DART: Leveraging Multi-Agent Disagreement for Tool Recruitment in Multimodal Reasoning
作者: Nithin Sivakumaran, Justin Chih-Yao Chen, David Wan, Yue Zhang, Jaehong Yoon, Elias Stengel-Eskin, Mohit Bansal
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-12-08
备注: Code: https://github.com/nsivaku/dart
💡 一句话要点
DART:利用多智能体分歧,在多模态推理中进行工具选择
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态推理 工具选择 多智能体系统 视觉问答 分歧解决
📋 核心要点
- 现有视觉工具增强大语言模型或视觉语言模型时,面临工具选择的挑战,即如何决定调用哪些工具以及何时调用。
- DART框架利用多个辩论智能体之间的分歧,识别并调用能够解决分歧的视觉工具,从而促进更有效的多智能体讨论。
- 实验表明,DART在多个基准测试中优于现有的多智能体辩论和单智能体工具调用方法,并在医疗数据集上表现出良好的适应性。
📝 摘要(中文)
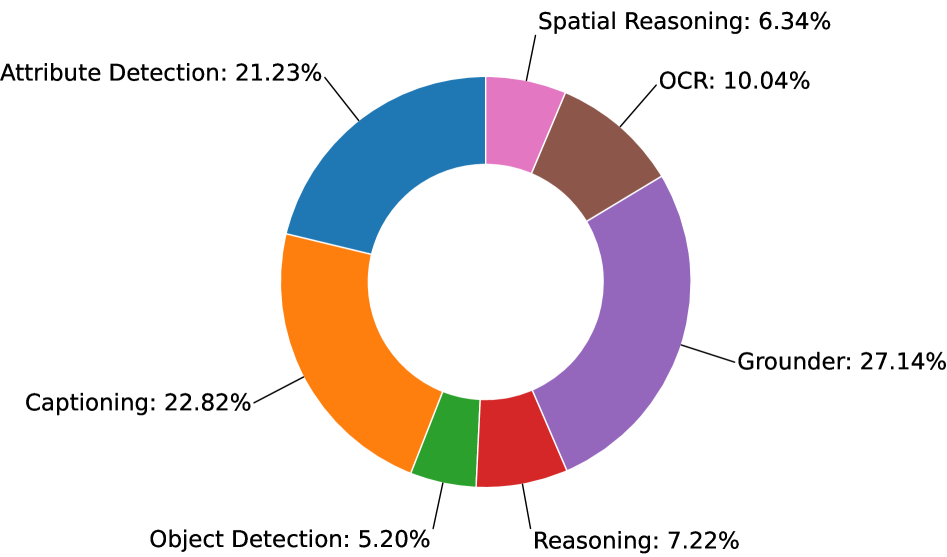
本文提出了一种名为DART的多智能体框架,旨在利用多个辩论视觉智能体之间的分歧来识别有用的视觉工具(例如,目标检测、OCR、空间推理等),从而解决智能体间的分歧。这些工具通过引入新信息,并提供与专家工具对齐的一致性评分来突出与专家工具达成一致的智能体,从而促进富有成效的多智能体讨论。我们使用一个聚合智能体,通过提供智能体输出和工具信息来选择最佳答案。在四个不同的基准测试中,DART优于多智能体辩论以及单智能体工具调用框架,在A-OKVQA和MMMU上分别超过了次优基线(带有判断模型的多智能体辩论)3.4%和2.4%。DART也能很好地适应应用领域中的新工具,在M3D医疗数据集上比其他强大的工具调用、单智能体和多智能体基线提高了1.3%。此外,我们测量了各轮次之间的文本重叠,以突出显示DART中比现有方法更丰富的讨论。最后,我们研究了工具调用分布,发现各种工具被可靠地用于帮助解决分歧。
🔬 方法详解
问题定义:论文旨在解决多模态推理中,如何有效地选择和利用外部视觉工具来增强大型语言模型或视觉语言模型的问题。现有方法在工具选择上存在困难,无法充分利用工具的专业知识来解决智能体之间的分歧。
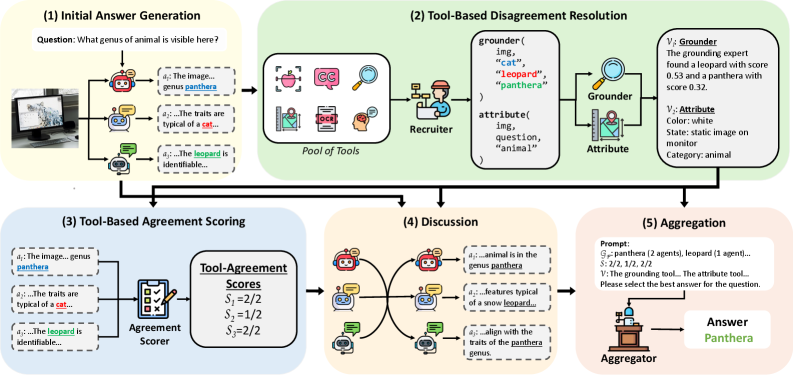
核心思路:论文的核心思路是利用多个智能体之间的辩论和分歧来驱动工具的选择。当智能体之间存在分歧时,系统会识别出能够提供相关信息的视觉工具,并利用这些工具来解决分歧,从而提高推理的准确性和可靠性。
技术框架:DART框架包含多个辩论智能体、一个工具选择模块和一个聚合智能体。辩论智能体负责生成答案并进行辩论;工具选择模块根据智能体之间的分歧选择合适的视觉工具;聚合智能体负责整合所有智能体的输出和工具信息,选择最佳答案。整个流程包括:1) 多个智能体独立生成答案;2) 评估智能体之间的分歧;3) 根据分歧选择合适的视觉工具;4) 利用选定的工具为智能体提供额外信息;5) 智能体基于工具信息更新答案;6) 聚合智能体选择最佳答案。
关键创新:DART的关键创新在于利用多智能体分歧来驱动工具选择。与传统的单智能体工具调用方法相比,DART能够更有效地识别出需要工具辅助的场景,并选择最合适的工具来解决问题。此外,DART还引入了工具对齐的一致性评分,用于评估智能体与专家工具的一致性,从而更好地促进讨论。
关键设计:工具选择模块的设计是关键。该模块需要能够准确地识别智能体之间的分歧,并选择能够提供相关信息的视觉工具。具体的实现细节(例如,如何量化分歧、如何选择工具)在论文中可能没有详细描述,属于未知信息。损失函数和网络结构等细节也未在摘要中提及,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,DART在A-OKVQA和MMMU基准测试中分别超过了次优基线3.4%和2.4%。在M3D医疗数据集上,DART比其他强大的工具调用、单智能体和多智能体基线提高了1.3%。这些结果表明,DART能够有效地利用多智能体分歧和外部工具来提高多模态推理的性能。
