Convergence of Outputs When Two Large Language Models Interact in a Multi-Agentic Setup
作者: Aniruddha Maiti, Satya Nimmagadda, Kartha Veerya Jammuladinne, Niladri Sengupta, Ananya Jana
分类: cs.CL, cs.AI
发布日期: 2025-12-06
备注: accepted to LLM 2025
💡 一句话要点
研究多Agent LLM交互中的输出收敛现象与重复模式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多Agent系统 大型语言模型 对话交互 输出收敛 重复模式
📋 核心要点
- 现有研究缺乏对多Agent LLM长期交互中涌现行为的深入理解,尤其是在无外部输入的情况下。
- 通过构建多Agent对话环境,观察LLM在长期交互中出现的重复和收敛现象,揭示其内在机制。
- 实验表明,即使是大型、独立训练的LLM,在长期交互中也容易陷入重复,产生相似的输出。
📝 摘要(中文)
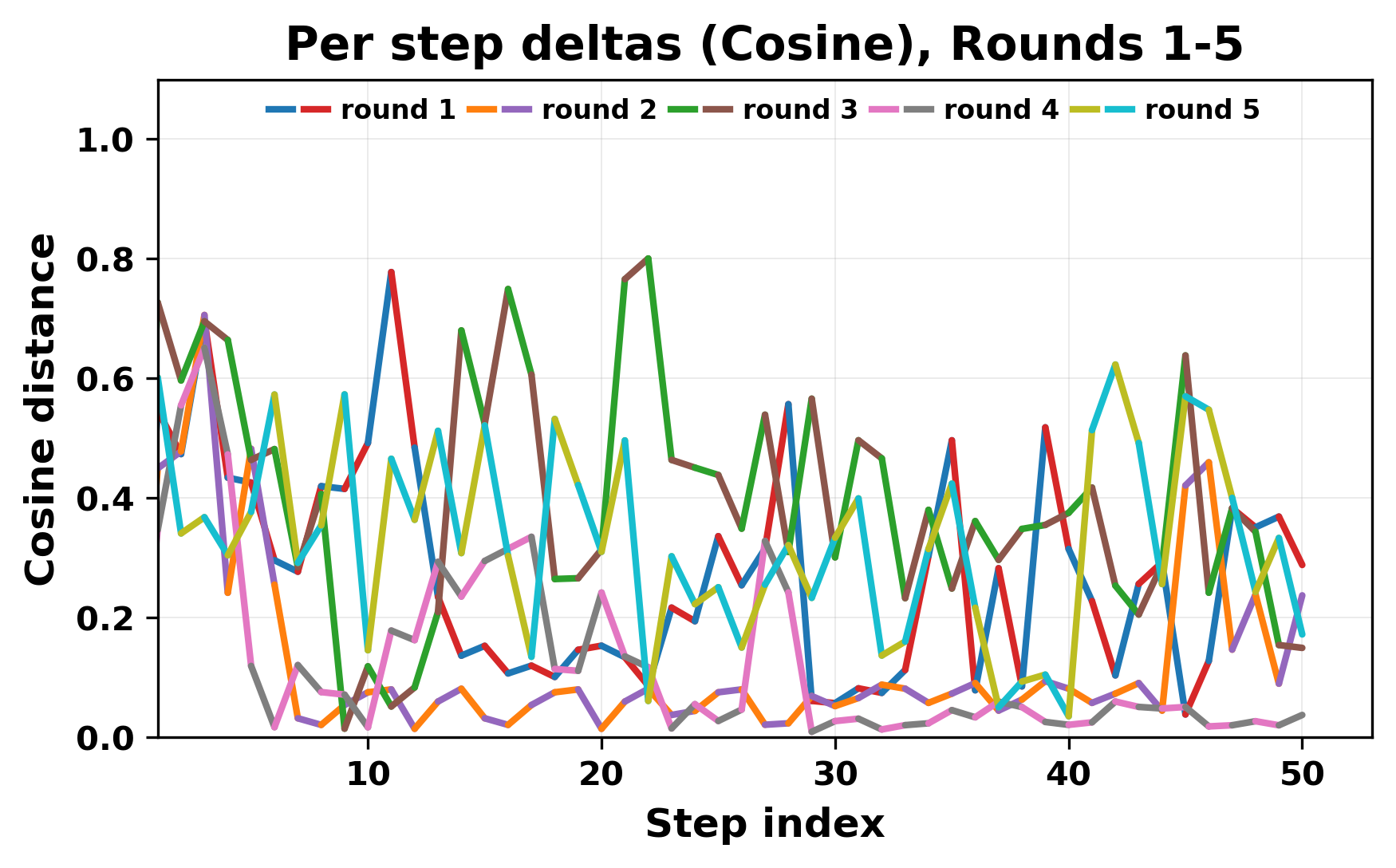
本文研究了两个大型语言模型在多Agent环境中,通过多轮对话交互时出现的现象。实验设置从一个简短的种子语句开始,然后每个模型读取对方的输出并生成回复,持续固定轮数。实验使用了Mistral Nemo Base 2407和Llama 2 13B hf模型。观察发现,大多数对话开始时连贯,但随后陷入重复。在许多实验中,一个短语出现并在多轮对话中重复。一旦重复开始,两个模型倾向于产生相似的输出,而不是引入新的对话方向。这种行为导致一个循环,其中相同或相似的文本被重复产生。我们将这种行为描述为一种收敛形式。即使模型很大,经过独立训练,并且没有给出任何提示指令,也会发生这种情况。为了研究这种行为,我们应用词汇和基于嵌入的指标来衡量对话与初始种子的偏离程度,以及随着对话的进行,两个模型的输出变得多么相似。
🔬 方法详解
问题定义:论文旨在研究两个大型语言模型在多Agent环境中,没有任何外部输入的情况下,进行多轮对话时,其输出会发生什么变化。现有方法的痛点在于缺乏对这种长期交互行为的理解,以及对模型输出收敛和重复模式的量化分析。
核心思路:论文的核心思路是通过构建一个简单的多Agent对话环境,让两个LLM互相生成回复,持续多轮,然后通过词汇和嵌入相似度等指标来量化分析对话内容的变化,从而揭示模型输出的收敛和重复现象。这种设计旨在模拟LLM在没有人类干预的情况下,自主进行对话的场景。
技术框架:整体框架非常简单,包含以下几个步骤:1) 使用一个简短的种子语句初始化对话;2) 两个LLM(Mistral Nemo Base 2407和Llama 2 13B hf)交替生成回复,每一轮一个模型读取对方的输出并生成自己的回复;3) 重复步骤2,直到达到预设的轮数;4) 使用词汇和基于嵌入的指标来分析对话内容,包括对话与初始种子的偏离程度,以及两个模型输出的相似度。
关键创新:该研究的创新点在于关注了多Agent LLM在长期交互中的涌现行为,特别是输出的收敛和重复现象。与以往研究不同,该研究没有引入任何外部输入或任务目标,而是让模型自主进行对话,从而揭示了模型内在的交互模式。此外,该研究还使用了量化的指标来分析对话内容,使得研究结果更加客观和可信。
