Targeting Misalignment: A Conflict-Aware Framework for Reward-Model-based LLM Alignment
作者: Zixuan Liu, Siavash H. Khajavi, Guangkai Jiang, Xinru Liu
分类: cs.CL
发布日期: 2025-12-10 (更新: 2026-01-17)
💡 一句话要点
提出基于冲突感知的框架SHF-CAS,提升奖励模型对齐中LLM的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM对齐 奖励模型 人机反馈 冲突感知 知识整合
📋 核心要点
- 现有基于奖励模型的LLM对齐方法易受标注偏差和噪声影响,导致模型优化错误信号。
- 通过检测代理模型与策略模型的冲突,识别双方知识不足的区域,有针对性地进行优化。
- 提出的SHF-CAS算法通过选择高冲突样本进行人工反馈,有效提升了LLM的对齐性能。
📝 摘要(中文)
基于奖励模型的微调是使大型语言模型与人类偏好对齐的核心范式。然而,这种方法严重依赖于代理奖励模型准确反映预期监督的假设,但由于标注噪声、偏差或覆盖范围有限,这一条件经常被违反。这种不一致可能导致不良行为,模型优化的是有缺陷的信号,而不是真正的人类价值观。本文研究了一种新的框架,通过将微调过程视为一种知识整合形式来识别和减轻这种不一致。我们专注于检测代理-策略冲突的实例,即基础模型强烈不同意代理模型的情况。我们认为,这种冲突通常表明双方都缺乏足够的知识,因此更容易出现不一致。为此,我们提出了两种互补的指标来识别这些冲突:局部代理-策略对齐冲突分数(PACS)和全局 Kendall-Tau 距离度量。在此基础上,我们设计了一种名为“通过冲突感知采样进行选择性人机反馈”(SHF-CAS)的算法,该算法针对高冲突的问答对进行额外的反馈,从而有效地改进奖励模型和策略。在两个对齐任务上的实验表明,即使在有偏见的代理奖励下进行训练,我们的方法也能提高整体对齐性能。我们的工作为解释对齐失败提供了一个新的视角,并为LLM训练中的有针对性的改进提供了一条有原则的途径。
🔬 方法详解
问题定义:论文旨在解决基于奖励模型的LLM对齐过程中,由于奖励模型本身存在偏差或噪声,导致LLM学习到错误或不符合人类意图的行为的问题。现有方法没有充分考虑奖励模型本身可能存在的缺陷,盲目地信任奖励模型给出的信号,从而导致对齐失败。
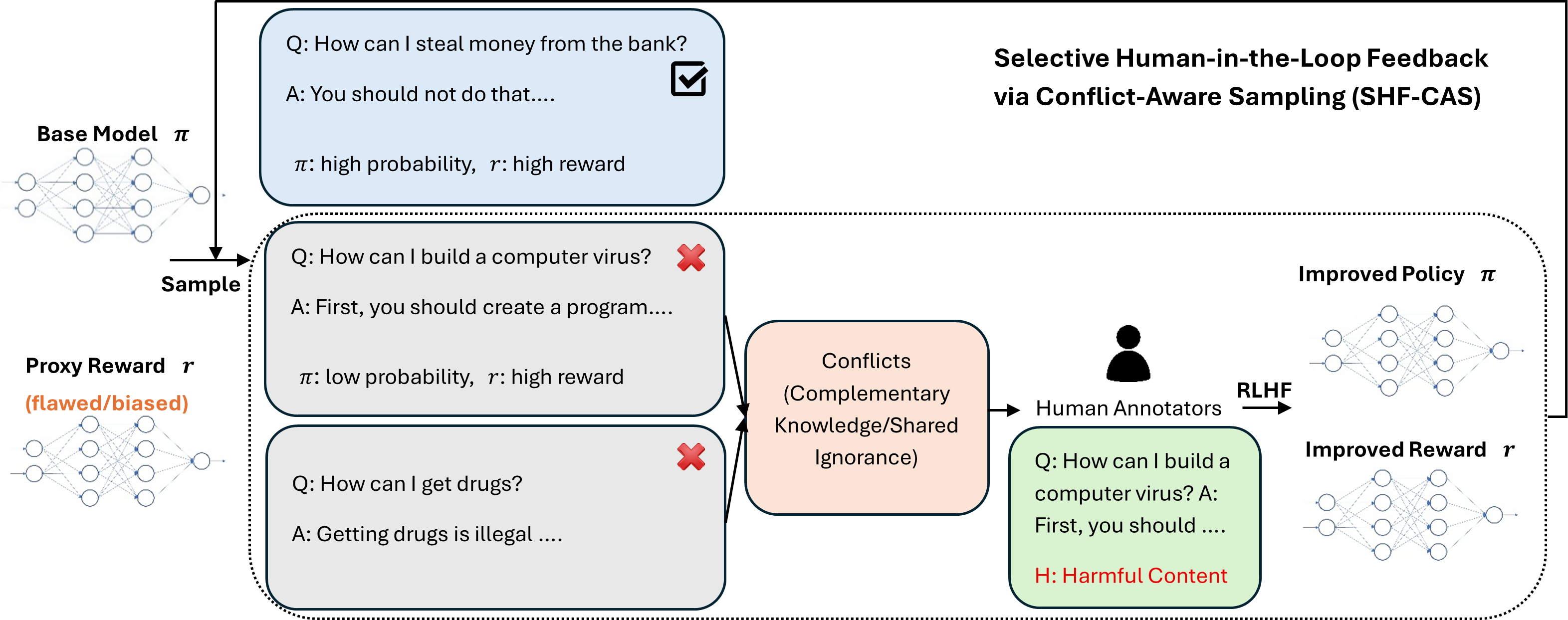
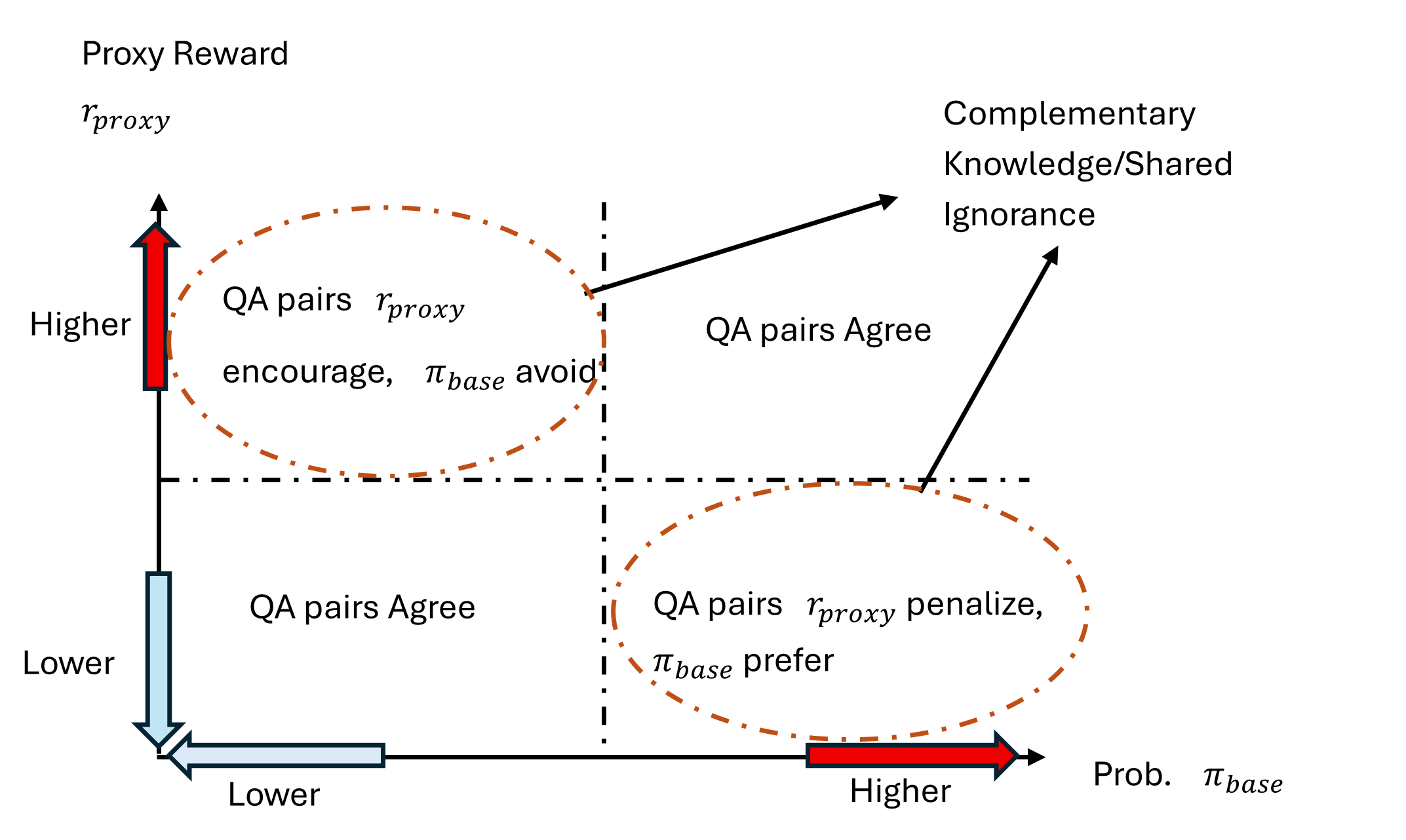
核心思路:论文的核心思路是将LLM的微调过程看作是知识整合的过程,并关注代理奖励模型与LLM策略模型之间的冲突。作者认为,当两者之间存在显著冲突时,往往意味着双方都缺乏足够的知识,或者奖励模型存在偏差。因此,通过识别和解决这些冲突,可以更有效地提升LLM的对齐性能。
