Short-Context Dominance: How Much Local Context Natural Language Actually Needs?
作者: Vala Vakilian, Zimeng Wang, Ankit Singh Rawat, Christos Thrampoulidis
分类: cs.CL, cs.AI
发布日期: 2025-12-08
备注: 38 pages, 7 figures, includes appendix and references
💡 一句话要点
研究表明,大型语言模型预测任务中,短语境通常已足够,并提出DaMCL指标检测长语境依赖,优化模型输出。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 最小语境长度 短语境主导 分布感知 解码算法 大型语言模型 上下文建模
📋 核心要点
- 现有大型语言模型在处理长序列时,计算成本高昂,且可能存在信息冗余,短语境主导现象值得关注。
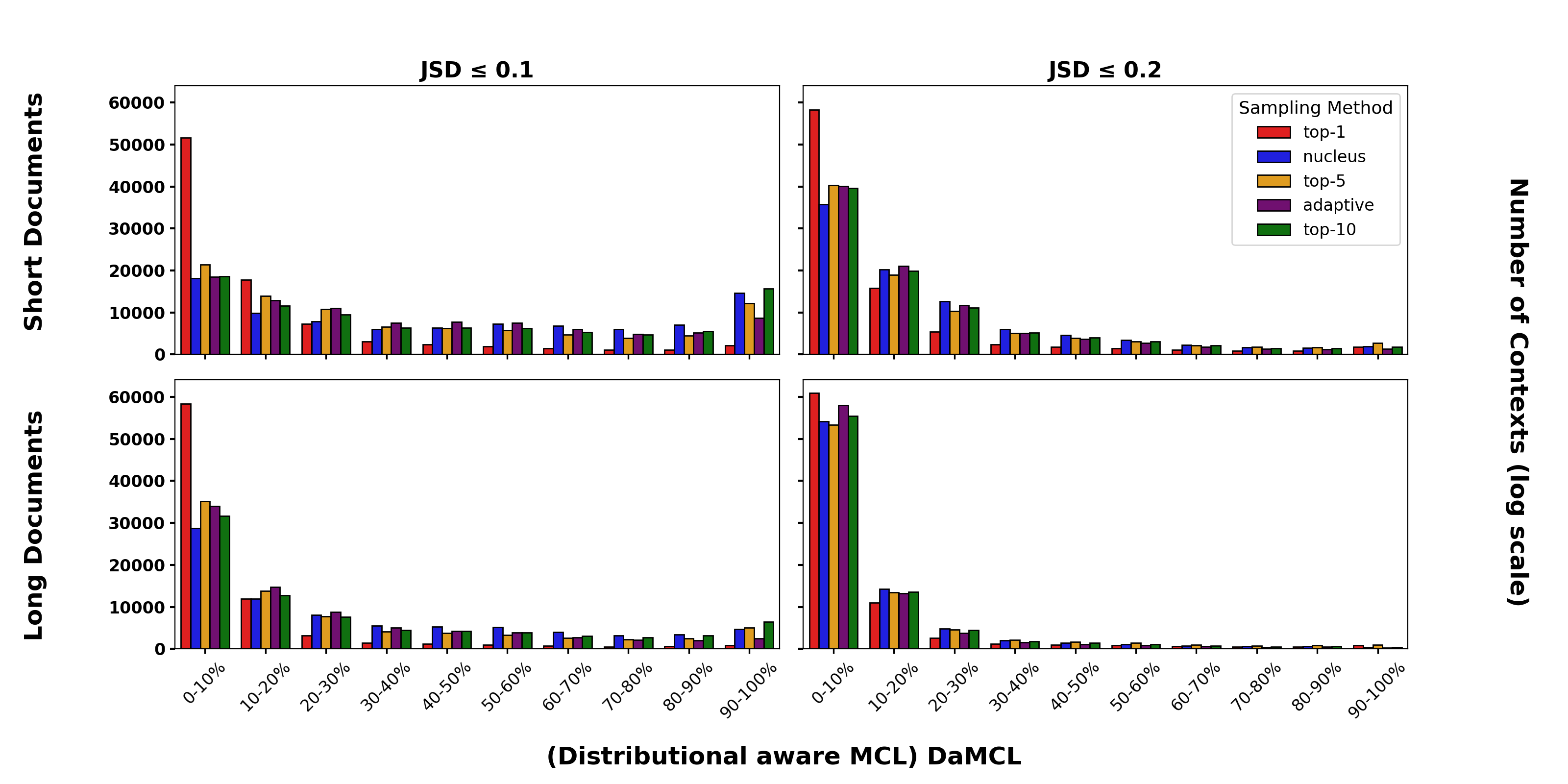
- 论文提出分布感知最小语境长度(DaMCL)作为MCL的代理,用于识别需要长语境的序列,无需真实标签。
- 实验表明,DaMCL能有效区分长短语境序列,并基于此设计解码算法,提升了问答任务的性能。
📝 摘要(中文)
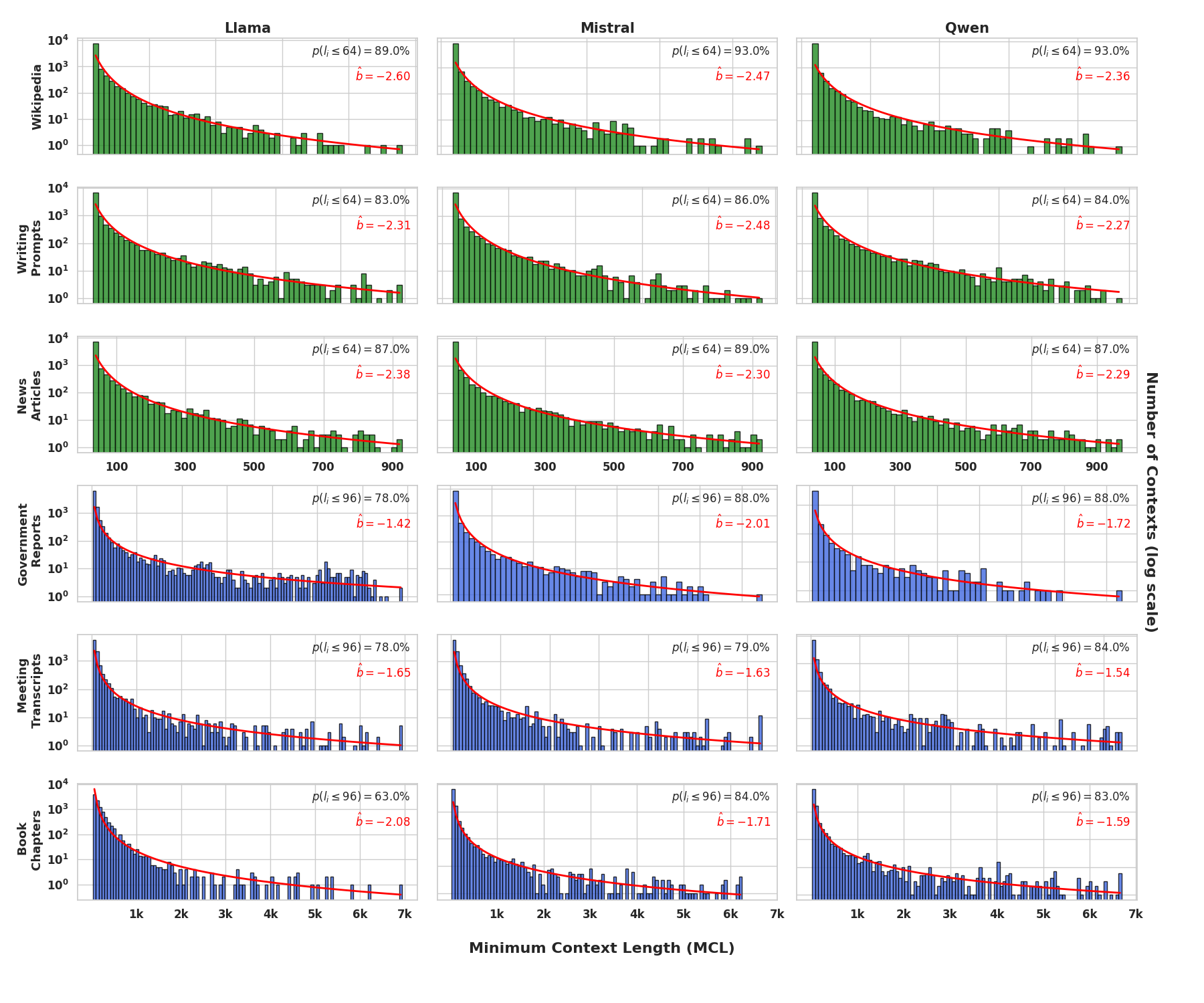
本文研究了短语境主导假设,即对于大多数序列,只需一个小的局部前缀就足以预测其下一个token。利用大型语言模型作为统计预言机,我们测量了在不同长度序列的数据集中,重现准确的完整语境预测所需的最小语境长度(MCL)。对于来自长语境文档的1-7k个token的序列,我们一致发现75-80%的序列最多只需要最后96个token。鉴于短语境token的主导地位,我们进一步探究是否可以检测到需要长语境的具有挑战性的序列,即短语境不足以进行预测的序列。我们引入了一个实用的MCL代理指标,称为分布感知MCL(DaMCL),它不需要知道实际的下一个token,并且与贪婪解码之外的采样策略兼容。实验验证了DaMCL指标的简单阈值处理在检测长语境与短语境序列方面表现出色。最后,为了对抗短语境主导地位对LLM输出分布产生的偏差,我们开发了一种直观的解码算法,该算法利用我们的检测器来识别和提升与长程相关的token。在问答任务和模型架构中,我们证实缓解这种偏差可以提高性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在处理长文本时,由于短语境主导现象导致的效率和准确性问题。现有方法通常采用固定长度的上下文窗口,忽略了不同序列对上下文长度的实际需求差异,导致计算资源的浪费,并且可能因为过度依赖短语境而影响预测的准确性。
