MindShift: Analyzing Language Models' Reactions to Psychological Prompts
作者: Anton Vasiliuk, Irina Abdullaeva, Polina Druzhinina, Anton Razzhigaev, Andrey Kuznetsov
分类: cs.CL, cs.AI
发布日期: 2025-12-09 (更新: 2025-12-18)
💡 一句话要点
MindShift:分析语言模型对心理学提示的反应,评估其人格适应性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 心理测量 人格特质 人机交互 MindShift基准
📋 核心要点
- 现有方法缺乏对LLM人格特质的系统评估,难以衡量其心理适应性。
- 论文提出MindShift基准,通过人格化提示评估LLM在不同角色下的行为。
- 实验表明,LLM的角色感知能力随训练数据和对齐技术进步而提升,但模型间存在差异。
📝 摘要(中文)
大型语言模型(LLMs)具有吸收和反映用户指定的人格特质和态度的潜力。本研究利用可靠的心理测量方法,调查了这种潜力。我们采用了心理学文献中最受研究的明尼苏达多相人格调查表(MMPI),并检查了LLMs的行为以识别其人格特质。为了评估LLMs对提示的敏感性和心理偏差,我们创建了面向人格的提示,精心设计了一组在特质强度上各不相同的角色。这使我们能够衡量LLMs遵循这些角色的程度。我们的研究引入了MindShift,这是一个用于评估LLMs心理适应性的基准。结果表明,LLMs的角色感知能力持续提高,这归因于训练数据集和对齐技术的进步。此外,我们观察到不同模型类型和系列对心理测量评估的反应存在显著差异,表明它们模拟类人性格特质的能力存在差异。MindShift提示和用于LLM评估的代码将公开提供。
🔬 方法详解
问题定义:论文旨在解决如何系统性地评估大型语言模型(LLMs)在模拟不同人格特质方面的能力的问题。现有方法缺乏标准化的心理测量工具,难以量化LLMs对人格化提示的反应,以及识别其潜在的心理偏差。这阻碍了我们理解LLMs在人机交互和心理健康等领域的应用潜力。
核心思路:论文的核心思路是借鉴心理学领域成熟的明尼苏达多相人格调查表(MMPI),并将其改编为适用于LLMs的提示。通过精心设计具有不同人格特质的角色,并观察LLMs在这些角色下的行为,从而评估其心理适应性。这种方法能够量化LLMs对人格化提示的敏感性,并识别其潜在的心理偏差。
技术框架:MindShift基准测试框架主要包含以下几个阶段:1) 人格化提示生成:基于MMPI量表,创建一系列具有不同人格特质的角色描述。2) LLM响应生成:将人格化提示输入到不同的LLMs中,生成相应的文本响应。3) 心理测量评估:使用心理测量指标(如MMPI量表)评估LLMs生成的文本响应,从而量化其人格特质。4) 结果分析:比较不同LLMs在心理测量评估上的表现,分析其人格适应性的差异。
关键创新:论文最重要的技术创新点在于提出了MindShift基准,这是一个专门用于评估LLMs心理适应性的标准化测试框架。与现有方法相比,MindShift借鉴了心理学领域成熟的MMPI量表,能够更准确、更可靠地评估LLMs的人格特质。此外,MindShift还提供了一套精心设计的人格化提示,能够有效激发LLMs在不同角色下的行为。
关键设计:论文的关键设计包括:1) 基于MMPI量表的人格化提示设计,确保提示的心理学有效性。2) 采用多种LLMs进行评估,以比较不同模型的人格适应性。3) 使用标准化的心理测量指标,量化LLMs的人格特质。4) 公开MindShift提示和代码,方便研究人员进行复现和扩展。