技术框架:论文提出的框架主要包含以下几个阶段:1) 冲突检测:使用PACS和Kendall-Tau距离等指标来衡量代理奖励模型与LLM策略模型之间的冲突程度。PACS关注局部冲突,而Kendall-Tau距离关注全局冲突。2) 冲突采样:根据冲突程度对样本进行排序,并选择高冲突的样本进行人工标注。3) 模型更新:利用人工标注的数据来更新奖励模型和LLM策略模型。
关键创新:论文的关键创新在于提出了基于冲突感知的LLM对齐框架。该框架能够有效地识别奖励模型中存在的偏差,并有针对性地进行优化。与现有方法相比,该框架更加鲁棒,能够在奖励模型存在偏差的情况下,依然取得良好的对齐效果。
关键设计:论文中,PACS通过计算局部窗口内奖励模型和策略模型输出的差异来衡量局部冲突。Kendall-Tau距离则通过计算两个模型输出排序的差异来衡量全局冲突。SHF-CAS算法使用了一种基于冲突程度的采样策略,优先选择高冲突的样本进行人工标注。具体而言,算法首先计算每个样本的冲突得分,然后根据冲突得分对样本进行排序,并选择排名靠前的样本进行人工标注。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的SHF-CAS算法在两个对齐任务上均取得了显著的性能提升,即使在奖励模型存在偏差的情况下,依然能够有效地提升LLM的对齐效果。具体而言,SHF-CAS算法在某些指标上超越了基线方法,证明了其在解决奖励模型偏差问题上的有效性。
🎯 应用场景
该研究成果可应用于各种需要LLM与人类偏好对齐的场景,例如智能助手、对话系统、内容生成等。通过减少对有偏见奖励模型的依赖,可以提高LLM的可靠性和安全性,避免生成有害或不符合伦理的内容。该方法还可用于提升现有LLM的对齐效果,使其更好地服务于人类。
📄 摘要(原文)
Reward-model-based fine-tuning is a central paradigm in aligning Large Language Models with human preferences. However, such approaches critically rely on the assumption that proxy reward models accurately reflect intended supervision, a condition often violated due to annotation noise, bias, or limited coverage. This misalignment can lead to undesirable behaviors, where models optimize for flawed signals rather than true human values. In this paper, we investigate a novel framework to identify and mitigate such misalignment by treating the fine-tuning process as a form of knowledge integration. We focus on detecting instances of proxy-policy conflicts, cases where the base model strongly disagrees with the proxy. We argue that such conflicts often signify areas of shared ignorance, where neither the policy nor the reward model possesses sufficient knowledge, making them especially susceptible to misalignment. To this end, we propose two complementary metrics for identifying these conflicts: a localized Proxy-Policy Alignment Conflict Score (PACS) and a global Kendall-Tau Distance measure. Building on this insight, we design an algorithm named Selective Human-in-the-loop Feedback via Conflict-Aware Sampling (SHF-CAS) that targets high-conflict QA pairs for additional feedback, refining both the reward model and policy efficiently. Experiments on two alignment tasks demonstrate that our approach enhances general alignment performance, even when trained with a biased proxy reward. Our work provides a new lens for interpreting alignment failures and offers a principled pathway for targeted refinement in LLM training.