Becoming Experienced Judges: Selective Test-Time Learning for Evaluators
作者: Seungyeon Jwa, Daechul Ahn, Reokyoung Kim, Dongyeop Kang, Jonghyun Choi
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-07
💡 一句话要点
提出选择性测试时学习框架LWE,提升LLM评估器在推理任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM评估器 测试时学习 元学习 自反馈 选择性更新
📋 核心要点
- 现有LLM评估器忽略了案例间的关联,无法积累经验,且对所有案例使用固定提示,缺乏针对性。
- LWE框架通过维护可演进的元提示,生成样本特定的评估指令,并利用自反馈进行优化。
- 选择性LWE仅在自我不一致的案例上更新元提示,显著提升了计算效率,并在实验中超越基线。
📝 摘要(中文)
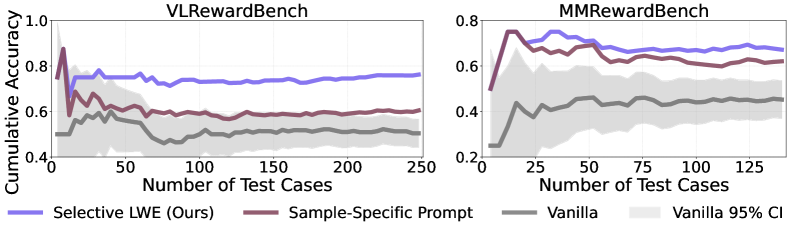
本文提出了一种名为“边评估边学习”(Learning While Evaluating, LWE)的框架,旨在提升大型语言模型(LLM)作为评估器在推理和对齐任务中的自动评估能力。LWE允许评估器在推理时进行序列化改进,无需训练或验证集。该框架维护一个不断演进的元提示,用于生成样本特定的评估指令,并通过自我生成的反馈来完善自身。此外,本文还提出了选择性LWE,仅在自我不一致的情况下更新元提示,从而将计算集中在最关键的地方。在两个成对比较基准测试中,选择性LWE优于强大的基线,实证表明评估器可以通过简单的选择性更新在序列化测试期间得到改进,并从他们难以处理的案例中学习最多。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)作为评估器时,在推理和对齐任务中存在的两个主要问题。一是现有方法通常独立处理每个评估案例,忽略了案例之间的关联性,无法积累评估经验。二是现有方法对所有案例使用相同的固定提示,缺乏针对性,无法根据不同案例的特点进行灵活评估。这些问题限制了LLM评估器的性能和效率。
核心思路:论文的核心思路是让LLM评估器在评估过程中不断学习和改进,类似于人类专家通过经验积累提升判断能力。具体而言,通过维护一个动态演进的元提示(meta-prompt),该元提示能够根据当前评估的样本生成特定的评估指令,并利用评估结果进行自我反馈,从而不断优化元提示本身。
技术框架:LWE框架包含以下主要模块:1) 元提示生成器:根据历史评估经验和当前样本,生成针对性的评估指令。2) 评估器:使用生成的评估指令对样本进行评估,得到评估结果。3) 自反馈机制:根据评估结果,生成反馈信号,用于更新元提示。4) 选择性更新机制:仅在评估结果不一致时更新元提示,以提高效率。整个流程是一个循环迭代的过程,评估器在不断评估的过程中,元提示也在不断优化,从而提升评估器的性能。
关键创新:论文的关键创新在于提出了“边评估边学习”的思想,将LLM评估器从一个静态的工具转变为一个能够动态学习和适应的智能体。此外,选择性更新机制也是一个重要的创新,它能够有效地减少计算量,提高学习效率。与现有方法相比,LWE框架能够更好地利用评估数据,提升评估器的泛化能力和鲁棒性。
关键设计:元提示的设计是LWE框架的关键。元提示需要能够有效地捕捉历史评估经验,并根据当前样本生成合适的评估指令。论文中具体如何设计元提示,以及如何利用自反馈信号更新元提示,这些技术细节在论文中应该有更详细的描述。选择性更新机制的具体实现方式,例如如何判断评估结果是否一致,也是一个重要的设计细节。此外,损失函数的设计,以及其他超参数的设置,都会影响LWE框架的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,选择性LWE在两个成对比较基准测试中均优于强大的基线模型,证明了评估器可以通过简单的选择性更新在序列化测试期间得到改进。具体性能数据和提升幅度需要在论文中查找,但总体而言,选择性LWE展示了在计算效率和评估准确性之间的良好平衡。
🎯 应用场景
该研究成果可广泛应用于各种需要自动评估的场景,例如机器翻译质量评估、文本摘要质量评估、代码生成质量评估等。通过LWE框架,可以显著提升自动评估的准确性和效率,降低人工评估的成本。未来,该技术有望应用于更复杂的评估任务,例如对话系统评估、多模态内容评估等。
📄 摘要(原文)
Automatic evaluation with large language models, commonly known as LLM-as-a-judge, is now standard across reasoning and alignment tasks. Despite evaluating many samples in deployment, these evaluators typically (i) treat each case independently, missing the opportunity to accumulate experience, and (ii) rely on a single fixed prompt for all cases, neglecting the need for sample-specific evaluation criteria. We introduce Learning While Evaluating (LWE), a framework that allows evaluators to improve sequentially at inference time without requiring training or validation sets. LWE maintains an evolving meta-prompt that (i) produces sample-specific evaluation instructions and (ii) refines itself through self-generated feedback. Furthermore, we propose Selective LWE, which updates the meta-prompt only on self-inconsistent cases, focusing computation where it matters most. This selective approach retains the benefits of sequential learning while being far more cost-effective. Across two pairwise comparison benchmarks, Selective LWE outperforms strong baselines, empirically demonstrating that evaluators can improve during sequential testing with a simple selective update, learning most from the cases they struggle with.