Segment, Embed, and Align: A Universal Recipe for Aligning Subtitles to Signing
作者: Zifan Jiang, Youngjoon Jang, Liliane Momeni, Gül Varol, Sarah Ebling, Andrew Zisserman
分类: cs.CL
发布日期: 2025-12-08
💡 一句话要点
提出SEA框架,用于通用且高效的手语视频字幕对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手语识别 字幕对齐 视频分割 跨模态嵌入 动态规划
📋 核心要点
- 现有手语字幕对齐方法依赖特定数据集和语言,泛化能力差,限制了其应用范围。
- SEA框架通过分割、嵌入和对齐三个步骤,利用预训练模型实现跨语言和领域的通用对齐。
- 实验表明,SEA在多个手语数据集上取得了最先进的对齐性能,为手语处理提供了高质量的并行数据。
📝 摘要(中文)
本文旨在开发一种通用的方法,用于将字幕(即带有时间戳的口语文本)与连续的手语视频对齐。以往的方法通常依赖于特定语言或数据集的端到端训练,这限制了它们的通用性。相比之下,我们的方法“分割、嵌入和对齐”(SEA)提供了一个可在多种语言和领域中使用的统一框架。SEA利用两个预训练模型:第一个模型将视频帧序列分割成单独的手语,第二个模型将每个手语的视频片段嵌入到与文本共享的潜在空间中。随后,使用轻量级的动态规划程序进行对齐,即使对于长达一小时的剧集,也能在几分钟内在CPU上高效运行。SEA具有灵活性,可以适应各种场景,利用从小型词典到大型连续语料库的资源。在四个手语数据集上的实验表明,SEA具有最先进的对齐性能,突出了SEA在生成高质量并行数据以推进手语处理方面的潜力。SEA的代码和模型已公开发布。
🔬 方法详解
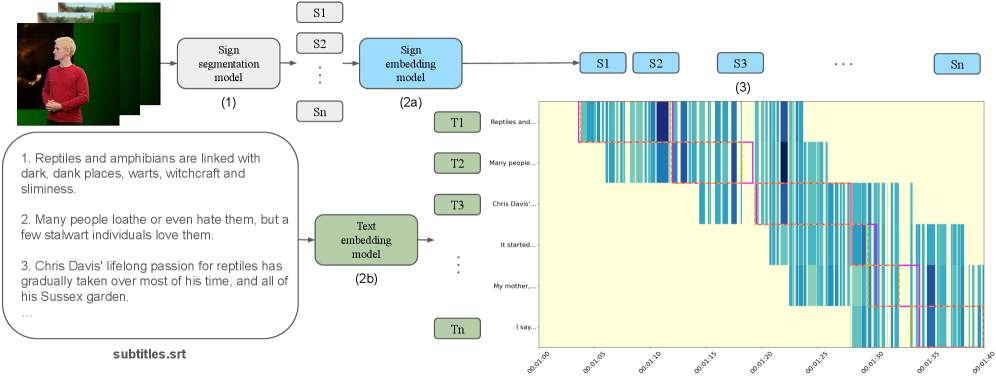
问题定义:该论文旨在解决手语视频和字幕对齐的问题。现有方法通常是端到端训练的,依赖于特定语言和数据集,因此泛化能力较差,难以应用于新的语言或领域。这些方法需要大量标注数据,成本高昂。
核心思路:论文的核心思路是将对齐问题分解为三个独立的步骤:分割、嵌入和对齐。通过利用预训练模型,分别处理视频分割和特征嵌入,从而避免了端到端训练的局限性,提高了模型的泛化能力。这种模块化的设计使得模型可以灵活地适应不同的场景和数据资源。
技术框架:SEA框架包含三个主要模块:1) 分割模块:使用预训练模型将手语视频分割成单独的符号。2) 嵌入模块:使用另一个预训练模型将分割后的视频片段和对应的文本嵌入到共享的潜在空间中。3) 对齐模块:使用动态规划算法,在共享的潜在空间中找到视频片段和文本的最佳对齐方式。整个流程无需端到端训练,可以利用现有的预训练模型和资源。
关键创新:SEA框架的关键创新在于其通用性和灵活性。它不依赖于特定语言或数据集,可以利用现有的预训练模型和资源,从而降低了训练成本和数据需求。通过分割、嵌入和对齐三个步骤,将复杂的对齐问题分解为更易于处理的子问题,提高了模型的效率和准确性。
关键设计:分割模块和嵌入模块使用了预训练模型,具体模型选择未明确说明,但强调了利用预训练模型的优势。对齐模块使用了动态规划算法,目标是最小化视频片段和文本嵌入之间的距离。动态规划算法的效率至关重要,论文强调了其在CPU上的高效运行能力。具体的损失函数和网络结构取决于所使用的预训练模型。
🖼️ 关键图片


📊 实验亮点
SEA框架在四个手语数据集上取得了最先进的对齐性能,证明了其有效性和通用性。具体性能数据未在摘要中给出,但强调了其优于现有方法的表现。该框架能够在CPU上高效运行,即使对于长达一小时的视频,也能在几分钟内完成对齐。
🎯 应用场景
该研究成果可广泛应用于手语翻译、手语教育、无障碍交流等领域。通过自动将字幕与手语视频对齐,可以生成高质量的并行数据,用于训练手语识别、手语翻译等模型。此外,该技术还可以帮助听力障碍人士更好地理解视频内容,促进社会包容。
📄 摘要(原文)
The goal of this work is to develop a universal approach for aligning subtitles (i.e., spoken language text with corresponding timestamps) to continuous sign language videos. Prior approaches typically rely on end-to-end training tied to a specific language or dataset, which limits their generality. In contrast, our method Segment, Embed, and Align (SEA) provides a single framework that works across multiple languages and domains. SEA leverages two pretrained models: the first to segment a video frame sequence into individual signs and the second to embed the video clip of each sign into a shared latent space with text. Alignment is subsequently performed with a lightweight dynamic programming procedure that runs efficiently on CPUs within a minute, even for hour-long episodes. SEA is flexible and can adapt to a wide range of scenarios, utilizing resources from small lexicons to large continuous corpora. Experiments on four sign language datasets demonstrate state-of-the-art alignment performance, highlighting the potential of SEA to generate high-quality parallel data for advancing sign language processing. SEA's code and models are openly available.