Bridging Code Graphs and Large Language Models for Better Code Understanding
作者: Zeqi Chen, Zhaoyang Chu, Yi Gui, Feng Guo, Yao Wan, Chuan Shi
分类: cs.CL, cs.SE
发布日期: 2025-12-08
💡 一句话要点
CGBridge:通过桥接代码图和大型语言模型提升代码理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码理解 大型语言模型 代码图 图神经网络 跨模态学习
📋 核心要点
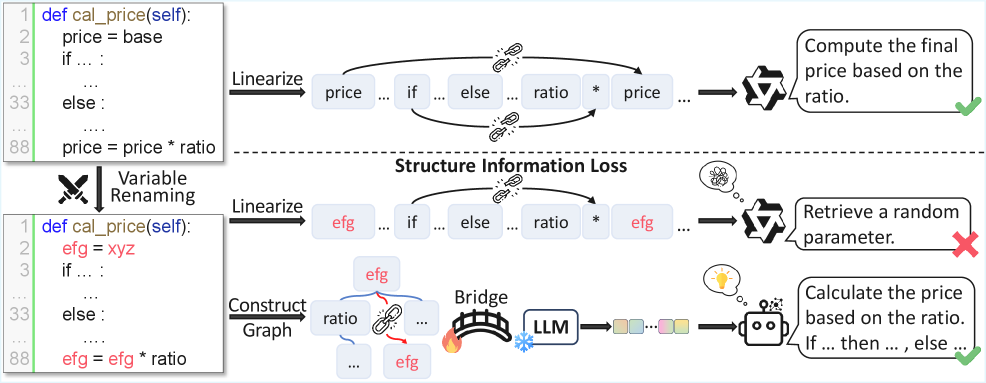
- 现有LLM在代码理解方面依赖线性token序列,缺乏对程序结构语义的有效利用。
- CGBridge通过预训练的代码图编码器和桥接模块,将代码图信息注入LLM,实现结构感知。
- 实验表明,CGBridge在代码摘要和翻译任务上显著优于现有方法,并具有更高的推理效率。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成、摘要和翻译等代码智能任务中表现出卓越的性能。然而,它们对线性化token序列的依赖限制了其理解程序结构语义的能力。虽然之前的研究探索了图增强提示和结构感知预训练,但它们要么受到提示长度的限制,要么需要与大规模指令跟随LLM不兼容的特定于任务的架构更改。为了解决这些限制,本文提出了一种新颖的即插即用方法CGBridge,它通过一个外部可训练的桥接模块,利用代码图信息来增强LLM。CGBridge首先通过在27万个代码图的大规模数据集上进行自监督学习来预训练代码图编码器,以学习结构化的代码语义。然后,它训练一个外部模块,通过跨模态注意力机制对齐代码、图和文本的语义,从而弥合模态差距。最后,桥接模块生成结构化提示,将其注入到冻结的LLM中,并针对下游代码智能任务进行微调。实验表明,CGBridge在原始模型和图增强提示方法上都取得了显著的改进。具体来说,在代码摘要的LLM-as-a-Judge评估中,它产生了16.19%和9.12%的相对增益,在代码翻译的执行准确率方面,产生了9.84%和38.87%的相对增益。此外,CGBridge实现了比LoRA调优模型快4倍以上的推理速度,证明了其在结构感知代码理解方面的有效性和效率。
🔬 方法详解
问题定义:现有的大型语言模型在代码理解任务中,主要依赖于线性化的代码token序列,忽略了代码的结构化信息,例如控制流、数据依赖等。这导致模型难以准确理解代码的语义,尤其是在复杂的代码场景下。现有的图增强方法要么受限于prompt长度,要么需要修改LLM的架构,难以应用于大规模的指令跟随LLM。
核心思路:CGBridge的核心思路是利用代码图来显式地表示代码的结构化信息,并通过一个可训练的桥接模块,将代码图的语义信息融入到大型语言模型中。这种方法无需修改LLM的架构,并且可以灵活地应用于各种代码理解任务。
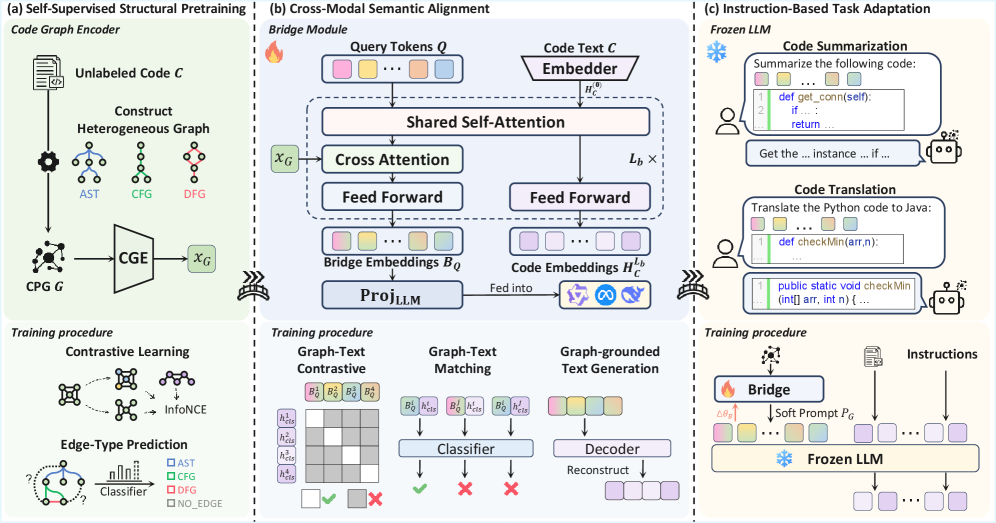
技术框架:CGBridge包含三个主要阶段:1) 代码图编码器预训练:使用自监督学习在大规模代码图数据集上预训练一个代码图编码器,学习代码的结构化语义表示。2) 桥接模块训练:训练一个外部的桥接模块,通过跨模态注意力机制,将代码、图和文本的语义对齐,弥合模态差距。3) LLM微调:使用桥接模块生成的结构化提示,注入到冻结的LLM中,并针对下游代码智能任务进行微调。
关键创新:CGBridge的关键创新在于提出了一个外部的、可训练的桥接模块,用于将代码图的结构化信息融入到大型语言模型中。这种方法无需修改LLM的架构,并且可以灵活地应用于各种代码理解任务。此外,CGBridge还通过自监督学习预训练代码图编码器,有效地学习了代码的结构化语义表示。
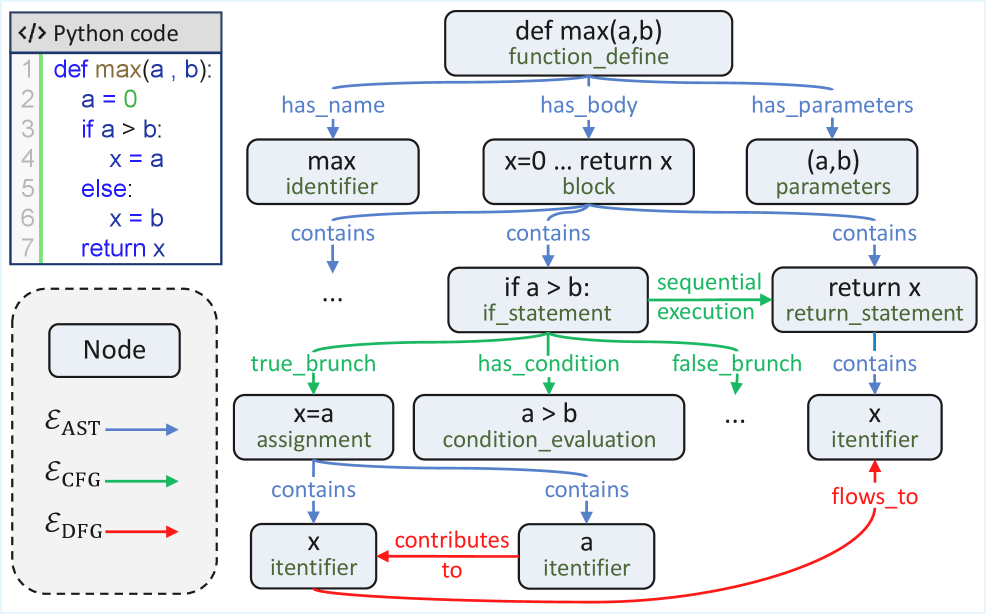
关键设计:代码图编码器采用Graph Neural Network (GNN)结构,例如GCN或GAT。桥接模块使用Transformer架构,包含跨模态注意力层,用于对齐代码、图和文本的语义。损失函数包括自监督学习损失(例如对比学习损失)和下游任务的监督学习损失。结构化提示的设计需要根据具体的下游任务进行调整,例如可以包含代码图的节点和边的信息。
🖼️ 关键图片
📊 实验亮点