🎯 应用场景
DART框架可应用于各种需要多模态推理的场景,例如视觉问答、医学图像诊断、机器人导航等。通过利用外部工具的专业知识,DART能够提高推理的准确性和可靠性,从而在实际应用中发挥重要作用。未来,DART有望被应用于更广泛的领域,例如自动驾驶、智能客服等。
📄 摘要(原文)
Specialized visual tools can augment large language models or vision language models with expert knowledge (e.g., grounding, spatial reasoning, medical knowledge, etc.), but knowing which tools to call (and when to call them) can be challenging. We introduce DART, a multi-agent framework that uses disagreements between multiple debating visual agents to identify useful visual tools (e.g., object detection, OCR, spatial reasoning, etc.) that can resolve inter-agent disagreement. These tools allow for fruitful multi-agent discussion by introducing new information, and by providing tool-aligned agreement scores that highlight agents in agreement with expert tools, thereby facilitating discussion. We utilize an aggregator agent to select the best answer by providing the agent outputs and tool information. We test DART on four diverse benchmarks and show that our approach improves over multi-agent debate as well as over single agent tool-calling frameworks, beating the next-strongest baseline (multi-agent debate with a judge model) by 3.4% and 2.4% on A-OKVQA and MMMU respectively. We also find that DART adapts well to new tools in applied domains, with a 1.3% improvement on the M3D medical dataset over other strong tool-calling, single agent, and multi-agent baselines. Additionally, we measure text overlap across rounds to highlight the rich discussion in DART compared to existing multi-agent methods. Finally, we study the tool call distribution, finding that diverse tools are reliably used to help resolve disagreement.