Nanbeige4-3B Technical Report: Exploring the Frontier of Small Language Models
作者: Chen Yang, Guangyue Peng, Jiaying Zhu, Ran Le, Ruixiang Feng, Tao Zhang, Wei Ruan, Xiaoqi Liu, Xiaoxue Cheng, Xiyun Xu, Yang Song, Yanzipeng Gao, Yiming Jia, Yun Xing, Yuntao Wen, Zekai Wang, Zhenwei An, Zhicong Sun, Zongchao Chen
分类: cs.CL
发布日期: 2025-12-06
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
Nanbeige4-3B:探索小规模语言模型性能极限,媲美更大模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小规模语言模型 预训练 指令微调 双重偏好蒸馏 强化学习 模型优化 FG-WSD调度器
📋 核心要点
- 现有小规模语言模型在性能上存在瓶颈,难以达到与大规模模型相当的水平,限制了其应用范围。
- Nanbeige4-3B通过精细的预训练调度、高质量的指令微调数据生成以及双重偏好蒸馏等方法,显著提升了小规模模型的性能。
- 实验结果表明,Nanbeige4-3B在多个基准测试中超越了同等规模的模型,甚至可以与更大规模的模型竞争。
📝 摘要(中文)
本文介绍了Nanbeige4-3B,一系列小规模但高性能的语言模型。该模型在23T高质量tokens上进行预训练,并在超过3000万条多样化指令上进行微调,从而扩展了小规模语言模型的缩放定律边界。在预训练阶段,我们设计了一种细粒度Warmup-Stable-Decay (FG-WSD)训练调度器,该调度器逐步细化各个阶段的数据混合,以提高模型性能。在后训练阶段,为了提高SFT数据的质量,我们设计了一种联合机制,该机制集成了审慎生成细化和思维链重建,从而在复杂任务上获得了显著的收益。在SFT之后,我们采用我们旗舰推理模型,通过我们提出的双重偏好蒸馏(DPD)方法来提炼Nanbeige4-3B,从而进一步提高性能。最后,应用了一个多阶段强化学习阶段,利用可验证的奖励和偏好建模来加强推理和人类对齐能力。广泛的评估表明,Nanbeige4-3B不仅显著优于同等参数规模的模型,而且在各种基准测试中也与更大的模型相媲美。模型检查点可在https://huggingface.co/Nanbeige获得。
🔬 方法详解
问题定义:现有小规模语言模型的性能受限于数据质量、训练策略和模型优化方法,难以充分发挥其潜力。如何突破小规模模型的性能瓶颈,使其在资源受限的场景下也能实现高性能,是本文要解决的核心问题。
核心思路:本文的核心思路是通过精细化的预训练数据管理、高质量的指令微调数据生成以及有效的模型蒸馏方法,充分挖掘小规模模型的潜力。通过这些方法,模型能够学习到更丰富的知识和更强的推理能力,从而在各种任务中表现出色。
技术框架:Nanbeige4-3B的训练流程主要包括三个阶段:预训练、监督微调(SFT)和强化学习(RL)。预训练阶段使用FG-WSD调度器优化数据混合;SFT阶段采用联合机制生成高质量的指令数据;RL阶段使用可验证奖励和偏好建模进行人类对齐。
关键创新:本文的关键创新在于以下几个方面:1) 提出了FG-WSD训练调度器,能够更有效地利用预训练数据;2) 设计了联合机制,通过审慎生成细化和思维链重建,显著提升了SFT数据的质量;3) 提出了双重偏好蒸馏(DPD)方法,利用大型推理模型指导小模型的训练,进一步提升了性能。
