Enhancing Agentic RL with Progressive Reward Shaping and Value-based Sampling Policy Optimization
作者: Jianghao Su, Xia Zeng, Luhui Liu, Chao Luo, Ye Chen, Zhuoran Zhuang
分类: cs.CL
发布日期: 2025-12-08 (更新: 2026-01-20)
💡 一句话要点
提出PRS和VSPO,提升Agentic RL在工具集成推理任务中的性能与泛化性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic RL 工具集成推理 奖励塑造 策略优化 大语言模型 强化学习 课程学习 价值评估
📋 核心要点
- 现有Agentic RL方法在优化工具集成推理LLM时,面临奖励稀疏和梯度退化两大挑战,限制了学习效率。
- 论文提出渐进式奖励塑造(PRS)和基于价值的采样策略优化(VSPO),分别解决奖励稀疏和梯度退化问题。
- 实验表明,PRS和VSPO显著提升了模型在短文本和长文本问答任务上的性能、稳定性和泛化能力。
📝 摘要(中文)
本文针对工具集成推理(TIR)赋能的大语言模型(LLM)在Agentic强化学习(RL)中面临的挑战,即稀疏奖励和Group Relative Policy Optimization (GRPO)中的梯度退化问题,提出了两种互补技术:渐进式奖励塑造(PRS)和基于价值的采样策略优化(VSPO)。PRS是一种课程学习式的奖励设计,通过引入密集的阶段性反馈,鼓励模型逐步掌握工具调用、事实正确性和答案质量。VSPO是一种增强的GRPO变体,使用任务价值指标选择的提示替换零优势样本,并应用价值平滑裁剪来稳定梯度更新。在多个短文本和长文本问答基准上的实验表明,PRS始终优于传统的二元奖励,并且VSPO实现了卓越的稳定性、更快的收敛速度和更高的最终性能。PRS和VSPO共同作用,使得基于LLM的TIR代理在不同领域中具有更好的泛化能力。
🔬 方法详解
