Think-While-Generating: On-the-Fly Reasoning for Personalized Long-Form Generation
作者: Chengbing Wang, Yang Zhang, Wenjie Wang, Xiaoyan Zhao, Fuli Feng, Xiangnan He, Tat-Seng Chua
分类: cs.CL
发布日期: 2025-12-07
💡 一句话要点
提出FlyThinker框架,用于个性化长文本生成中的动态推理与高效训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化生成 长文本生成 动态推理 语言模型 边生成边思考
📋 核心要点
- 现有长文本生成方法难以捕捉个体用户的隐含偏好,导致个性化效果不佳。
- FlyThinker框架通过并行运行推理模型和生成模型,实现动态的token级别推理。
- 实验表明,FlyThinker在保证效率的同时,显著提升了个性化长文本生成的质量。
📝 摘要(中文)
偏好对齐已使大型语言模型(LLMs)更好地反映人类期望,但当前方法主要针对群体层面的偏好进行优化,忽略了个体用户。个性化至关重要,但早期方法(如提示定制或微调)难以推理隐含偏好,限制了实际效果。最近的“先思考后生成”方法通过在响应生成前进行推理来解决这个问题。然而,它们在长文本生成中面临挑战:其静态的一次性推理必须捕获完整响应生成的所有相关信息,导致学习困难并限制了对演变内容的适应性。为了解决这个问题,我们提出了FlyThinker,一个高效的“边生成边思考”框架,用于个性化长文本生成。FlyThinker采用一个单独的推理模型,并行生成潜在的token级别推理,并将其融合到生成模型中,以动态地指导响应生成。这种设计使推理和生成能够并发运行,确保了推理效率。此外,推理模型被设计为仅依赖于先前的响应,而不是其自身的先前输出,这保留了跨不同位置的训练并行性——允许像标准LLM训练一样,在单个前向传递中生成训练数据的所有推理token,从而确保训练效率。在真实基准上的大量实验表明,FlyThinker在保持训练和推理效率的同时,实现了更好的个性化生成。
🔬 方法详解
问题定义:论文旨在解决个性化长文本生成问题。现有方法,如prompt定制或fine-tuning,难以有效推理用户的隐含偏好。而“先思考后生成”的方法在长文本生成中面临挑战,因为它们需要一次性推理出所有相关信息,这使得学习困难,并且难以适应内容的变化。
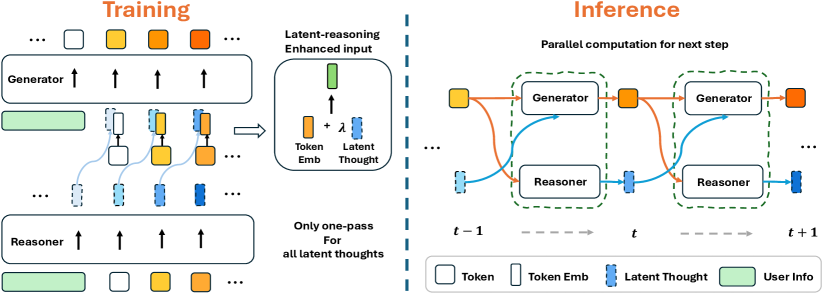
核心思路:论文的核心思路是“边生成边思考”(think-while-generating)。不同于一次性推理,FlyThinker在生成文本的同时进行推理,从而能够动态地调整生成过程,更好地捕捉用户的个性化偏好。
技术框架:FlyThinker包含一个生成模型和一个独立的推理模型。推理模型并行地生成token级别的推理信息,这些信息随后被融合到生成模型中,以指导文本生成。推理模型的设计使其仅依赖于之前的生成内容,而非自身的输出,从而保证了训练的并行性。
关键创新:FlyThinker的关键创新在于其“边生成边思考”的框架,以及推理模型与生成模型的并行运行机制。这种设计使得模型能够动态地适应内容的变化,并高效地进行训练和推理。与传统的“先思考后生成”方法相比,FlyThinker更加灵活和高效。
关键设计:推理模型被设计为仅依赖于之前的响应,而非自身的先前输出。这种设计保留了跨不同位置的训练并行性,允许像标准LLM训练一样,在单个前向传递中生成训练数据的所有推理token,从而确保训练效率。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述(具体数值未知)。
🖼️ 关键图片


📊 实验亮点
论文在真实数据集上进行了大量实验,证明了FlyThinker的有效性。实验结果表明,FlyThinker在保持训练和推理效率的同时,显著提升了个性化长文本生成的质量。具体的性能提升幅度以及对比的基线模型在论文中进行了详细描述(具体数值未知)。
🎯 应用场景
FlyThinker框架可应用于各种需要个性化长文本生成的场景,例如个性化新闻推荐、定制化故事创作、以及智能客服中的个性化回复等。该研究有助于提升用户体验,并为构建更加智能和个性化的AI系统奠定基础。未来,该方法可以扩展到其他模态,例如个性化音乐生成或视频内容创作。
📄 摘要(原文)
Preference alignment has enabled large language models (LLMs) to better reflect human expectations, but current methods mostly optimize for population-level preferences, overlooking individual users. Personalization is essential, yet early approaches-such as prompt customization or fine-tuning-struggle to reason over implicit preferences, limiting real-world effectiveness. Recent "think-then-generate" methods address this by reasoning before response generation. However, they face challenges in long-form generation: their static one-shot reasoning must capture all relevant information for the full response generation, making learning difficult and limiting adaptability to evolving content. To address this issue, we propose FlyThinker, an efficient "think-while-generating" framework for personalized long-form generation. FlyThinker employs a separate reasoning model that generates latent token-level reasoning in parallel, which is fused into the generation model to dynamically guide response generation. This design enables reasoning and generation to run concurrently, ensuring inference efficiency. In addition, the reasoning model is designed to depend only on previous responses rather than its own prior outputs, which preserves training parallelism across different positions-allowing all reasoning tokens for training data to be produced in a single forward pass like standard LLM training, ensuring training efficiency. Extensive experiments on real-world benchmarks demonstrate that FlyThinker achieves better personalized generation while keeping training and inference efficiency.