Do Large Language Models Truly Understand Cross-cultural Differences?
作者: Shiwei Guo, Sihang Jiang, Qianxi He, Yanghua Xiao, Jiaqing Liang, Bi Yude, Minggui He, Shimin Tao, Li Zhang
分类: cs.CL
发布日期: 2025-12-08
💡 一句话要点
提出SAGE基准,评估大语言模型在跨文化理解和推理方面的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 跨文化理解 基准测试 情境推理 文化差异
📋 核心要点
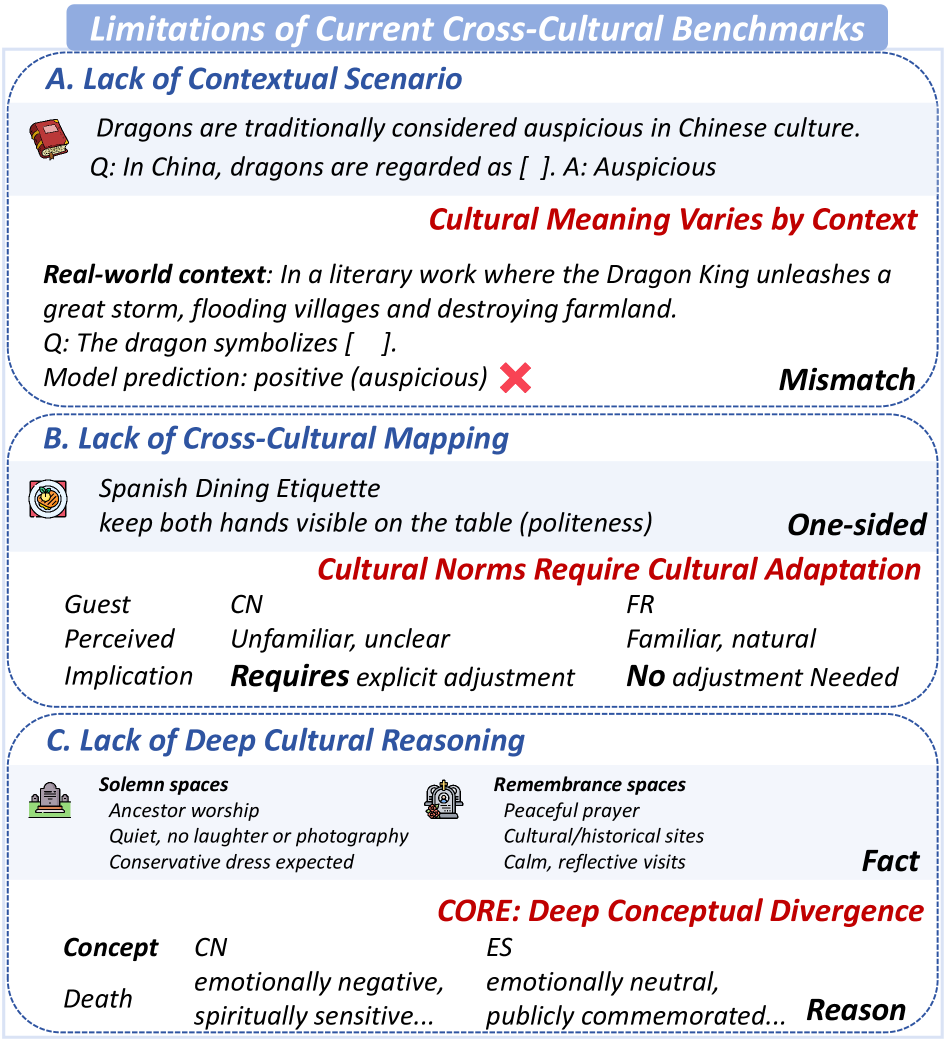
- 现有评估大语言模型跨文化理解能力的基准缺乏情境化场景,跨文化概念映射不足,且深度文化推理能力有限。
- 论文提出SAGE基准,通过跨文化核心概念对齐和生成式任务设计,评估LLMs的跨文化理解和推理能力。
- 实验结果表明,SAGE揭示了模型在跨文化推理中的系统性局限,表明LLMs距离真正细致的跨文化理解还有差距。
📝 摘要(中文)
近年来,大型语言模型(LLMs)在多语言任务中表现出强大的性能。鉴于其广泛的应用,跨文化理解能力是一项至关重要的能力。然而,现有的评估LLMs是否真正具备这种能力的基准存在三个主要局限性:缺乏情境化场景、跨文化概念映射不足以及深度文化推理能力有限。为了解决这些差距,我们提出了SAGE,这是一个基于情境的基准,通过跨文化核心概念对齐和生成式任务设计构建,以评估LLMs的跨文化理解和推理能力。基于文化理论,我们将跨文化能力分为九个维度。利用这个框架,我们策划了210个核心概念,并在15个特定的现实场景中构建了4530个测试项目,这些场景遵循既定的项目设计原则,组织在四个更广泛的跨文化情境类别下。SAGE数据集支持持续扩展,实验证实了其对其他语言的可迁移性。它揭示了模型在维度和场景方面的弱点,暴露了跨文化推理中的系统性局限。虽然已经取得了进展,但LLMs距离真正细致的跨文化理解还有一段距离。为了遵守匿名政策,我们将数据和代码包含在补充材料中。在未来的版本中,我们将在线公开提供它们。
🔬 方法详解
问题定义:论文旨在解决现有评估大语言模型(LLMs)跨文化理解能力的基准存在的问题。现有基准的痛点在于缺乏真实情境,无法充分测试LLMs在复杂文化环境下的推理能力,同时跨文化概念的映射和深度文化推理能力评估不足。
核心思路:论文的核心思路是构建一个更全面、更贴近现实的跨文化理解评估基准。通过情境化的场景设计,并结合跨文化核心概念的对齐,以及生成式任务的设计,来更有效地评估LLMs在跨文化环境下的理解和推理能力。
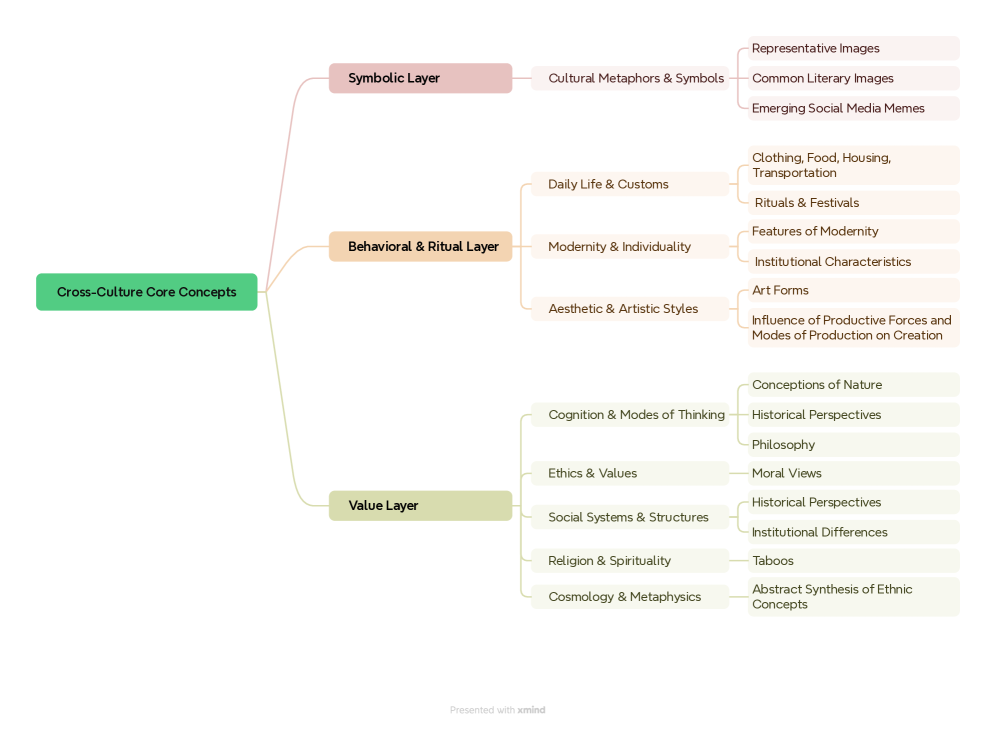
技术框架:SAGE基准的构建主要包含以下几个阶段: 1. 跨文化能力维度划分:基于文化理论,将跨文化能力划分为九个维度。 2. 核心概念选取:在九个维度下,选取210个核心概念。 3. 情境构建:构建15个特定的现实场景,这些场景组织在四个更广泛的跨文化情境类别下。 4. 测试项目生成:在每个场景下,根据核心概念设计4530个测试项目。 5. 数据集扩展:SAGE数据集支持持续扩展,并具有对其他语言的可迁移性。
关键创新:SAGE基准的关键创新在于其情境化的设计和对跨文化核心概念的对齐。与以往的基准相比,SAGE更注重在真实情境下评估LLMs的跨文化理解能力,从而更准确地反映LLMs在实际应用中的表现。此外,SAGE还考虑了跨文化能力的多个维度,从而更全面地评估LLMs的跨文化理解能力。
