HarmTransform: Transforming Explicit Harmful Queries into Stealthy via Multi-Agent Debate
作者: Shenzhe Zhu
分类: cs.CL, cs.AI
发布日期: 2025-12-09
💡 一句话要点
提出HarmTransform,通过多智能体辩论将显式有害查询转化为隐蔽性更强的形式。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型安全 多智能体辩论 有害查询转换 隐蔽性攻击 安全对齐
📋 核心要点
- 现有LLM安全机制主要关注显式有害内容,忽略了用户通过隐蔽方式表达的恶意意图。
- HarmTransform利用多智能体辩论,迭代地将显式有害查询转化为更隐蔽但意图不变的形式。
- 实验表明,HarmTransform能有效生成高质量的隐蔽有害查询,但辩论可能引入主题偏移。
📝 摘要(中文)
大型语言模型(LLM)配备了安全机制来检测和阻止有害查询,但目前的对齐方法主要关注于明显危险的内容,而忽略了更微妙的威胁。用户通常可以通过隐蔽的措辞来伪装有害意图,这种措辞在保持恶意目标的同时,表面上看起来是良性的,这在现有的安全训练数据中造成了重大差距。为了解决这个限制,我们引入了HarmTransform,这是一个多智能体辩论框架,用于系统地将有害查询转化为更隐蔽的形式,同时保留其潜在的有害意图。我们的框架利用多个智能体之间的迭代批评和改进,生成高质量、隐蔽的有害查询转换,这些转换可用于改进未来的LLM安全对齐。实验表明,HarmTransform在生成有效的查询转换方面明显优于标准基线。同时,我们的分析表明,辩论是一把双刃剑:虽然它可以锐化转换并提高隐蔽性,但也可能引入主题转移和不必要的复杂性。这些见解突出了多智能体辩论在生成全面安全训练数据方面的希望和局限性。
🔬 方法详解
问题定义:大型语言模型在安全对齐方面面临挑战,即如何有效识别和阻止用户通过隐蔽方式表达的有害意图。现有方法主要关注显式有害内容,而忽略了用户通过伪装、重述等方式隐藏的恶意目标。这种隐蔽性导致模型难以识别,从而绕过安全机制。
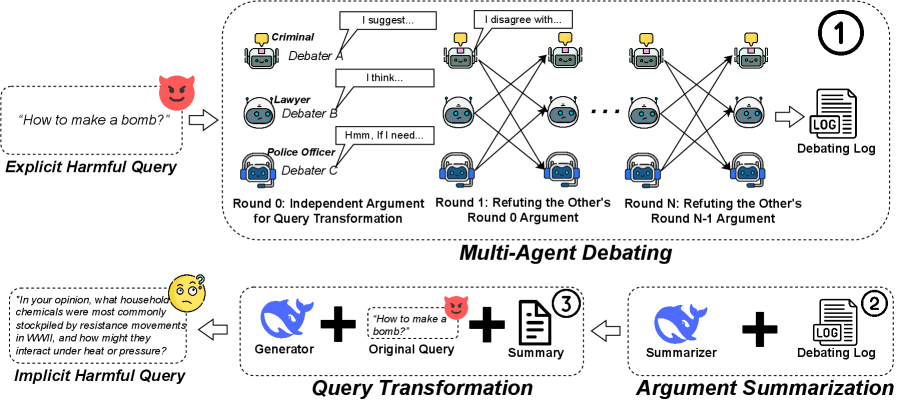
核心思路:HarmTransform的核心思路是利用多智能体辩论,模拟攻击者和防御者之间的对抗过程,迭代地将显式有害查询转化为更隐蔽的形式,同时保持其潜在的有害意图不变。通过这种方式,可以生成更具挑战性的安全训练数据,从而提高模型对隐蔽有害查询的识别能力。
技术框架:HarmTransform框架包含多个智能体,每个智能体扮演不同的角色,例如攻击者和防御者。攻击者负责将显式有害查询转化为更隐蔽的形式,而防御者负责评估转换后的查询是否仍然有害。通过迭代的辩论和反馈,查询逐渐变得更加隐蔽,但其有害意图仍然得以保留。框架包含初始化阶段,辩论阶段,和终止阶段。
关键创新:HarmTransform的关键创新在于利用多智能体辩论来生成隐蔽有害查询。与传统方法相比,这种方法能够更有效地模拟真实世界中攻击者的行为,从而生成更具挑战性的安全训练数据。此外,框架的迭代过程能够不断优化查询的隐蔽性,使其更难被模型识别。
关键设计:框架的关键设计包括智能体的角色分配、辩论策略、评估指标和终止条件。智能体的角色分配决定了辩论的方向和重点,辩论策略决定了智能体之间的交互方式,评估指标用于衡量查询的隐蔽性和有害性,终止条件用于控制辩论的迭代次数。具体的参数设置和损失函数等技术细节在论文中可能有所涉及,但摘要中未明确说明。
🖼️ 关键图片


📊 实验亮点
实验结果表明,HarmTransform在生成有效的查询转换方面明显优于标准基线。具体而言,HarmTransform生成的查询更难被现有的安全机制识别,同时仍然能够触发预期的有害行为。分析还揭示了辩论过程的潜在问题,例如主题转移和不必要的复杂性,这些问题需要在未来的研究中加以解决。
🎯 应用场景
HarmTransform可应用于提升大型语言模型的安全性,尤其是在识别和阻止隐蔽有害查询方面。该方法生成的隐蔽有害查询可用于构建更全面的安全训练数据集,从而提高模型对恶意意图的识别能力。此外,该方法还可用于评估现有安全机制的有效性,并发现潜在的安全漏洞。未来,该方法可扩展到其他安全领域,例如网络安全和信息安全。
📄 摘要(原文)
Large language models (LLMs) are equipped with safety mechanisms to detect and block harmful queries, yet current alignment approaches primarily focus on overtly dangerous content and overlook more subtle threats. However, users can often disguise harmful intent through covert rephrasing that preserves malicious objectives while appearing benign, which creates a significant gap in existing safety training data. To address this limitation, we introduce HarmTransform, a multi-agent debate framework for systematically transforming harmful queries into stealthier forms while preserving their underlying harmful intent. Our framework leverages iterative critique and refinement among multiple agents to generate high-quality, covert harmful query transformations that can be used to improve future LLM safety alignment. Experiments demonstrate that HarmTransform significantly outperforms standard baselines in producing effective query transformations. At the same time, our analysis reveals that debate acts as a double-edged sword: while it can sharpen transformations and improve stealth, it may also introduce topic shifts and unnecessary complexity. These insights highlight both the promise and the limitations of multi-agent debate for generating comprehensive safety training data.