Ask, Answer, and Detect: Role-Playing LLMs for Personality Detection with Question-Conditioned Mixture-of-Experts
作者: Yifan Lyu, Liang Zhang
分类: cs.CL
发布日期: 2025-12-09
💡 一句话要点
提出ROME框架,利用角色扮演LLM和混合专家模型进行人格检测。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人格检测 大型语言模型 角色扮演 混合专家模型 多任务学习 心理测量问卷 中间监督
📋 核心要点
- 现有的人格检测方法受限于标签稀缺和用户语言与抽象心理结构之间语义映射不明确。
- ROME框架利用LLM的角色扮演能力模拟用户回答问卷,注入心理学知识,提供中间监督。
- 实验结果表明,ROME在人格检测任务上显著优于现有方法,在Kaggle数据集上提升15.41%。
📝 摘要(中文)
本文提出了一种名为ROME的新框架,通过显式地将心理学知识注入到人格检测中来解决现有方法的局限性。ROME框架利用大型语言模型(LLM)的角色扮演能力,模拟用户对标准化心理测量问卷的回答,从而将自由形式的用户帖子转换为可解释的、基于问卷的证据,将语言线索与人格标签联系起来。这种方法提供了丰富的中间监督,缓解了标签稀缺问题,并提供了一个语义推理链,指导和简化了文本到人格的映射学习。一个问题条件混合专家模块共同路由帖子和问题表示,学习在显式监督下回答问卷项目。预测的答案被总结成一个可解释的答案向量,并与用户表示融合,用于多任务学习框架中的最终预测,其中问题回答作为人格检测的强大辅助任务。在两个真实世界数据集上的大量实验表明,ROME始终优于最先进的基线,在Kaggle数据集上实现了15.41%的改进。
🔬 方法详解
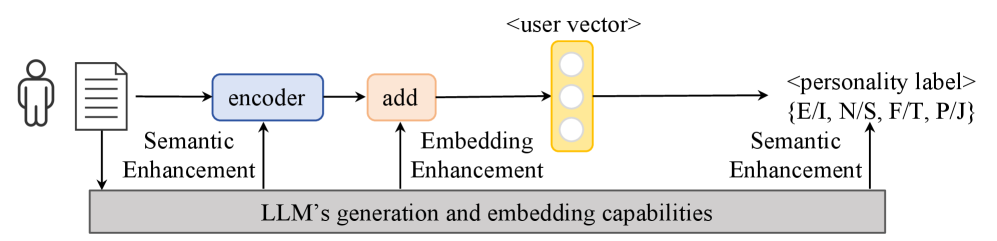
问题定义:现有的人格检测方法主要采用“帖子 -> 用户向量 -> 标签”的建模范式,依赖于将社交媒体帖子编码为用户表示,然后预测人格标签。这种方法存在两个主要痛点:一是标签数据稀缺,导致监督信号不足;二是用户语言和抽象心理学概念之间的语义映射关系不明确,难以建立有效的关联。
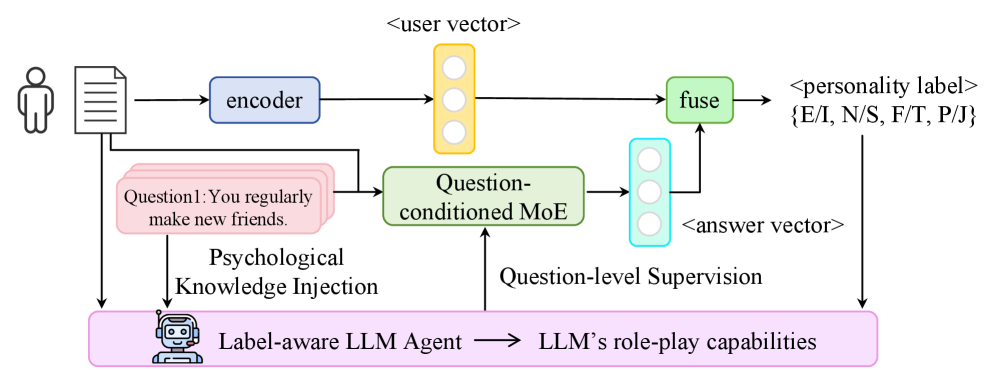
核心思路:ROME框架的核心思路是借鉴标准化自评测验,利用大型语言模型(LLM)的角色扮演能力,模拟用户对心理测量问卷的回答。通过这种方式,将用户发布的自由文本帖子转化为基于问卷的可解释证据,从而建立语言线索与人格标签之间的联系。这种方法旨在提供更丰富的中间监督信号,缓解标签稀缺问题,并提供一个语义推理链,指导和简化文本到人格的映射学习。
技术框架:ROME框架的整体架构包含以下几个主要模块:1) LLM角色扮演模块:利用LLM模拟用户回答心理测量问卷;2) 问题条件混合专家(Mixture-of-Experts)模块:联合路由帖子和问题表示,学习在显式监督下回答问卷项目;3) 多任务学习框架:将问题回答作为辅助任务,与人格检测任务共同训练,提升人格检测性能。
关键创新:ROME框架最重要的技术创新点在于引入了心理学知识,并将其融入到人格检测过程中。通过LLM的角色扮演能力,将自由文本帖子转化为基于问卷的结构化数据,从而提供了更丰富的中间监督信号,并建立了语言线索与人格标签之间的明确联系。这与以往直接将帖子编码为用户向量的方法有本质区别,后者缺乏对心理学知识的显式建模。
关键设计:ROME框架的关键设计包括:1) 使用预训练的LLM作为角色扮演模块的基础模型;2) 设计问题条件混合专家模块,用于联合处理帖子和问题表示,并学习回答问卷项目;3) 采用多任务学习框架,将问题回答任务作为人格检测的辅助任务,并设计合适的损失函数进行联合优化。具体参数设置和网络结构细节未在摘要中详细说明。
🖼️ 关键图片

📊 实验亮点
ROME框架在两个真实世界数据集上进行了广泛的实验,结果表明其性能始终优于最先进的基线方法。在Kaggle数据集上,ROME框架实现了15.41%的显著提升,证明了其在人格检测任务上的有效性。
🎯 应用场景
该研究成果可应用于个性化推荐系统、心理健康评估、招聘筛选等领域。通过更准确地理解用户的人格特征,可以提供更符合用户需求的个性化服务,并为心理健康评估提供更客观的依据。未来,该技术有望在人机交互、智能客服等领域发挥重要作用。
