Large Language Model-Based Generation of Discharge Summaries
作者: Tiago Rodrigues, Carla Teixeira Lopes
分类: cs.CL
发布日期: 2025-12-07
备注: 17 pages, 6 figures
💡 一句话要点
利用大型语言模型自动生成出院总结,提升医疗效率并减少错误。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 出院总结 自然语言处理 医疗信息 文本生成
📋 核心要点
- 现有出院总结编写耗时耗力,易出错,且信息可访问性差,影响患者护理效率。
- 利用大型语言模型自动生成出院总结,旨在减少人工干预,提升信息质量和可访问性。
- 实验表明,专有模型如Gemini在生成高质量出院总结方面表现出色,但开源模型仍需改进。
📝 摘要(中文)
出院总结是由医疗专业人员编写的详细记录患者就诊情况的文件,包含对患者护理至关重要的丰富信息。自动生成出院总结可以显著减少医护人员的工作量,最大限度地减少错误,并确保关键患者信息易于访问和使用。本文探讨了五种大型语言模型(包括开源模型Mistral、Llama 2和专有系统GPT-3、GPT-4、Gemini 1.5 Pro)在此任务中的应用,利用了MIMIC-III的出院总结和病程记录。我们使用精确匹配、软重叠和无参考指标对它们进行了评估。结果表明,专有模型,特别是采用one-shot prompting的Gemini,表现优于其他模型,生成的摘要与黄金标准摘要的相似度最高。开源模型虽然有前景,特别是微调后的Mistral,但在性能上有所滞后,经常出现幻觉和重复信息。临床专家的评估证实了专有模型生成的摘要的实际效用。尽管存在幻觉和信息缺失等挑战,但研究结果表明,只要确保数据隐私,大型语言模型,尤其是专有模型,是自动生成出院总结的有希望的候选方案。
🔬 方法详解
问题定义:论文旨在解决医疗领域中出院总结生成效率低、易出错的问题。现有方法依赖于医护人员手动编写,耗时耗力,且容易出现信息遗漏或不一致的情况。此外,人工编写的出院总结难以保证格式统一,不利于后续的数据分析和利用。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的文本生成能力,通过学习大量的出院总结和病程记录,自动生成高质量的出院总结。这种方法可以显著减少人工干预,提高生成效率,并降低出错率。
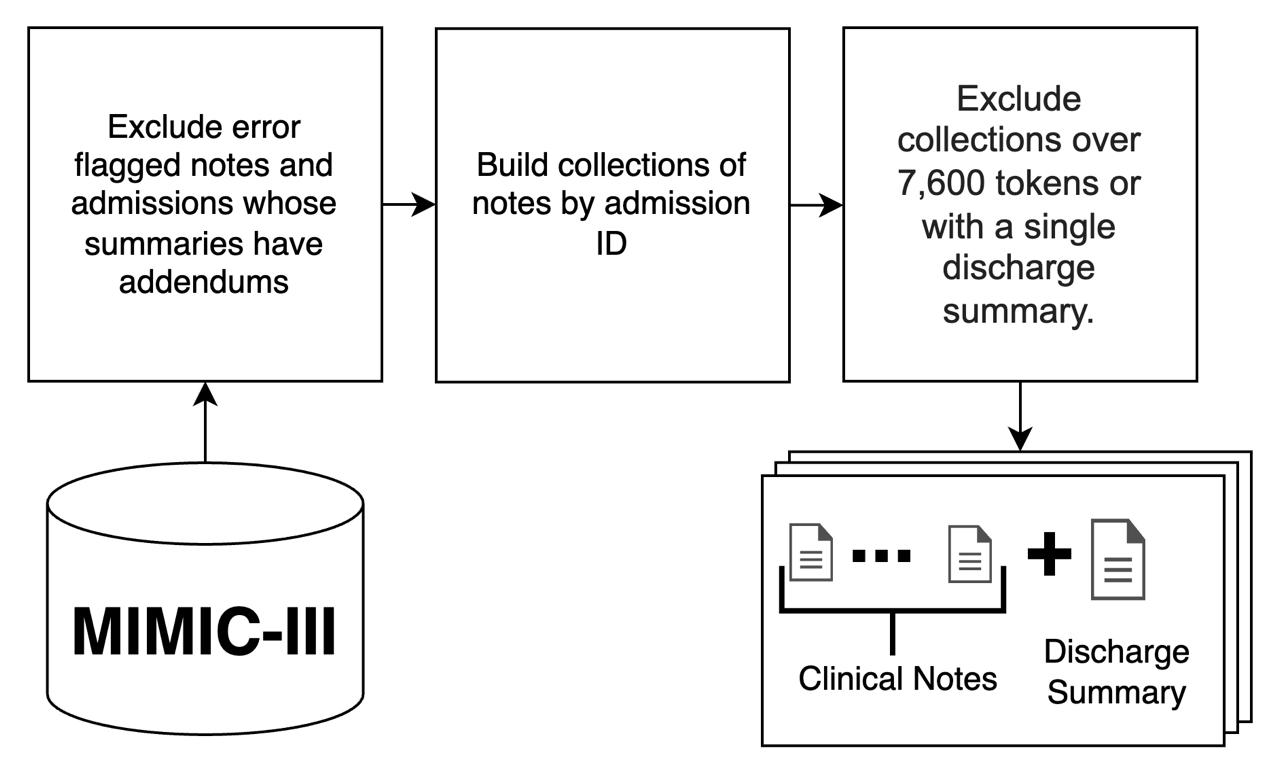
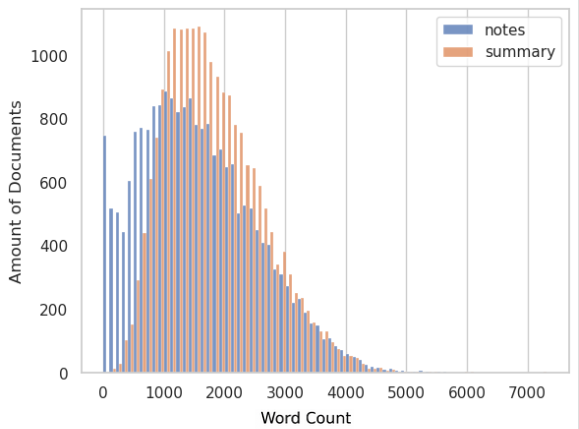
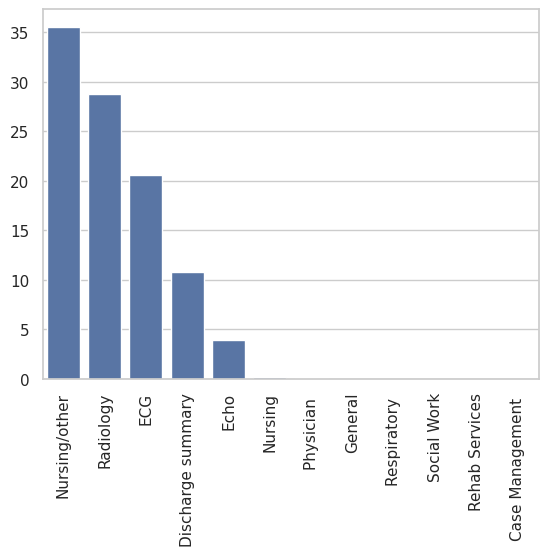
技术框架:整体框架包括数据准备、模型选择与训练、以及评估三个主要阶段。首先,从MIMIC-III数据库中提取出院总结和病程记录作为训练数据。然后,选择五种大型语言模型(Mistral, Llama 2, GPT-3, GPT-4, Gemini 1.5 Pro)进行实验,其中开源模型需要进行微调。最后,使用精确匹配、软重叠和无参考指标对生成的摘要进行评估,并进行人工评估。
关键创新:该研究的关键创新在于探索了多种大型语言模型在自动生成出院总结任务中的应用,并比较了不同模型的性能。特别地,研究发现专有模型如Gemini在生成高质量出院总结方面表现出色,这为未来的研究提供了重要的参考。此外,研究还探讨了开源模型在这一任务中的潜力,并指出了其存在的挑战。
关键设计:研究中使用了one-shot prompting技术来指导LLMs生成出院总结。对于开源模型,采用了微调策略来提升其性能。评估指标包括精确匹配(Exact-Match)、软重叠(Soft-Overlap)以及参考无关指标(Reference-Free Metrics)。人工评估由临床专家进行,以评估生成摘要的临床实用性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,专有模型,特别是采用one-shot prompting的Gemini 1.5 Pro,在自动生成出院总结任务中表现最佳,生成的摘要与黄金标准摘要的相似度最高。开源模型,如微调后的Mistral,虽然有潜力,但在性能上仍有差距,存在幻觉和重复信息的问题。临床专家的评估证实了专有模型生成的摘要具有实际临床价值。