关键设计:论文的关键设计在于选择合适的LLM(Mistral Nemo Base 2407和Llama 2 13B hf)作为Agent,并设计了一个简单的对话环境。没有使用任何复杂的提示工程或微调技术,而是直接让模型进行对话,从而更好地观察模型的内在行为。此外,论文还使用了词汇相似度(例如n-gram overlap)和嵌入相似度(例如cosine similarity)等指标来量化分析对话内容,这些指标的选择对于揭示输出的收敛和重复现象至关重要。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使是大型、独立训练的LLM,在多Agent交互中也容易出现输出收敛和重复现象。通过词汇和嵌入相似度分析,量化了对话内容与初始种子的偏离程度,以及两个模型输出的相似度。观察到在没有外部干预的情况下,模型倾向于产生相似的输出,最终陷入重复循环。
🎯 应用场景
该研究结果可应用于改进对话系统的设计,避免模型陷入重复循环,提高对话的流畅性和多样性。此外,该研究也为理解多Agent系统中LLM的交互行为提供了新的视角,有助于开发更可靠、更智能的AI系统。未来可应用于智能客服、虚拟助手等领域。
📄 摘要(原文)
In this work, we report what happens when two large language models respond to each other for many turns without any outside input in a multi-agent setup. The setup begins with a short seed sentence. After that, each model reads the other's output and generates a response. This continues for a fixed number of steps. We used Mistral Nemo Base 2407 and Llama 2 13B hf. We observed that most conversations start coherently but later fall into repetition. In many runs, a short phrase appears and repeats across turns. Once repetition begins, both models tend to produce similar output rather than introducing a new direction in the conversation. This leads to a loop where the same or similar text is produced repeatedly. We describe this behavior as a form of convergence. It occurs even though the models are large, trained separately, and not given any prompt instructions. To study this behavior, we apply lexical and embedding-based metrics to measure how far the conversation drifts from the initial seed and how similar the outputs of the two models becomes as the conversation progresses.