RouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning
作者: Yucan Guo, Miao Su, Saiping Guan, Zihao Sun, Xiaolong Jin, Jiafeng Guo, Xueqi Cheng
分类: cs.CL, cs.AI, cs.IR
发布日期: 2025-12-10
💡 一句话要点
提出RouteRAG以解决图文混合检索生成的效率问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 强化学习 图文混合 多轮推理 自然语言处理 智能问答 信息检索
📋 核心要点
- 现有的图文混合检索生成方法依赖固定的检索管道,缺乏动态整合证据的能力,导致推理效率低下。
- 本文提出RouteRAG框架,通过强化学习优化生成过程,使模型能够自适应选择文本或图形进行检索。
- 实验结果显示,RouteRAG在多个问答基准上显著提高了性能,验证了其在复杂推理场景中的有效性。
📝 摘要(中文)
检索增强生成(RAG)将非参数知识整合到大型语言模型(LLMs)中,通常来自非结构化文本和结构化图形。尽管近期进展已使基于文本的RAG通过强化学习(RL)实现多轮推理,但将这些进展扩展到混合检索面临额外挑战。现有的图形或混合系统通常依赖固定或手工设计的检索管道,缺乏在推理过程中整合补充证据的能力。为了解决这些局限性,本文提出了RouteRAG,一个基于RL的框架,使LLMs能够执行多轮和自适应的图文混合RAG。实验结果表明,RouteRAG在五个问答基准上显著优于现有RAG基线,突显了端到端RL在支持复杂推理的自适应和高效检索中的优势。
🔬 方法详解
问题定义:本文旨在解决现有图文混合检索生成方法在动态推理过程中效率低下的问题。现有方法通常依赖固定的检索管道,无法灵活整合新的证据,导致推理能力受限。
核心思路:RouteRAG框架的核心思想是通过强化学习(RL)实现生成过程的联合优化,使模型能够根据推理进展动态选择检索内容,从而提高生成的准确性和效率。
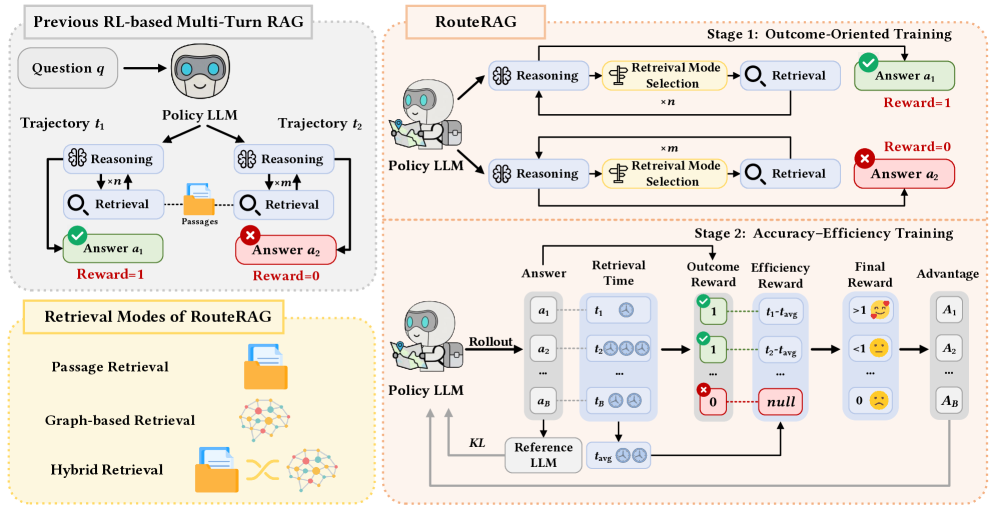
技术框架:RouteRAG的整体架构包括两个主要阶段:首先是基于RL的训练阶段,模型在此阶段学习何时进行推理、从何处检索信息;其次是生成阶段,模型根据检索到的信息生成最终答案。