🎯 应用场景
该研究成果可应用于医疗信息系统,辅助医护人员快速生成高质量的出院总结,减少工作负担,提升医疗效率。自动生成的出院总结有助于提高患者信息的标准化和可访问性,促进医疗数据的分析和利用,最终改善患者护理质量。未来,该技术有望扩展到其他医疗文档的自动生成,例如病历、诊断报告等。
📄 摘要(原文)
Discharge Summaries are documents written by medical professionals that detail a patient's visit to a care facility. They contain a wealth of information crucial for patient care, and automating their generation could significantly reduce the effort required from healthcare professionals, minimize errors, and ensure that critical patient information is easily accessible and actionable. In this work, we explore the use of five Large Language Models on this task, from open-source models (Mistral, Llama 2) to proprietary systems (GPT-3, GPT-4, Gemini 1.5 Pro), leveraging MIMIC-III summaries and notes. We evaluate them using exact-match, soft-overlap, and reference-free metrics. Our results show that proprietary models, particularly Gemini with one-shot prompting, outperformed others, producing summaries with the highest similarity to the gold-standard ones. Open-source models, while promising, especially Mistral after fine-tuning, lagged in performance, often struggling with hallucinations and repeated information. Human evaluation by a clinical expert confirmed the practical utility of the summaries generated by proprietary models. Despite the challenges, such as hallucinations and missing information, the findings suggest that LLMs, especially proprietary models, are promising candidates for automatic discharge summary generation as long as data privacy is ensured.