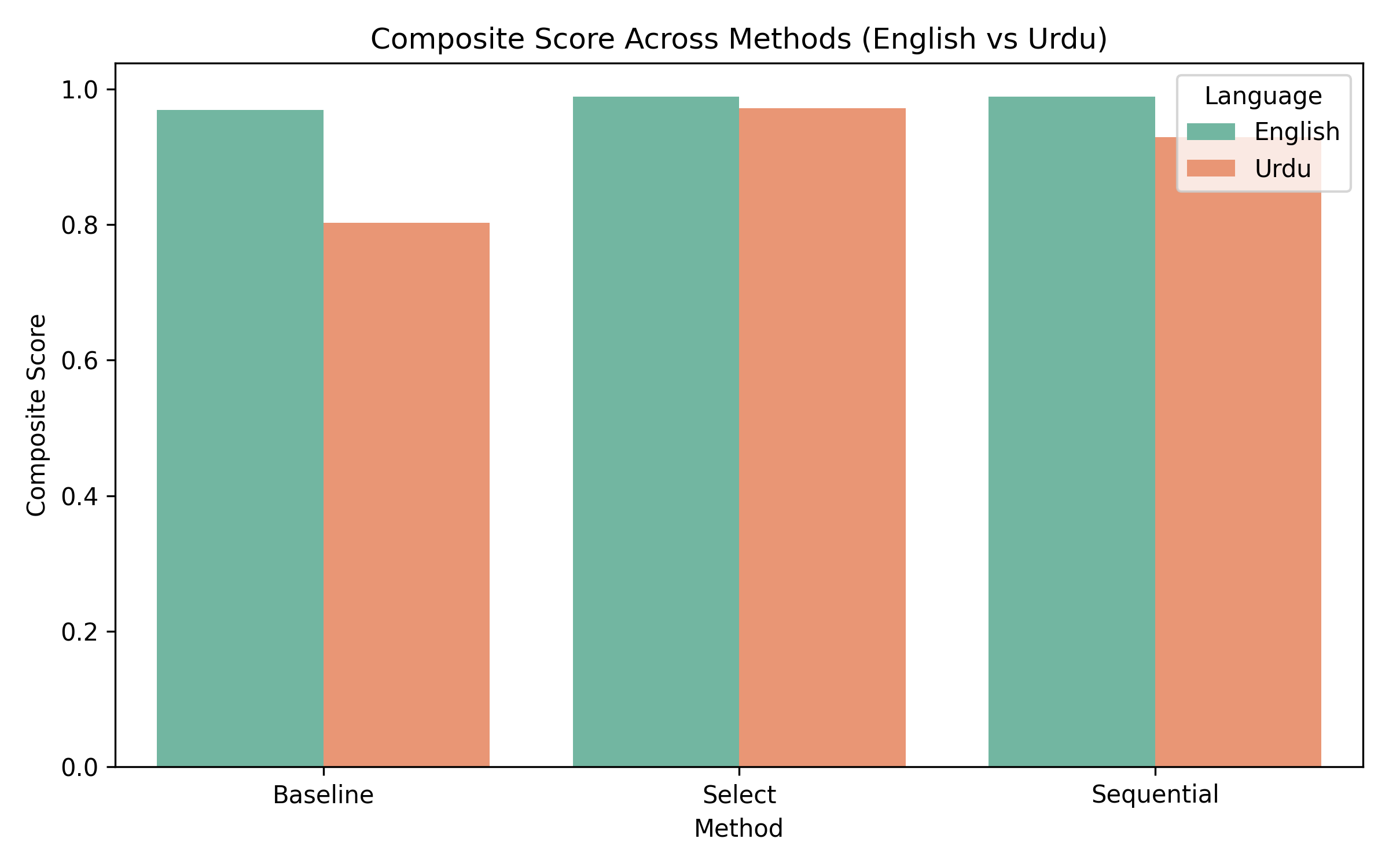
- 实验结果表明,该方法在英语和乌尔都语中均能有效降低偏见,但乌尔都语的公平性得分仍然较低,揭示了多语言模型训练中的结构性不平等。
📝 摘要(中文)
大型语言模型(LLM)日益影响人类交流、决策支持、内容创作和信息检索。尽管这些系统表现出令人印象深刻的流畅性,但它们经常产生带有偏见或刻板印象的内容,尤其是在使用社会敏感语言提示时。越来越多的研究表明,这种偏见对低资源语言的影响尤为严重,因为这些语言的训练数据有限且缺乏文化代表性。本文提出了一项关于推理时偏见缓解的综合研究,该策略避免了重新训练或微调,而是直接作用于模型输出。基于偏好排序模型(PRM),我们引入了一个统一的评估框架,比较了三种方法:(1)基线单字生成,(2)PRM-Select最佳N采样,以及(3)PRM批判指导的PRM-Sequential精炼。我们使用GPT-3.5作为候选生成器,GPT-4o-mini作为基于PRM的偏见和效用评分器,在200个英语提示及其乌尔都语对应提示上评估这些技术,这些提示旨在反映与性别、种族、宗教、国籍、残疾、职业、年龄和社会经济类别相关的社会文化背景。我们的研究结果表明:(a)两种语言的性能均优于基线;(b)所有方法中,乌尔都语的公平性得分始终较低,突出了多语言LLM训练中的结构性不平等;以及(c)PRM-Select和PRM-Sequential之间存在明显的改进轨迹。该研究贡献了一种可扩展的方法、可解释的指标和跨语言比较,可以支持未来在低资源语言中进行公平性评估的工作。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在生成文本时存在的社会偏见问题,尤其是在低资源语言(如乌尔都语)中,由于训练数据不足和文化代表性缺失,偏见问题更加严重。现有方法通常需要重新训练或微调模型,计算成本高昂且难以推广。
核心思路:论文的核心思路是在推理阶段,利用偏好排序模型(PRM)对候选文本进行排序和选择,从而降低模型输出中的偏见。通过PRM对候选文本的偏见程度和效用进行评分,选择偏见较低且效用较高的文本,或者通过PRM的批判指导,对文本进行序列精炼,逐步降低偏见。
技术框架:整体框架包含以下几个主要阶段:1) 使用GPT-3.5等大型语言模型生成多个候选文本;2) 使用GPT-4o-mini作为PRM,对候选文本的偏见程度和效用进行评分;3) 基于PRM的评分,采用PRM-Select或PRM-Sequential方法选择或精炼文本。PRM-Select选择评分最高的候选文本,PRM-Sequential则根据PRM的批判,逐步对文本进行修改,降低偏见。
关键创新:该方法最重要的创新点在于提出了一种基于PRM的推理时偏见缓解策略,无需重新训练或微调模型,即可有效降低模型输出中的偏见。此外,论文还提出了一个统一的评估框架,用于比较不同偏见缓解方法的效果,并进行了跨语言的比较分析。
关键设计:论文的关键设计包括:1) 使用GPT-4o-mini作为PRM,评估候选文本的偏见程度和效用;2) 设计了PRM-Select和PRM-Sequential两种不同的偏见缓解方法;3) 构建了一个包含200个英语和乌尔都语提示的数据集,用于评估不同方法的性能。在实验中,使用了GPT-3.5生成候选文本,并使用GPT-4o-mini作为PRM进行评分和指导。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PRM-Select和PRM-Sequential方法在英语和乌尔都语中均能有效降低偏见,且性能优于基线方法。尽管如此,乌尔都语的公平性得分始终低于英语,揭示了多语言模型训练中存在的结构性不平等。PRM-Sequential方法在某些情况下表现优于PRM-Select,表明序列精炼策略的有效性。
🎯 应用场景
该研究成果可应用于各种自然语言处理任务中,例如机器翻译、文本摘要、对话系统等,尤其是在处理社会敏感话题时,可以有效降低模型输出中的偏见,提高模型的公平性和可靠性。此外,该方法还可以推广到其他低资源语言中,帮助构建更加公平和包容的语言模型。
📄 摘要(原文)