关键设计:SAGE的关键设计包括: 1. 情境化场景设计:每个场景都基于真实的跨文化情境,例如商务谈判、社交活动等。 2. 核心概念对齐:每个测试项目都与一个或多个核心概念相关联,确保测试的针对性。 3. 生成式任务设计:采用生成式任务,要求LLMs根据给定的情境生成相应的文本,从而更全面地评估LLMs的理解和推理能力。 4. 多语言支持:SAGE数据集支持多种语言,可以用于评估LLMs在不同语言环境下的跨文化理解能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SAGE基准能够有效揭示LLMs在跨文化理解和推理方面的不足。具体而言,模型在某些维度和场景下的表现明显较差,暴露了跨文化推理中的系统性局限。SAGE数据集也展现出良好的可迁移性,能够应用于其他语言的评估。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型在跨文化交流、国际商务、全球化教育等领域的应用能力。通过SAGE基准,可以更准确地了解LLMs在处理不同文化背景信息时的表现,从而指导模型优化,减少文化误解和偏见,促进更有效的跨文化沟通。
📄 摘要(原文)
In recent years, large language models (LLMs) have demonstrated strong performance on multilingual tasks. Given its wide range of applications, cross-cultural understanding capability is a crucial competency. However, existing benchmarks for evaluating whether LLMs genuinely possess this capability suffer from three key limitations: a lack of contextual scenarios, insufficient cross-cultural concept mapping, and limited deep cultural reasoning capabilities. To address these gaps, we propose SAGE, a scenario-based benchmark built via cross-cultural core concept alignment and generative task design, to evaluate LLMs' cross-cultural understanding and reasoning. Grounded in cultural theory, we categorize cross-cultural capabilities into nine dimensions. Using this framework, we curated 210 core concepts and constructed 4530 test items across 15 specific real-world scenarios, organized under four broader categories of cross-cultural situations, following established item design principles. The SAGE dataset supports continuous expansion, and experiments confirm its transferability to other languages. It reveals model weaknesses across both dimensions and scenarios, exposing systematic limitations in cross-cultural reasoning. While progress has been made, LLMs are still some distance away from reaching a truly nuanced cross-cultural understanding. In compliance with the anonymity policy, we include data and code in the supplement materials. In future versions, we will make them publicly available online.