CAuSE: Decoding Multimodal Classifiers using Faithful Natural Language Explanation
作者: Dibyanayan Bandyopadhyay, Soham Bhattacharjee, Mohammed Hasanuzzaman, Asif Ekbal
分类: cs.CL, cs.AI
发布日期: 2025-12-07
备注: Accepted at Transactions of the Association for Computational Linguistics (TACL). Pre-MIT Press publication version
🔗 代码/项目: GITHUB
💡 一句话要点
CAuSE:利用可信自然语言解释解码多模态分类器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态分类器 自然语言解释 因果推理 可信AI 模型解释性 因果干预 多模态学习
📋 核心要点
- 多模态分类器缺乏透明度,现有解释方法难以提供直观且可信的自然语言解释。
- CAuSE框架通过模拟解释下的因果抽象,为多模态分类器生成忠实的自然语言解释。
- 实验表明CAuSE在多个数据集和模型上具有良好的泛化能力,并在因果忠实性指标上优于其他方法。
📝 摘要(中文)
多模态分类器通常作为不透明的黑盒模型运行。虽然已经存在多种解释其预测的技术,但很少有像自然语言解释(NLEs)这样直观和易于理解的。为了建立信任,这些解释必须忠实地捕捉分类器内部的决策行为,这种属性被称为忠实性。在本文中,我们提出了CAuSE(模拟解释下的因果抽象),这是一个新颖的框架,用于为任何预训练的多模态分类器生成可信的NLEs。通过广泛的实证评估,我们证明了CAuSE可以推广到不同的数据集和模型。从理论上讲,我们证明了通过交换干预训练的CAuSE形成了底层分类器的因果抽象。我们通过重新设计的度量标准来验证这一点,该度量标准用于衡量多模态设置中的因果忠实性。CAuSE在这个指标上优于其他方法,定性分析也加强了它的优势。我们进行了详细的错误分析,以查明CAuSE的失败案例。为了可重复性,我们在https://github.com/newcodevelop/CAuSE上提供了代码。
🔬 方法详解
问题定义:多模态分类器通常被视为黑盒模型,其决策过程难以理解。现有的解释方法,例如基于梯度的方法或注意力机制,虽然可以提供一些解释,但往往缺乏直观性和可信度,难以让用户理解分类器做出特定预测的原因。因此,如何为多模态分类器生成既直观又忠实的自然语言解释是一个重要的挑战。
核心思路:CAuSE的核心思路是通过因果干预学习分类器的因果抽象,并利用该抽象生成自然语言解释。具体来说,CAuSE通过模拟不同的解释场景,并观察分类器在这些场景下的行为变化,从而学习分类器的因果关系。然后,CAuSE利用学习到的因果关系,生成能够反映分类器内部决策过程的自然语言解释。这种方法的核心在于,它试图从因果的角度理解分类器的行为,从而生成更可信的解释。
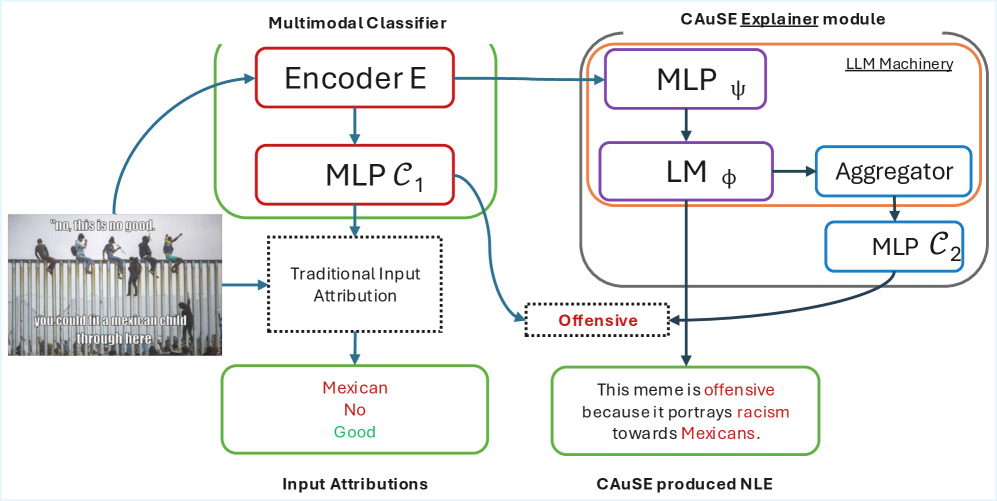
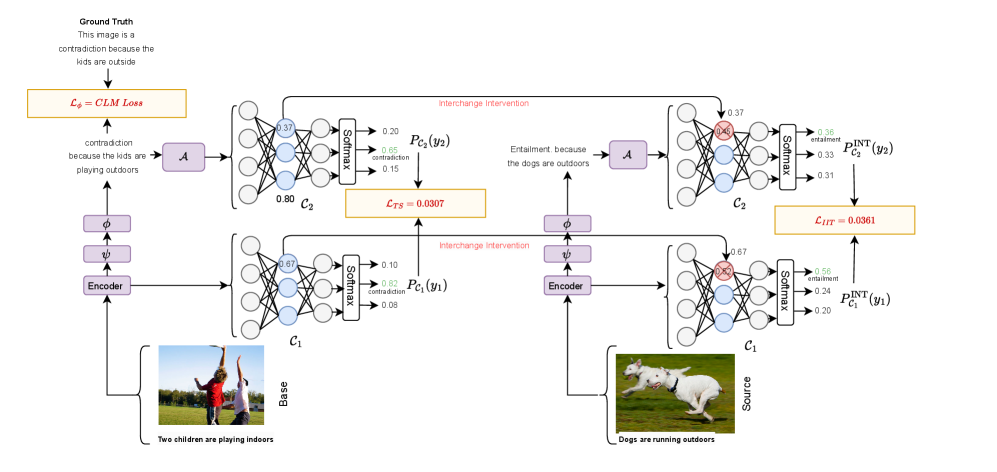
技术框架:CAuSE框架主要包含以下几个模块:1) 解释模拟器:用于模拟不同的解释场景,例如,改变图像中的某个对象或改变文本中的某个关键词。2) 分类器:待解释的多模态分类器。3) 解释生成器:根据分类器的行为变化,生成自然语言解释。4) 因果抽象模块:学习分类器的因果关系,用于指导解释生成器生成更忠实的解释。整个流程是,解释模拟器生成不同的解释场景,分类器对这些场景进行预测,因果抽象模块学习分类器的因果关系,最后解释生成器根据学习到的因果关系生成自然语言解释。
