A Systematic Evaluation of Preference Aggregation in Federated RLHF for Pluralistic Alignment of LLMs
作者: Mahmoud Srewa, Tianyu Zhao, Salma Elmalaki
分类: cs.CL, cs.AI
发布日期: 2025-12-09 (更新: 2025-12-15)
备注: This paper is accepted at the NeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle
💡 一句话要点
提出联邦RLHF中自适应偏好聚合方法,提升LLM对多元化人类偏好对齐的公平性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 强化学习人类反馈 大型语言模型 偏好聚合 公平性
📋 核心要点
- 现有联邦学习中的LLM对齐方法难以充分代表多样化的人类偏好,导致模型在不同群体间的表现不均衡。
- 提出一种自适应偏好聚合方案,根据各组历史对齐表现动态调整偏好权重,以提升整体公平性。
- 实验结果表明,该自适应方法在保持对齐质量的同时,显著提升了LLM在问答任务中的公平性。
📝 摘要(中文)
本文旨在解决联邦学习(FL)环境中大型语言模型(LLM)与多样化人类偏好对齐的挑战,现有方法通常无法充分代表不同的观点。我们引入了一个全面的评估框架,系统地评估了在使用不同的人类偏好聚合策略时,对齐质量和公平性之间的权衡。在我们的联邦设置中,每个组本地评估rollout并产生奖励信号,服务器聚合这些组级别的奖励,而无需访问任何原始数据。具体来说,我们评估了标准的奖励聚合技术(最小值、最大值和平均值),并引入了一种新颖的自适应方案,该方案根据组的历史对齐性能动态调整偏好权重。我们在基于PPO的RLHF pipeline上,针对问答(Q/A)任务的实验表明,我们的自适应方法在保持有竞争力的对齐分数的同时,始终如一地实现了卓越的公平性。这项工作为评估跨不同人群的LLM行为提供了一种稳健的方法,并为开发真正多元化和公平对齐的模型提供了一种实用的解决方案。
🔬 方法详解
问题定义:论文旨在解决联邦强化学习人类反馈(RLHF)中,如何更好地聚合来自不同用户群体(clients)的偏好,从而训练出对所有群体都公平且高质量的LLM。现有方法,如简单地取平均、最大或最小值,无法有效处理各群体间偏好分布的差异,导致模型在某些群体上表现不佳,损害了公平性。
核心思路:核心思路是根据每个用户群体历史的对齐表现,动态地调整其偏好权重。表现好的群体,其偏好权重会相应提高,反之则降低。这样可以使模型更加关注那些之前被忽略或代表性不足的群体,从而提高整体的公平性。这种自适应调整的目的是让模型能够更好地学习和适应不同群体的偏好,而不是简单地将所有偏好视为同等重要。
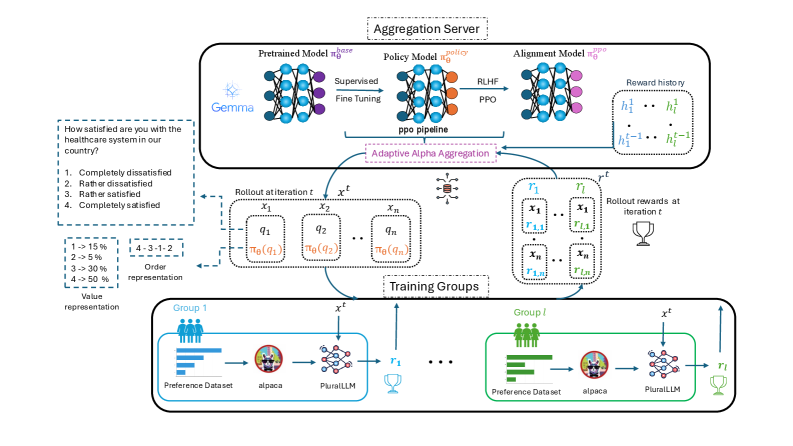
技术框架:整体框架基于联邦RLHF,包含以下几个主要阶段:1) 各个客户端(用户群体)在本地使用LLM生成文本;2) 客户端根据自身偏好对生成的文本进行评估,并产生奖励信号;3) 服务器接收来自各个客户端的奖励信号;4) 服务器使用提出的自适应聚合方法,将各个客户端的奖励信号聚合成一个全局奖励信号;5) 服务器使用全局奖励信号训练LLM。
关键创新:最关键的创新点在于提出了自适应偏好聚合方法。与传统的静态聚合方法(如平均、最大、最小)不同,该方法能够根据各个客户端的历史表现动态调整其偏好权重。这种动态调整机制使得模型能够更好地适应不同客户端的偏好,从而提高整体的公平性和对齐质量。
关键设计:自适应权重调整的具体实现细节未知,论文中可能涉及以下关键设计:1) 如何定义和衡量“对齐表现”?例如,可以使用奖励值的平均值或方差等指标。2) 如何设计权重调整的策略?例如,可以使用一个学习率来控制权重调整的幅度。3) 如何防止权重过度集中在少数几个客户端上?例如,可以设置一个权重的上下限。
🖼️ 关键图片
📊 实验亮点
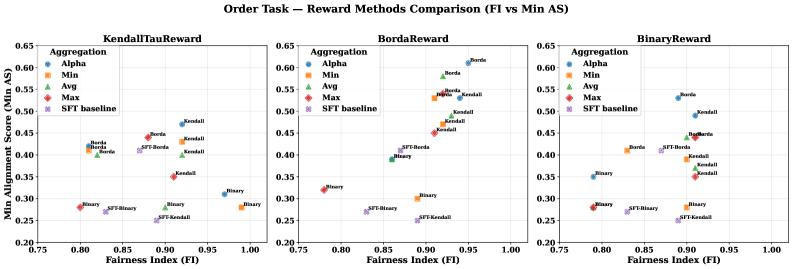
实验结果表明,提出的自适应偏好聚合方法在问答任务中,能够在保持与传统方法相当的对齐质量的前提下,显著提升LLM的公平性。具体的性能数据和提升幅度在论文中进行了详细的量化分析,证明了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要考虑用户偏好多样性的LLM应用场景,例如个性化推荐系统、多语言翻译、以及面向不同文化背景的对话机器人。通过公平地整合不同群体的偏好,可以避免模型产生偏见,提升用户满意度,并促进技术的普惠性发展。
📄 摘要(原文)
This paper addresses the challenge of aligning large language models (LLMs) with diverse human preferences within federated learning (FL) environments, where standard methods often fail to adequately represent diverse viewpoints. We introduce a comprehensive evaluation framework that systematically assesses the trade-off between alignment quality and fairness when using different aggregation strategies for human preferences. In our federated setting, each group locally evaluates rollouts and produces reward signals, and the server aggregates these group-level rewards without accessing any raw data. Specifically, we evaluate standard reward aggregation techniques (min, max, and average) and introduce a novel adaptive scheme that dynamically adjusts preference weights based on a group's historical alignment performance. Our experiments on question-answering (Q/A) tasks using a PPO-based RLHF pipeline demonstrate that our adaptive approach consistently achieves superior fairness while maintaining competitive alignment scores. This work offers a robust methodology for evaluating LLM behavior across diverse populations and provides a practical solution for developing truly pluralistic and fairly aligned models.