Prompting-in-a-Series: Psychology-Informed Contents and Embeddings for Personality Recognition With Decoder-Only Models
作者: Jing Jie Tan, Ban-Hoe Kwan, Danny Wee-Kiat Ng, Yan-Chai Hum, Anissa Mokraoui, Shih-Yu Lo
分类: cs.CL, cs.AI
发布日期: 2025-12-07
备注: 16 pages
期刊: IEEE Transactions on Computational Social Systems, pages 1-15, 2025
DOI: 10.1109/TCSS.2025.3593323
💡 一句话要点
提出PICEPR算法,利用心理学知识增强Decoder-Only模型在人格识别任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人格识别 大型语言模型 心理学 Prompting-in-a-Series Decoder-Only模型
📋 核心要点
- 现有方法在人格识别任务中存在不足,难以有效利用大型语言模型生成的内容。
- PICEPR算法通过心理学知识指导内容生成和嵌入表示,从而提升人格识别的准确性。
- 实验结果表明,PICEPR算法在人格识别任务上取得了显著的性能提升,超越了现有技术水平。
📝 摘要(中文)
本研究提出了一种新颖的“Prompting-in-a-Series”算法,称为PICEPR(Psychology-Informed Contents Embeddings for Personality Recognition)。该算法包含两个流程:(a)内容生成和(b)嵌入表示。该方法展示了模块化的Decoder-Only LLM如何总结或生成内容,从而辅助分类或增强人格识别功能,将其作为人格特征提取器和富含人格内容生成器。我们进行了各种实验,以验证PICEPR算法背后的原理。同时,我们还探索了来自OpenAI的\textit{gpt4o}和来自Google的\textit{gemini}等闭源模型,以及来自Mistral AI的\textit{mistral}等开源模型,以比较生成内容的质量。PICEPR算法在人格识别方面取得了新的state-of-the-art性能,提升幅度为5-15%。
🔬 方法详解
问题定义:论文旨在解决人格识别问题,现有方法难以充分利用大型语言模型(LLMs)生成的内容来提升识别精度。现有人格识别方法可能无法有效提取LLM生成文本中蕴含的丰富人格特征,导致识别性能受限。
核心思路:论文的核心思路是利用心理学知识指导LLM生成更具信息量和区分度的人格相关内容,并设计有效的嵌入表示方法来捕捉这些内容中的关键特征。通过“Prompting-in-a-Series”的方式,将人格识别任务分解为内容生成和嵌入表示两个阶段,从而更好地利用LLM的能力。
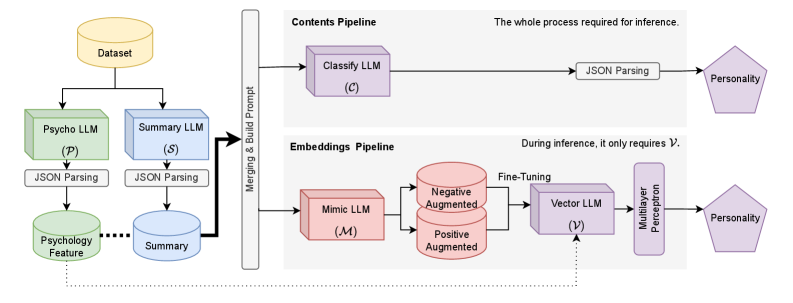
技术框架:PICEPR算法包含两个主要流程:(a)内容生成流程:利用Decoder-Only LLM,通过心理学相关的prompt,生成与人格特征相关的内容,例如对个体行为的描述或对特定情境的反应。(b)嵌入表示流程:将生成的内容转化为向量表示,用于后续的人格分类或识别任务。整体框架利用模块化的Decoder-Only LLM,使其既能作为人格特征提取器,又能作为人格丰富内容生成器。
关键创新:PICEPR算法的关键创新在于:1)将心理学知识融入到LLM的prompt中,引导LLM生成更具信息量和区分度的人格相关内容。2)提出“Prompting-in-a-Series”的算法框架,将人格识别任务分解为内容生成和嵌入表示两个阶段,从而更好地利用LLM的能力。3)通过内容和嵌入两个pipeline,实现了人格特征的有效提取和利用。
关键设计:论文的关键设计包括:1)精心设计的心理学相关的prompt,用于引导LLM生成人格相关内容。2)针对生成内容设计的嵌入表示方法,用于捕捉内容中的关键人格特征。3)对不同LLM(包括闭源和开源模型)的生成内容质量进行比较,选择合适的LLM作为内容生成器。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
PICEPR算法在人格识别任务上取得了新的state-of-the-art性能,相比现有方法,性能提升幅度达到5-15%。实验对比了不同LLM(包括gpt4o、gemini和mistral)生成内容的质量,验证了PICEPR算法的有效性。
🎯 应用场景
该研究成果可应用于心理健康评估、招聘筛选、个性化推荐系统等领域。通过自动识别人格特征,可以为用户提供更精准的服务和支持。未来,该技术有望在人机交互、社交网络分析等领域发挥更大的作用。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities across various natural language processing tasks. This research introduces a novel "Prompting-in-a-Series" algorithm, termed PICEPR (Psychology-Informed Contents Embeddings for Personality Recognition), featuring two pipelines: (a) Contents and (b) Embeddings. The approach demonstrates how a modularised decoder-only LLM can summarize or generate content, which can aid in classifying or enhancing personality recognition functions as a personality feature extractor and a generator for personality-rich content. We conducted various experiments to provide evidence to justify the rationale behind the PICEPR algorithm. Meanwhile, we also explored closed-source models such as \textit{gpt4o} from OpenAI and \textit{gemini} from Google, along with open-source models like \textit{mistral} from Mistral AI, to compare the quality of the generated content. The PICEPR algorithm has achieved a new state-of-the-art performance for personality recognition by 5-15\% improvement. The work repository and models' weight can be found at https://research.jingjietan.com/?q=PICEPR.