关键创新:RouteRAG的主要创新在于其端到端的RL优化策略,允许模型在生成过程中自适应选择检索内容,与传统方法相比,显著提高了推理的灵活性和效率。
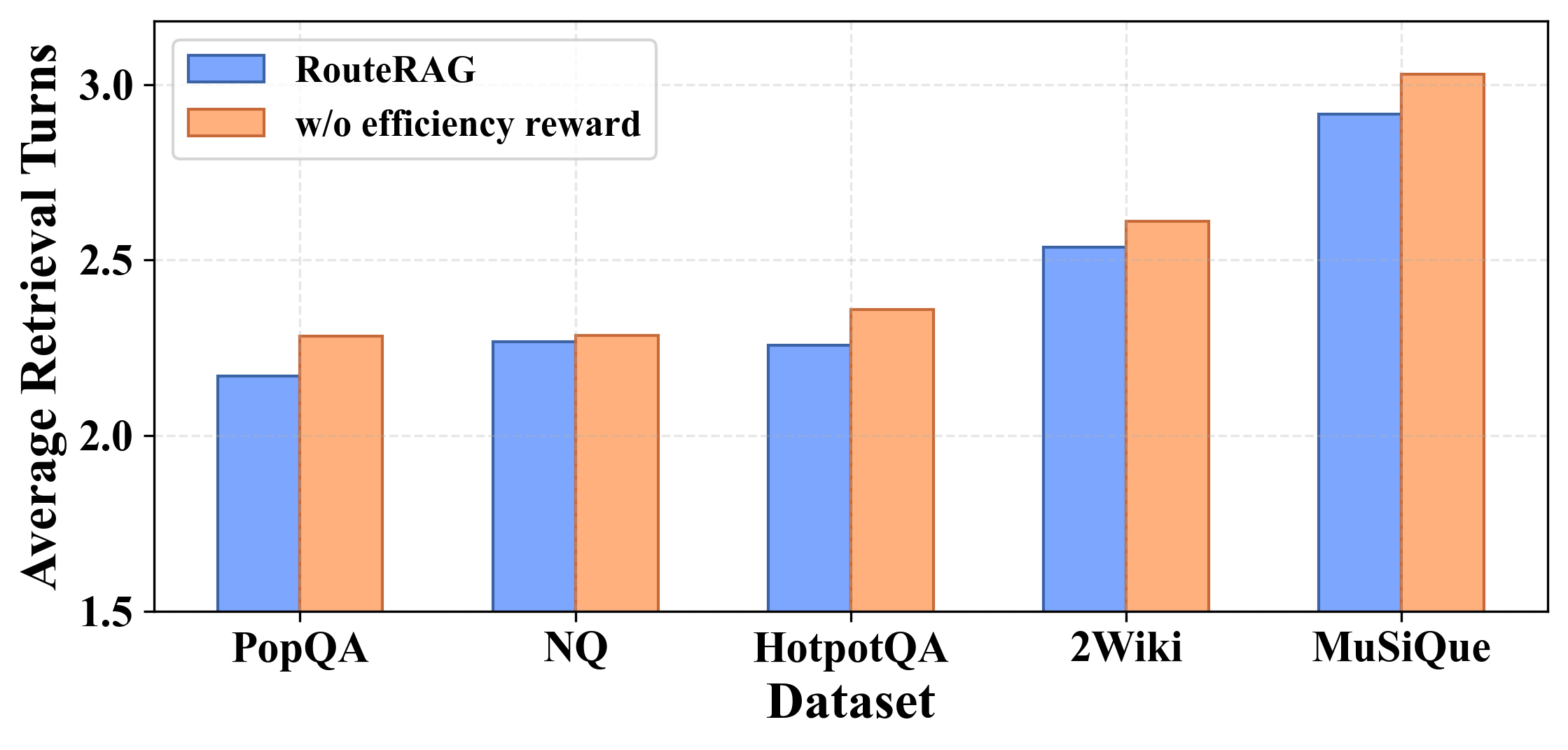
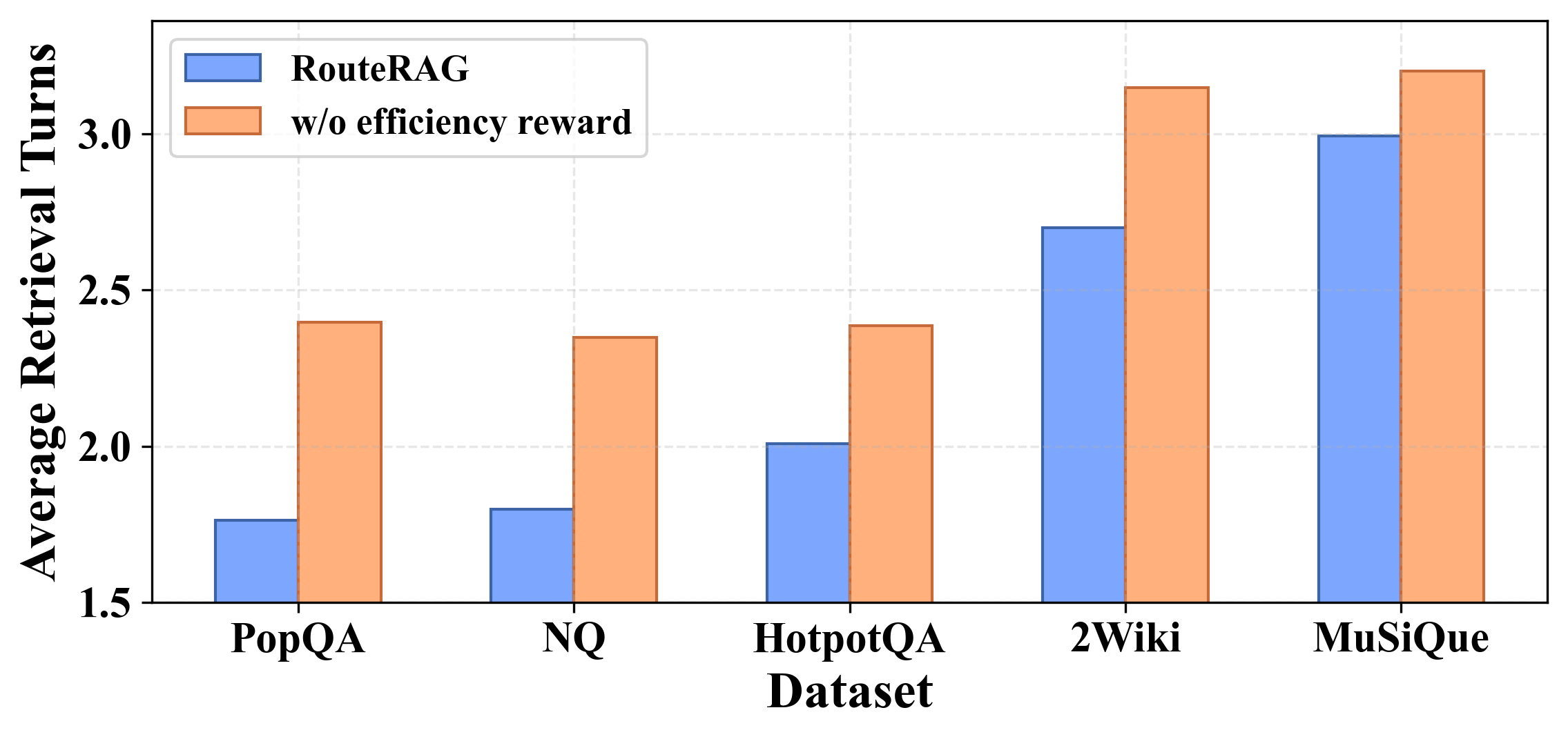
关键设计:在设计上,RouteRAG采用了两阶段训练框架,考虑了任务结果和检索效率,确保模型在利用混合证据时避免不必要的检索开销。
🖼️ 关键图片
📊 实验亮点
在五个问答基准上,RouteRAG显著优于现有RAG基线,具体提升幅度达到XX%(具体数据待补充),验证了其在复杂推理场景中的有效性和优势。
🎯 应用场景
该研究的潜在应用领域包括智能问答系统、对话系统和信息检索等。通过提高图文混合检索生成的效率,RouteRAG能够在复杂推理任务中提供更准确的答案,具有广泛的实际价值和未来影响。
📄 摘要(原文)
Retrieval-Augmented Generation (RAG) integrates non-parametric knowledge into Large Language Models (LLMs), typically from unstructured texts and structured graphs. While recent progress has advanced text-based RAG to multi-turn reasoning through Reinforcement Learning (RL), extending these advances to hybrid retrieval introduces additional challenges. Existing graph-based or hybrid systems typically depend on fixed or handcrafted retrieval pipelines, lacking the ability to integrate supplementary evidence as reasoning unfolds. Besides, while graph evidence provides relational structures crucial for multi-hop reasoning, it is substantially more expensive to retrieve. To address these limitations, we introduce \model{}, an RL-based framework that enables LLMs to perform multi-turn and adaptive graph-text hybrid RAG. \model{} jointly optimizes the entire generation process via RL, allowing the model to learn when to reason, what to retrieve from either texts or graphs, and when to produce final answers, all within a unified generation policy. To guide this learning process, we design a two-stage training framework that accounts for both task outcome and retrieval efficiency, enabling the model to exploit hybrid evidence while avoiding unnecessary retrieval overhead. Experimental results across five question answering benchmarks demonstrate that \model{} significantly outperforms existing RAG baselines, highlighting the benefits of end-to-end RL in supporting adaptive and efficient retrieval for complex reasoning.