🖼️ 关键图片


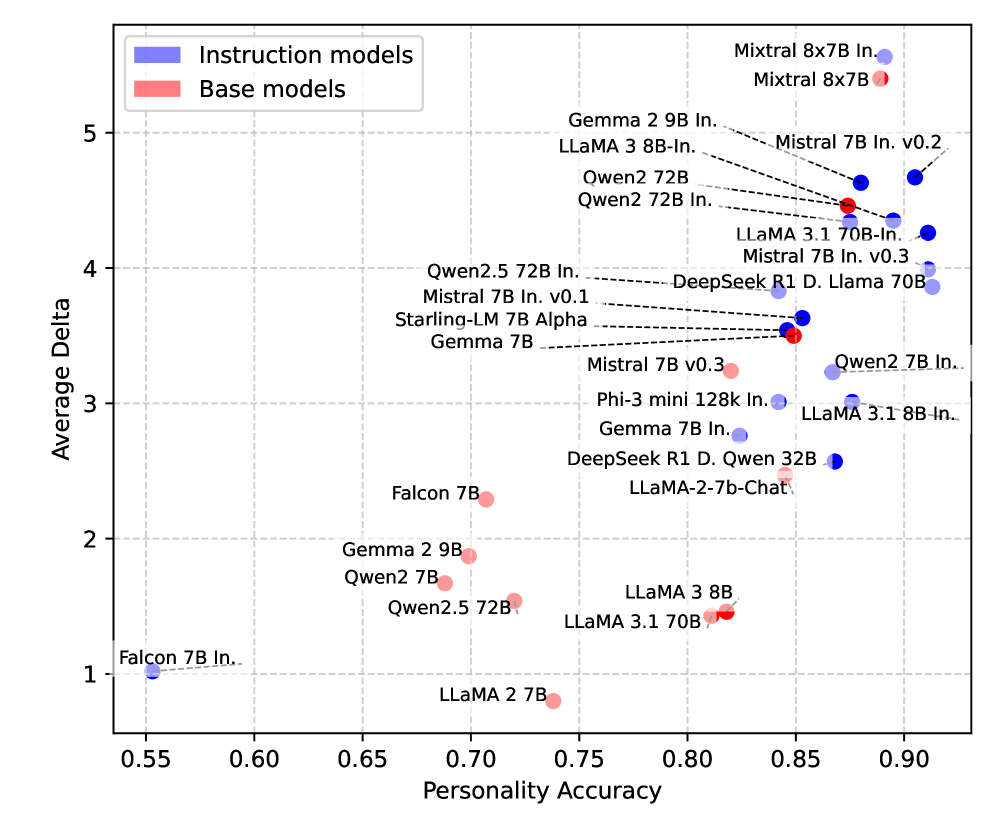
📊 实验亮点
实验结果表明,LLMs的角色感知能力随着训练数据集和对齐技术的进步而持续提高。不同模型类型和系列对心理测量评估的反应存在显著差异,表明它们模拟类人性格特质的能力存在差异。MindShift基准的引入为评估LLMs的心理适应性提供了一个有效的工具。
🎯 应用场景
该研究成果可应用于人机交互、虚拟助手、心理健康咨询等领域。通过了解LLM的人格特质,可以设计更具同理心和个性化的AI系统,提升用户体验。此外,该研究还有助于识别LLM的潜在心理偏差,从而避免其在敏感场景中产生不良影响。未来,MindShift基准可以促进LLM在心理学领域的应用,例如辅助心理诊断和治疗。
📄 摘要(原文)
Large language models (LLMs) hold the potential to absorb and reflect personality traits and attitudes specified by users. In our study, we investigated this potential using robust psychometric measures. We adapted the most studied test in psychological literature, namely Minnesota Multiphasic Personality Inventory (MMPI) and examined LLMs' behavior to identify traits. To asses the sensitivity of LLMs' prompts and psychological biases we created personality-oriented prompts, crafting a detailed set of personas that vary in trait intensity. This enables us to measure how well LLMs follow these roles. Our study introduces MindShift, a benchmark for evaluating LLMs' psychological adaptability. The results highlight a consistent improvement in LLMs' role perception, attributed to advancements in training datasets and alignment techniques. Additionally, we observe significant differences in responses to psychometric assessments across different model types and families, suggesting variability in their ability to emulate human-like personality traits. MindShift prompts and code for LLM evaluation will be publicly available.