ChronusOmni: Improving Time Awareness of Omni Large Language Models
作者: Yijing Chen, Yihan Wu, Kaisi Guan, Yuchen Ren, Yuyue Wang, Ruihua Song, Liyun Ru
分类: cs.CL, cs.CV, cs.MM
发布日期: 2025-12-10
备注: Code available at https://github.com/YJCX330/Chronus/
💡 一句话要点
ChronusOmni:提升全模态大语言模型的时间感知能力,解决跨模态时序推理问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 全模态大语言模型 时间感知 时序定位 跨模态推理 强化学习 音视频理解 时间戳token
📋 核心要点
- 现有方法在音视频时序理解中,对音频模态利用不足,忽略了跨模态的隐式时序关系。
- ChronusOmni通过时间戳token交错和强化学习,增强模型对显式和隐式音视频时序关系的理解。
- 实验表明,ChronusOmni在时序定位任务上显著优于现有方法,提升超过30%。
📝 摘要(中文)
本文提出ChronusOmni,一个旨在增强全模态大语言模型时间感知能力的模型,尤其针对显式和隐式的音视频时序定位任务。该模型通过在每个时间单元将基于文本的时间戳token与视觉和音频表征交错,实现了跨模态的统一时序建模。为了强制正确的时序顺序并加强细粒度时序推理,本文采用了强化学习,并设计了专门的奖励函数。此外,本文构建了一个时间精确、模态完整且跨模态对齐的数据集ChronusAV,以支持音视频时序定位任务的训练和评估。实验结果表明,ChronusOmni在ChronusAV上取得了最先进的性能,提升超过30%,并在其他时序定位基准测试的大多数指标上取得了最佳结果。这突出了模型在跨模态方面的强大时间感知能力,同时保留了一般的视频和音频理解能力。
🔬 方法详解
问题定义:现有全模态大语言模型在处理长视频和回答复杂问题时,时间感知能力不足,尤其是在跨模态时序推理方面。现有方法主要关注视觉-语言场景,侧重于显式时序定位问题,例如识别视觉事件发生的时间。然而,它们对音频模态的利用不足,并且忽略了隐式时序定位,例如识别说话时视觉上呈现的内容。
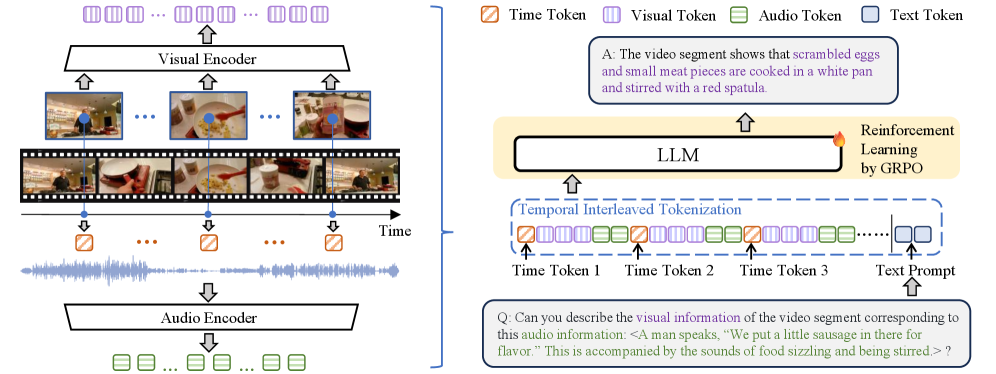
核心思路:ChronusOmni的核心思路是通过统一的时序建模来增强模型对显式和隐式音视频时序关系的理解。具体来说,模型将文本时间戳token与视觉和音频表征交错,从而在所有模态上实现统一的时序建模。此外,使用强化学习来强制正确的时序顺序并加强细粒度时序推理。
技术框架:ChronusOmni的整体框架包括以下几个主要模块:1) 视觉和音频特征提取模块,用于提取视频和音频的表征;2) 时间戳token嵌入模块,用于将时间戳信息编码为向量表示;3) 跨模态融合模块,将视觉、音频和时间戳token的表征进行融合;4) 时序推理模块,利用融合后的表征进行时序推理,例如预测事件发生的时间或识别特定时间点的事件。
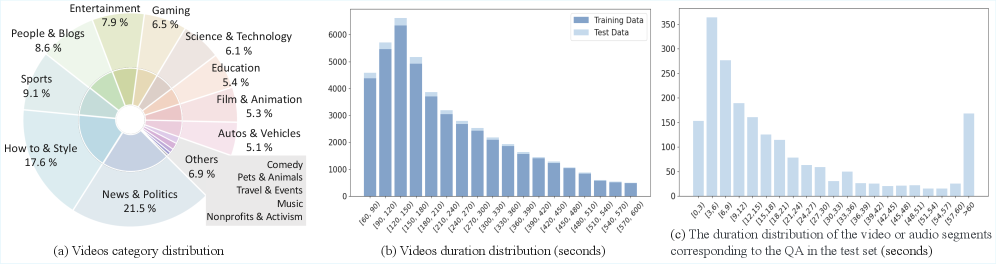
关键创新:ChronusOmni的关键创新在于以下几点:1) 统一的时序建模方法,通过时间戳token交错,实现了跨模态的时序信息融合;2) 基于强化学习的时序推理方法,通过设计专门的奖励函数,强制模型学习正确的时序顺序和细粒度的时序关系;3) ChronusAV数据集,该数据集提供了时间精确、模态完整且跨模态对齐的音视频数据,为时序定位任务的训练和评估提供了支持。
关键设计:在时间戳token嵌入方面,采用了可学习的嵌入向量。在强化学习方面,奖励函数的设计考虑了时序的正确性和推理的准确性。具体来说,如果模型预测的事件发生时间与真实时间接近,则给予正向奖励;如果模型预测的事件顺序错误,则给予负向奖励。此外,还使用了dropout和权重衰减等正则化技术来防止过拟合。
🖼️ 关键图片

📊 实验亮点
ChronusOmni在ChronusAV数据集上取得了state-of-the-art的性能,相比现有方法提升超过30%。同时,在其他时序定位基准测试的大多数指标上也取得了最佳结果。这些实验结果表明,ChronusOmni具有强大的跨模态时间感知能力,并且能够有效地进行显式和隐式的时序推理。
🎯 应用场景