CGBridge在代码摘要任务的LLM-as-a-Judge评估中,相对于原始模型和图增强提示方法,分别取得了16.19%和9.12%的相对增益。在代码翻译任务的执行准确率方面,分别取得了9.84%和38.87%的相对增益。此外,CGBridge的推理速度比LoRA调优模型快4倍以上,表明其具有较高的效率。
🎯 应用场景
CGBridge可应用于多种代码智能任务,如代码摘要、代码翻译、代码缺陷检测、代码补全等。通过提升代码理解能力,可以提高软件开发的效率和质量,降低维护成本。未来,该方法可以扩展到其他结构化数据的理解任务,例如知识图谱推理、生物信息学等。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable performance in code intelligence tasks such as code generation, summarization, and translation. However, their reliance on linearized token sequences limits their ability to understand the structural semantics of programs. While prior studies have explored graphaugmented prompting and structure-aware pretraining, they either suffer from prompt length constraints or require task-specific architectural changes that are incompatible with large-scale instructionfollowing LLMs. To address these limitations, this paper proposes CGBridge, a novel plug-and-play method that enhances LLMs with Code Graph information through an external, trainable Bridge module. CGBridge first pre-trains a code graph encoder via selfsupervised learning on a large-scale dataset of 270K code graphs to learn structural code semantics. It then trains an external module to bridge the modality gap among code, graph, and text by aligning their semantics through cross-modal attention mechanisms. Finally, the bridge module generates structure-informed prompts, which are injected into a frozen LLM, and is fine-tuned for downstream code intelligence tasks. Experiments show that CGBridge achieves notable improvements over both the original model and the graphaugmented prompting method. Specifically, it yields a 16.19% and 9.12% relative gain in LLM-as-a-Judge on code summarization, and a 9.84% and 38.87% relative gain in Execution Accuracy on code translation. Moreover, CGBridge achieves over 4x faster inference than LoRA-tuned models, demonstrating both effectiveness and efficiency in structure-aware code understanding.