Large language models (LLMs) increasingly mediate human communication, decision support, content creation, and information retrieval. Despite impressive fluency, these systems frequently produce biased or stereotypical content, especially when prompted with socially sensitive language. A growing body of research has demonstrated that such biases disproportionately affect low-resource languages, where training data is limited and culturally unrepresentative. This paper presents a comprehensive study of inference-time bias mitigation, a strategy that avoids retraining or fine-tuning and instead operates directly on model outputs. Building on preference-ranking models (PRMs), we introduce a unified evaluation framework comparing three methods: (1) baseline single-word generation, (2) PRM-Select best-of-N sampling, and (3) PRM-Sequential refinement guided by PRM critiques. We evaluate these techniques across 200 English prompts and their Urdu counterparts, designed to reflect socio-cultural contexts relevant to gender, ethnicity, religion, nationality, disability, profession, age, and socioeconomic categories. Using GPT-3.5 as a candidate generator and GPT-4o-mini as a PRM-based bias and utility scorer, we provide an extensive quantitative analysis of bias reduction, utility preservation, and cross-lingual disparities. Our findings show: (a) substantial gains over the baseline for both languages; (b) consistently lower fairness scores for Urdu across all methods, highlighting structural inequities in multilingual LLM training; and (c) distinct improvement trajectories between PRM-Select and PRM-Sequential. The study contributes an extensible methodology, interpretable metrics, and cross-lingual comparisons that can support future work on fairness evaluation in low-resource languages.