ChronusOmni可应用于视频内容理解、智能监控、人机交互等领域。例如,在视频内容理解中,可以利用该模型理解视频中的事件发生顺序和时间关系,从而更好地理解视频内容。在智能监控中,可以利用该模型检测异常事件并确定其发生时间。在人机交互中,可以利用该模型理解用户的语音指令并根据时间信息执行相应的操作。该研究有望推动多模态人工智能的发展。
📄 摘要(原文)
Time awareness is a fundamental ability of omni large language models, especially for understanding long videos and answering complex questions. Previous approaches mainly target vision-language scenarios and focus on the explicit temporal grounding questions, such as identifying when a visual event occurs or determining what event happens at aspecific time. However, they often make insufficient use of the audio modality, and overlook implicit temporal grounding across modalities--for example, identifying what is visually present when a character speaks, or determining what is said when a visual event occurs--despite such cross-modal temporal relations being prevalent in real-world scenarios. In this paper, we propose ChronusOmni, an omni large language model designed to enhance temporal awareness for both explicit and implicit audiovisual temporal grounding. First, we interleave text-based timestamp tokens with visual and audio representations at each time unit, enabling unified temporal modeling across modalities. Second, to enforce correct temporal ordering and strengthen fine-grained temporal reasoning, we incorporate reinforcement learning with specially designed reward functions. Moreover, we construct ChronusAV, a temporally-accurate, modality-complete, and cross-modal-aligned dataset to support the training and evaluation on audiovisual temporal grounding task. Experimental results demonstrate that ChronusOmni achieves state-of-the-art performance on ChronusAV with more than 30% improvement and top results on most metrics upon other temporal grounding benchmarks. This highlights the strong temporal awareness of our model across modalities, while preserving general video and audio understanding capabilities.