问题定义:Agentic RL在优化工具集成推理(TIR)的大语言模型(LLM)时,面临两个主要问题。一是奖励信号稀疏且缺乏指导性,例如二元0-1奖励,难以指导中间步骤的学习。二是Group Relative Policy Optimization (GRPO)中存在梯度退化问题,同一rollout组内的相同奖励会导致零优势,降低样本效率。
核心思路:论文的核心思路是通过更精细的奖励设计和更有效的策略优化方法来解决上述问题。PRS通过课程学习的思想,逐步引导模型学习,从简单的工具调用到复杂的答案生成。VSPO则通过价值评估来选择更有价值的样本,并稳定梯度更新,从而提高学习效率。
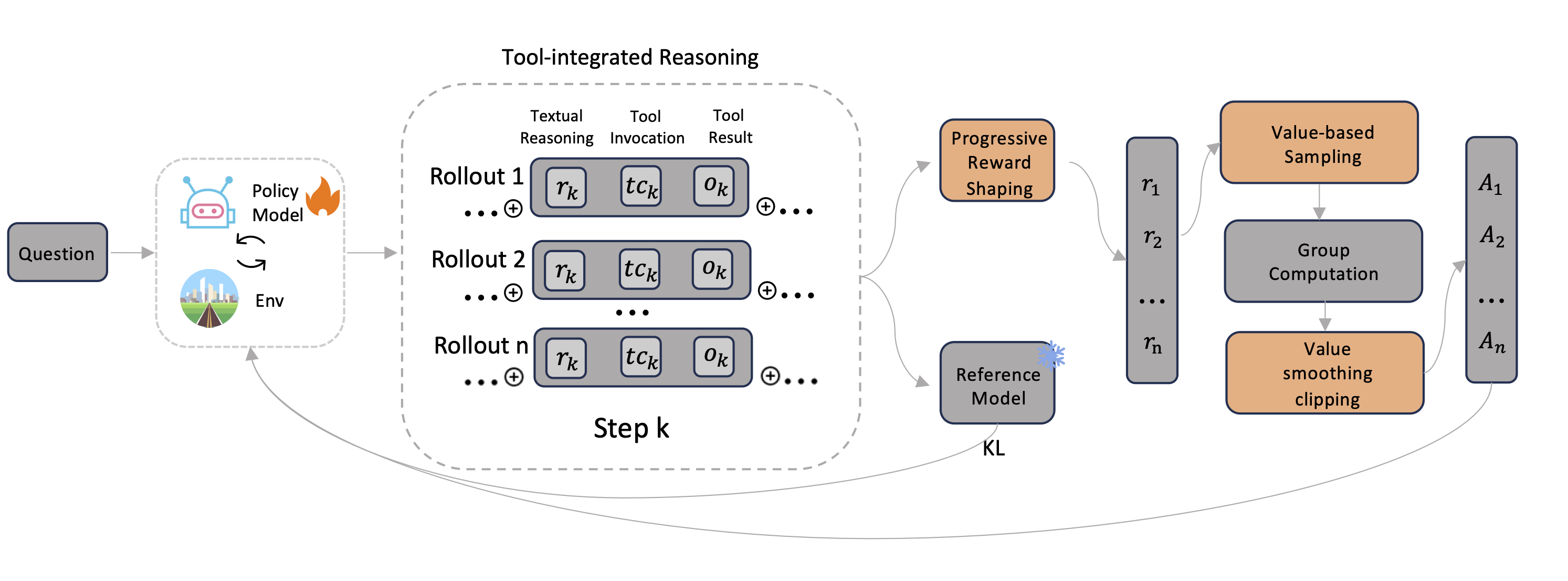
技术框架:整体框架包括LLM作为智能体,通过工具调用与环境交互,并根据环境反馈进行学习。PRS负责设计奖励函数,提供更密集的反馈信号。VSPO则在GRPO的基础上,改进了样本选择和梯度更新方式。主要模块包括:工具调用模块、奖励计算模块(PRS)、样本选择模块(VSPO)和策略更新模块。
关键创新:论文的关键创新在于PRS和VSPO的结合使用。PRS通过渐进式的奖励设计,解决了奖励稀疏的问题。VSPO则通过价值评估和梯度裁剪,解决了GRPO中的梯度退化问题,并提高了学习的稳定性。
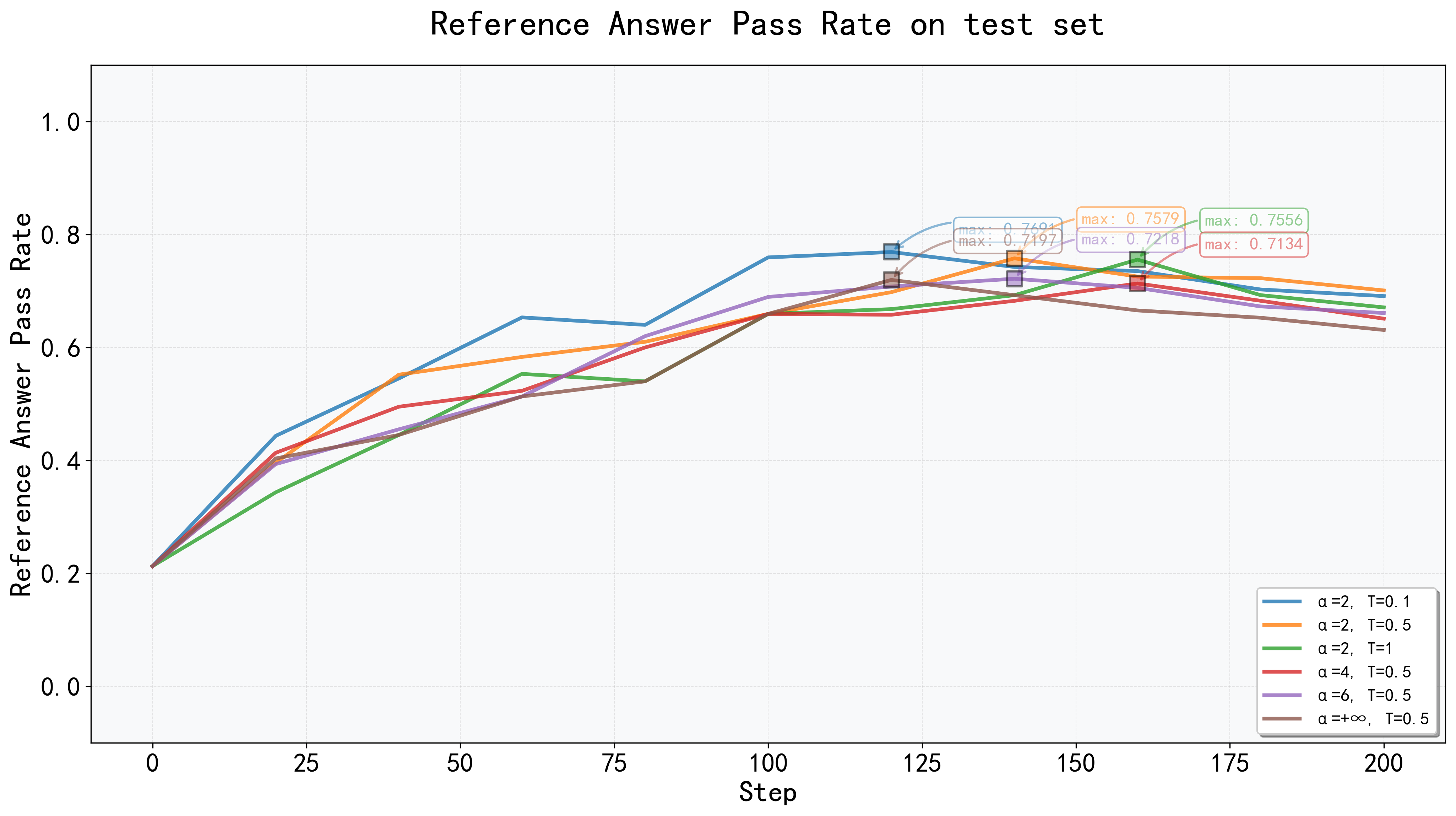
关键设计:PRS的关键设计在于奖励函数的具体形式,例如在短文本问答中,使用长度感知的BLEU评分来奖励简洁的答案;在长文本问答中,使用LLM作为裁判来评估答案质量,并防止奖励hacking。VSPO的关键设计在于任务价值指标的选取,以及价值平滑裁剪的幅度。
🖼️ 关键图片
📊 实验亮点
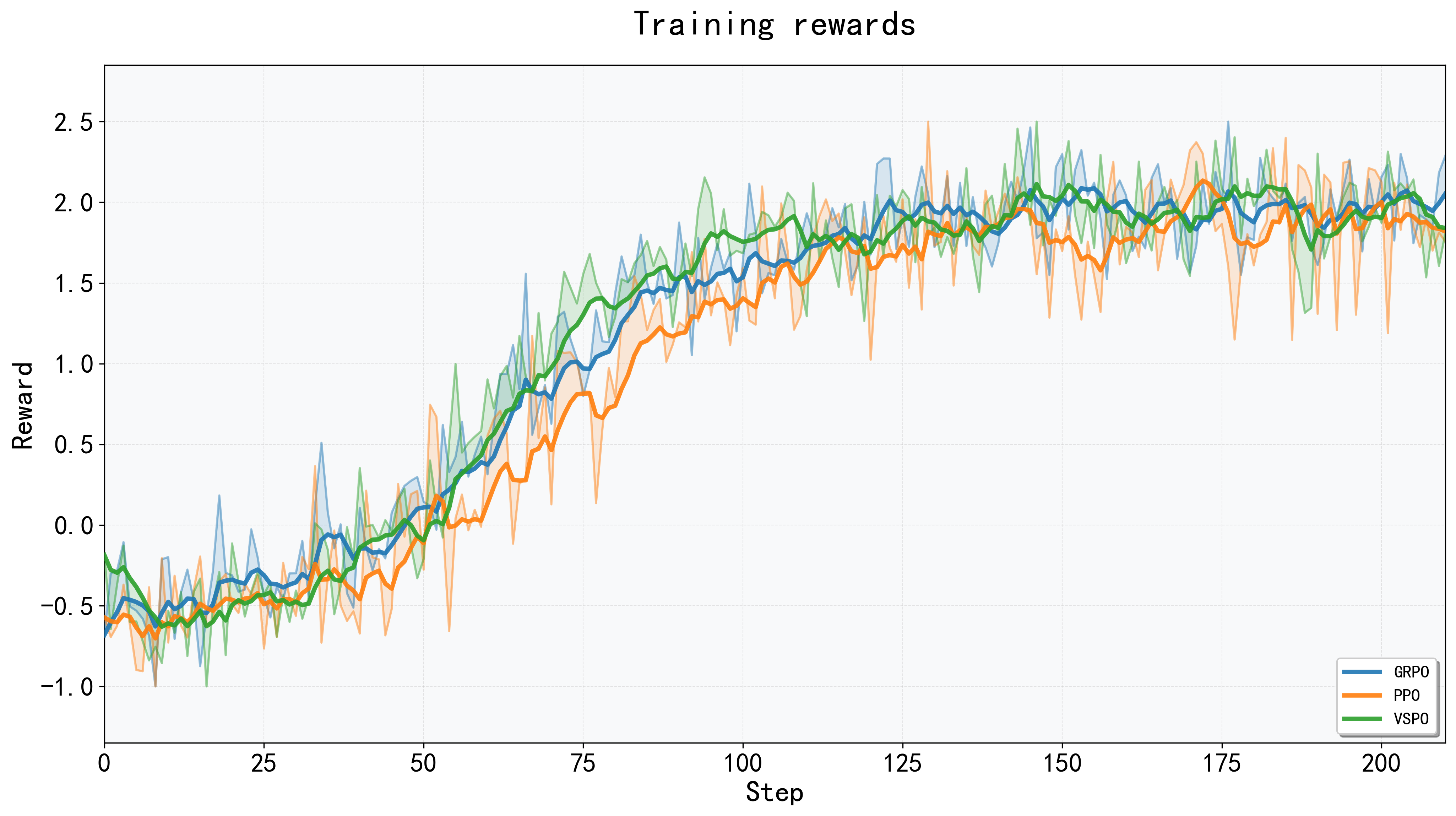
实验结果表明,PRS在短文本和长文本问答任务中始终优于传统的二元奖励。VSPO相比于SFT、PPO和GRPO等基线方法,实现了更高的稳定性、更快的收敛速度和更高的最终性能。例如,在某个长文本问答基准上,VSPO相比于GRPO,性能提升了10%以上,并且收敛速度加快了20%。
🎯 应用场景