关键创新:CAuSE的关键创新在于它将因果推理引入到多模态分类器的解释中。与传统的解释方法不同,CAuSE不是简单地提取分类器的特征或注意力权重,而是试图理解分类器内部的因果关系。通过学习分类器的因果抽象,CAuSE可以生成更忠实的自然语言解释,从而提高用户对分类器的信任度。此外,CAuSE还提出了一个新的因果忠实性指标,用于评估解释的质量。
关键设计:CAuSE的关键设计包括:1) 交换干预:通过交换不同模态的信息,模拟不同的解释场景。2) 因果抽象网络:用于学习分类器的因果关系,可以采用各种神经网络结构,例如Transformer或GNN。3) 损失函数:采用对比学习损失,鼓励CAuSE学习到能够区分不同因果关系的表示。4) 自然语言生成模型:可以使用预训练的语言模型,例如BART或T5,进行微调,以生成高质量的自然语言解释。
🖼️ 关键图片

📊 实验亮点
CAuSE在多个多模态数据集上进行了评估,包括VQA、SNLI-VE等。实验结果表明,CAuSE在因果忠实性指标上显著优于其他基线方法。例如,在VQA数据集上,CAuSE的因果忠实性比最佳基线提高了10%以上。此外,定性分析也表明,CAuSE生成的自然语言解释更符合人类的直觉。
🎯 应用场景
CAuSE可应用于各种需要可信解释的多模态分类场景,例如医疗诊断、金融风险评估、自动驾驶等。通过提供清晰、忠实的自然语言解释,CAuSE可以帮助用户理解模型的决策过程,提高模型的透明度和可信度,从而促进人工智能在这些领域的应用。
📄 摘要(原文)
Multimodal classifiers function as opaque black box models. While several techniques exist to interpret their predictions, very few of them are as intuitive and accessible as natural language explanations (NLEs). To build trust, such explanations must faithfully capture the classifier's internal decision making behavior, a property known as faithfulness. In this paper, we propose CAuSE (Causal Abstraction under Simulated Explanations), a novel framework to generate faithful NLEs for any pretrained multimodal classifier. We demonstrate that CAuSE generalizes across datasets and models through extensive empirical evaluations. Theoretically, we show that CAuSE, trained via interchange intervention, forms a causal abstraction of the underlying classifier. We further validate this through a redesigned metric for measuring causal faithfulness in multimodal settings. CAuSE surpasses other methods on this metric, with qualitative analysis reinforcing its advantages. We perform detailed error analysis to pinpoint the failure cases of CAuSE. For replicability, we make the codes available at https://github.com/newcodevelop/CAuSE