关键设计:FG-WSD训练调度器通过细粒度地调整不同阶段的数据混合比例,实现更稳定的训练过程和更高的模型性能。联合机制通过迭代地生成和修正指令数据,确保数据的质量和多样性。DPD方法通过比较不同模型的偏好,引导小模型学习大型模型的推理能力。具体参数设置和损失函数细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片
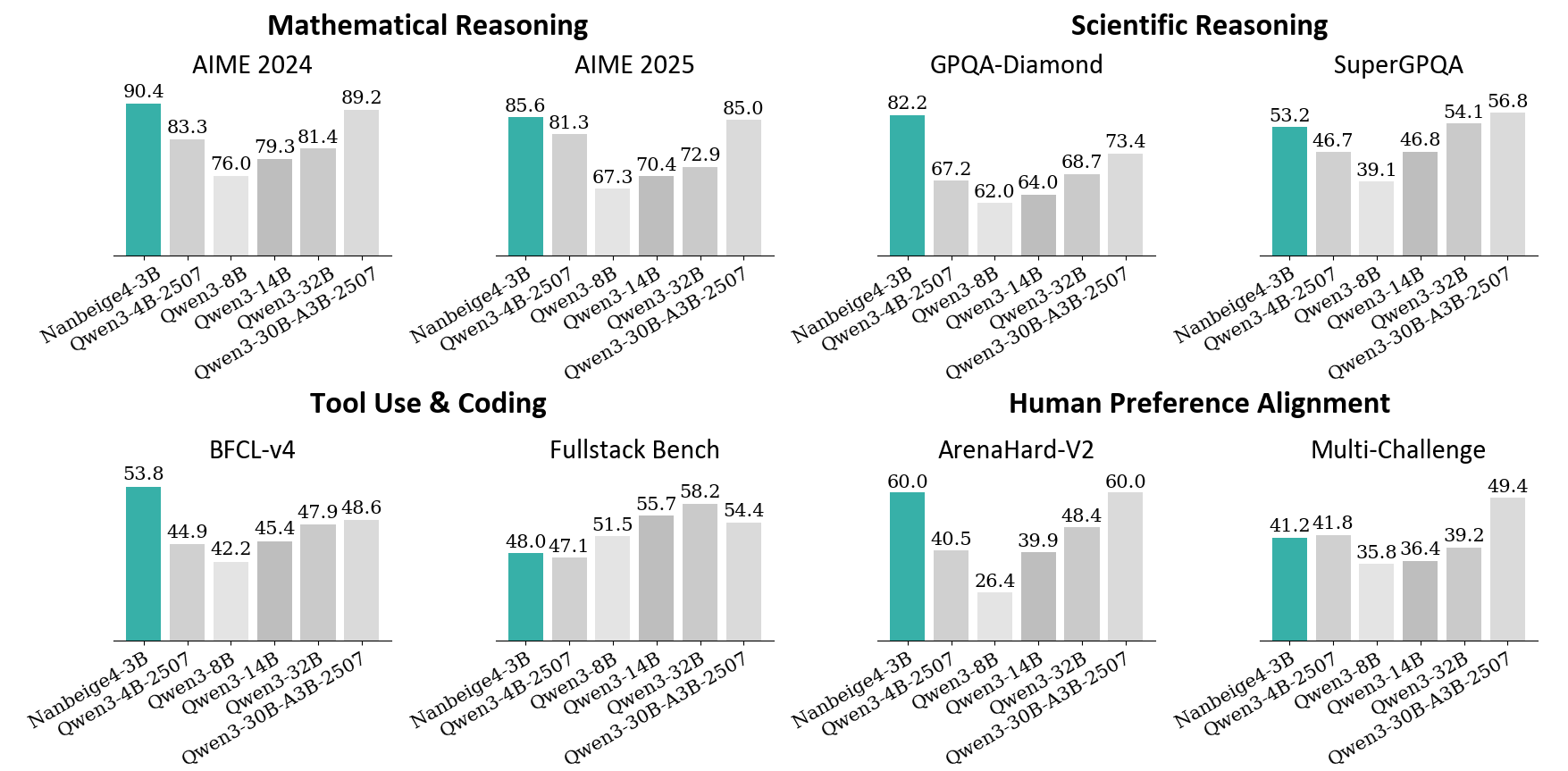

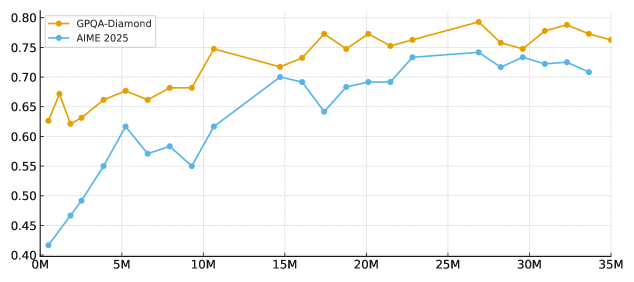
📊 实验亮点
Nanbeige4-3B在多个基准测试中表现出色,显著优于同等参数规模的模型,并在某些任务上与更大规模的模型相媲美。具体性能数据未在摘要中给出,属于未知信息。但整体结果表明,该模型在小规模语言模型领域取得了重要突破。
🎯 应用场景
Nanbeige4-3B具有广泛的应用前景,包括移动设备上的本地部署、边缘计算环境中的推理加速、以及资源受限场景下的智能助手等。其小巧的体积和强大的性能使其成为各种实际应用的理想选择,有助于推动人工智能技术的普及。
📄 摘要(原文)
We present Nanbeige4-3B, a family of small-scale but high-performing language models. Pretrained on 23T high-quality tokens and finetuned on over 30 million diverse instructions, we extend the boundary of the scaling law for small language models. In pre-training, we design a Fine-Grained Warmup-Stable-Decay (FG-WSD) training scheduler, which progressively refines data mixtures across stages to boost model performance. In post-training, to improve the quality of the SFT data, we design a joint mechanism that integrates deliberative generation refinement and chain-of-thought reconstruction, yielding substantial gains on complex tasks. Following SFT, we employ our flagship reasoning model to distill Nanbeige4-3B through our proposed Dual Preference Distillation (DPD) method, which leads to further performance gains. Finally, a multi-stage reinforcement learning phase was applied, leveraging verifiable rewards and preference modeling to strengthen abilities on both reasoning and human alignment. Extensive evaluations show that Nanbeige4-3B not only significantly outperforms models of comparable parameter scale but also rivals much larger models across a wide range of benchmarks. The model checkpoints are available at https://huggingface.co/Nanbeige.