该研究成果可应用于各种需要工具集成推理的场景,例如智能客服、自动报告生成、科学研究助手等。通过提升Agentic RL的性能和泛化能力,可以构建更智能、更可靠的AI系统,从而提高工作效率和决策质量。未来,该方法有望扩展到更复杂的任务和领域,例如机器人控制、自动驾驶等。
📄 摘要(原文)
Large Language Models (LLMs) empowered with Tool-Integrated Reasoning (TIR) can iteratively plan, call external tools, and integrate returned information to solve complex, long-horizon reasoning tasks. Agentic Reinforcement Learning (Agentic RL) optimizes such models over full tool-interaction trajectories, but two key challenges hinder effectiveness: (1) Sparse, non-instructive rewards, such as binary 0-1 verifiable signals, provide limited guidance for intermediate steps and slow convergence; (2) Gradient degradation in Group Relative Policy Optimization (GRPO), where identical rewards within a rollout group yield zero advantage, which reducing sample efficiency. To address these challenges, we propose two complementary techniques: Progressive Reward Shaping (PRS) and Value-based Sampling Policy Optimization (VSPO). PRS is a curriculum-inspired reward design that introduces dense, stage-wise feedback - encouraging models to first master parseable and properly formatted tool calls, then optimize for factual correctness and answer quality. We instantiate PRS for short-form QA (with a length-aware BLEU to fairly score concise answers) and long-form QA (with LLM-as-a-Judge scoring to prevent reward hacking). VSPO is an enhanced GRPO variant that replaces zero advantages samples with prompts selected by a task-value metric balancing difficulty and uncertainty, and applies value-smoothing clipping to stabilize gradient updates. Experiments on multiple short-form and long-form QA benchmarks show that PRS consistently outperforms traditional binary rewards, and VSPO achieves superior stability, faster convergence, and higher final performance compared to SFT, PPO and GRPO baselines. Together, PRS and VSPO yield LLM-based TIR agents that generalize better across domains.