Leveraging KV Similarity for Online Structured Pruning in LLMs
作者: Jungmin Lee, Gwangeun Byeon, Yulhwa Kim, Seokin Hong
分类: cs.CL, cs.AI
发布日期: 2025-12-08
💡 一句话要点
提出Token Filtering,利用KV相似性实现在线LLM结构化剪枝。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 结构化剪枝 在线剪枝 键值相似性 模型加速
📋 核心要点
- 现有LLM剪枝方法依赖离线校准数据,泛化性差,导致推理不稳定。
- Token Filtering通过在线计算token的键值相似性,动态剪枝冗余token,无需校准。
- 实验表明,Token Filtering在多种LLM上优于现有结构化剪枝方法,保持了较高准确率。
📝 摘要(中文)
剪枝是加速大型语言模型(LLM)推理的一种有前景的方法,但现有方法通常存在不稳定性,因为它们依赖于可能无法泛化到各种输入的离线校准数据。本文提出Token Filtering,一种轻量级的在线结构化剪枝技术,它直接在推理过程中做出剪枝决策,而无需任何校准数据。其核心思想是通过联合键值相似性来衡量token冗余度,并跳过冗余的注意力计算,从而在保留关键信息的同时降低推理成本。为了进一步提高稳定性,我们设计了一种方差感知融合策略,可以自适应地加权各个头的键和值相似性,确保即使在高剪枝率下也能保留信息丰富的token。这种设计不引入额外的内存开销,并为token重要性提供了更可靠的标准。在LLaMA-2 (7B/13B)、LLaMA-3 (8B)和Mistral (7B)上的大量实验表明,Token Filtering始终优于先前的结构化剪枝方法,在常识推理基准上保持了准确性,并在诸如MMLU等具有挑战性的任务上保持了强大的性能,即使在50%的剪枝率下也是如此。
🔬 方法详解
问题定义:现有LLM的结构化剪枝方法依赖于离线校准数据,这些数据可能无法代表所有可能的输入,导致剪枝策略在不同输入上的泛化能力较差,从而影响模型推理的稳定性和准确性。因此,需要一种能够适应不同输入的在线剪枝方法。
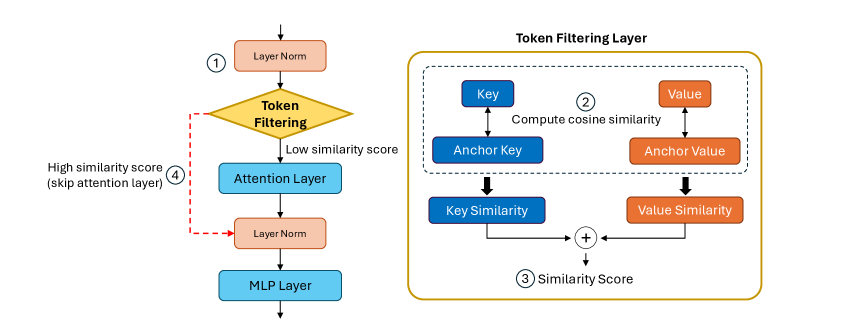
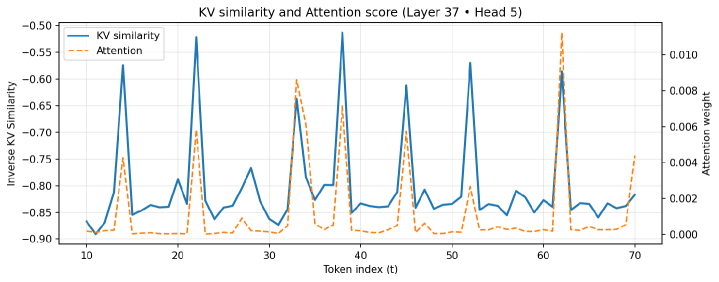
核心思路:Token Filtering的核心思想是利用Transformer模型中Key和Value向量的相似性来衡量token的冗余程度。如果两个token的Key和Value向量非常相似,则认为其中一个token是冗余的,可以被安全地剪枝掉,从而减少计算量。这种方法无需离线校准数据,能够根据输入动态地进行剪枝。
技术框架:Token Filtering主要包含以下几个阶段:1) 计算每个token的Key和Value向量;2) 计算token之间的Key和Value相似度;3) 根据相似度确定需要剪枝的token;4) 跳过被剪枝token的注意力计算。此外,为了提高剪枝的稳定性,引入了方差感知融合策略,自适应地调整Key和Value相似度的权重。
关键创新:Token Filtering的关键创新在于提出了一种基于Key-Value相似性的在线结构化剪枝方法,该方法无需离线校准数据,能够根据输入动态地进行剪枝。此外,方差感知融合策略能够提高剪枝的稳定性,确保重要token不被错误地剪枝掉。
关键设计:方差感知融合策略是Token Filtering的关键设计之一。该策略根据每个注意力头的Key和Value相似度的方差,自适应地调整Key和Value相似度的权重。具体来说,如果某个注意力头的Key相似度方差较大,则说明Key相似度在该注意力头中更具有区分性,因此应该赋予更高的权重。反之,如果Value相似度方差较大,则应该赋予Value相似度更高的权重。这种自适应加权策略能够更准确地衡量token的冗余程度,提高剪枝的稳定性。
🖼️ 关键图片
📊 实验亮点
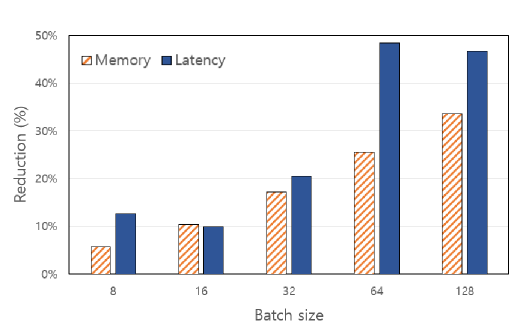
在LLaMA-2 (7B/13B)、LLaMA-3 (8B)和Mistral (7B)模型上进行的实验表明,Token Filtering在50%的剪枝率下,仍然能够在常识推理基准上保持准确性,并在MMLU等具有挑战性的任务上保持强大的性能,优于现有的结构化剪枝方法。
🎯 应用场景
Token Filtering可应用于各种需要加速LLM推理的场景,例如移动设备上的本地推理、边缘计算以及对延迟敏感的在线服务。通过降低计算成本,该方法可以显著提高LLM的部署效率和可扩展性,并降低能源消耗,具有重要的实际应用价值。
📄 摘要(原文)
Pruning has emerged as a promising direction for accelerating large language model (LLM) inference, yet existing approaches often suffer from instability because they rely on offline calibration data that may not generalize across inputs. In this work, we introduce Token Filtering, a lightweight online structured pruning technique that makes pruning decisions directly during inference without any calibration data. The key idea is to measure token redundancy via joint key-value similarity and skip redundant attention computations, thereby reducing inference cost while preserving critical information. To further enhance stability, we design a variance-aware fusion strategy that adaptively weights key and value similarity across heads, ensuring that informative tokens are retained even under high pruning ratios. This design introduces no additional memory overhead and provides a more reliable criterion for token importance. Extensive experiments on LLaMA-2 (7B/13B), LLaMA-3 (8B), and Mistral (7B) demonstrate that Token Filtering consistently outperforms prior structured pruning methods, preserving accuracy on commonsense reasoning benchmarks and maintaining strong performance on challenging tasks such as MMLU, even with 50% pruning.