核心思路:论文的核心思路是验证并利用“短语境主导”这一假设,即大部分序列的预测只需要较短的上下文。通过识别那些确实需要长语境的“困难”序列,并针对性地进行处理,从而提高整体效率和准确性。DaMCL指标的设计旨在无需真实标签的情况下,估计序列所需的最小上下文长度。
技术框架:论文的技术框架主要包含三个部分:1) 使用大型语言模型作为统计预言机,测量不同序列所需的最小语境长度(MCL);2) 提出分布感知最小语境长度(DaMCL)作为MCL的代理指标,用于识别需要长语境的序列;3) 开发一种基于DaMCL的解码算法,用于提升长语境相关token的概率,从而优化模型输出。
关键创新:论文的关键创新在于提出了DaMCL指标,它是一种无需真实标签的、可用于估计序列所需最小上下文长度的代理指标。与直接计算MCL相比,DaMCL更实用,并且可以与不同的采样策略兼容。此外,基于DaMCL的解码算法能够有效地缓解短语境主导现象对模型输出的影响。
关键设计:DaMCL指标的计算基于模型在不同上下文长度下的预测分布差异。具体来说,它衡量了使用完整上下文和使用较短上下文时,模型预测分布的差异程度。解码算法则根据DaMCL的值,对那些被认为与长语境相关的token进行概率提升。具体的阈值设置和概率提升策略需要根据具体的任务和模型进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,对于1-7k个token的序列,75-80%只需要最多96个token的上下文。DaMCL指标能够有效区分长短语境序列,基于DaMCL的解码算法在问答任务中提升了模型性能。具体提升幅度取决于任务和模型架构,但整体趋势是正向的。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的自然语言处理任务,例如文档摘要、机器翻译、问答系统等。通过自适应地调整上下文长度,可以显著降低计算成本,提高处理效率,并提升模型在长文本理解方面的性能。此外,该研究对于优化大型语言模型的训练和推理过程具有指导意义。
📄 摘要(原文)
We investigate the short-context dominance hypothesis: that for most sequences, a small local prefix suffices to predict their next tokens. Using large language models as statistical oracles, we measure the minimum context length (MCL) needed to reproduce accurate full-context predictions across datasets with sequences of varying lengths. For sequences with 1-7k tokens from long-context documents, we consistently find that 75-80% require only the last 96 tokens at most. Given the dominance of short-context tokens, we then ask whether it is possible to detect challenging long-context sequences for which a short local prefix does not suffice for prediction. We introduce a practical proxy to MCL, called Distributionally Aware MCL (DaMCL), that does not require knowledge of the actual next-token and is compatible with sampling strategies beyond greedy decoding. Our experiments validate that simple thresholding of the metric defining DaMCL achieves high performance in detecting long vs. short context sequences. Finally, to counter the bias that short-context dominance induces in LLM output distributions, we develop an intuitive decoding algorithm that leverages our detector to identify and boost tokens that are long-range-relevant. Across Q&A tasks and model architectures, we confirm that mitigating the bias improves performance.