📄 摘要(原文)
Understanding human personality is crucial for web applications such as personalized recommendation and mental health assessment. Existing studies on personality detection predominantly adopt a "posts -> user vector -> labels" modeling paradigm, which encodes social media posts into user representations for predicting personality labels (e.g., MBTI labels). While recent advances in large language models (LLMs) have improved text encoding capacities, these approaches remain constrained by limited supervision signals due to label scarcity, and under-specified semantic mappings between user language and abstract psychological constructs. We address these challenges by proposing ROME, a novel framework that explicitly injects psychological knowledge into personality detection. Inspired by standardized self-assessment tests, ROME leverages LLMs' role-play capability to simulate user responses to validated psychometric questionnaires. These generated question-level answers transform free-form user posts into interpretable, questionnaire-grounded evidence linking linguistic cues to personality labels, thereby providing rich intermediate supervision to mitigate label scarcity while offering a semantic reasoning chain that guides and simplifies the text-to-personality mapping learning. A question-conditioned Mixture-of-Experts module then jointly routes over post and question representations, learning to answer questionnaire items under explicit supervision. The predicted answers are summarized into an interpretable answer vector and fused with the user representation for final prediction within a multi-task learning framework, where question answering serves as a powerful auxiliary task for personality detection. Extensive experiments on two real-world datasets demonstrate that ROME consistently outperforms state-of-the-art baselines, achieving improvements (15.41% on Kaggle dataset).