TeleTables: A Benchmark for Large Language Models in Telecom Table Interpretation
作者: Anas Ezzakri, Nicola Piovesan, Mohamed Sana, Antonio De Domenico, Fadhel Ayed, Haozhe Zhang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-05
💡 一句话要点
TeleTables:用于评估大语言模型在电信表格理解能力上的基准数据集
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电信表格理解 大语言模型 基准数据集 3GPP标准 多模态学习
📋 核心要点
- 现有大语言模型在电信标准理解方面表现不佳,尤其是在包含大量表格的3GPP规范中,缺乏对表格的有效理解。
- TeleTables通过多阶段数据生成流程,从3GPP标准中提取表格,并利用多模态LLM生成和验证问题,构建高质量的表格理解数据集。
- 实验表明,小型LLM在电信知识和表格理解方面存在困难,而大型LLM展现出更强的推理能力,突出了领域微调的必要性。
📝 摘要(中文)
本文提出了TeleTables,一个用于评估大语言模型(LLMs)在电信表格理解能力上的基准数据集。电信行业越来越多地使用LLMs来支持工程任务、加速故障排除和辅助解释复杂的技术文档。然而,现有研究表明LLMs在电信标准(特别是3GPP规范)上的表现不佳。一个关键原因是这些标准密集地使用表格来呈现重要信息,而LLMs对这些表格的知识和解释能力在很大程度上未被检验。TeleTables通过一个新颖的多阶段数据生成流程构建,该流程从3GPP标准中提取表格,并使用多模态和推理导向的LLMs来生成和验证问题。该数据集包含500个经过人工验证的问答对,每个问答对都与多种格式的相应表格相关联。评估结果表明,较小的模型(小于100亿参数)在回忆3GPP知识和解释表格方面都存在困难,表明它们在预训练中对电信标准的接触有限,并且缺乏导航复杂技术材料的归纳偏置。另一方面,较大的模型在表格解释方面表现出更强的推理能力。总体而言,TeleTables强调了需要进行领域专业化的微调,以可靠地解释和推理电信标准。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在电信标准表格理解方面表现不佳的问题。现有方法缺乏针对电信领域表格的专门训练和评估,导致LLMs难以有效提取和利用表格中的信息。现有数据集和基准测试没有充分覆盖电信领域的表格数据,无法准确评估LLMs在该领域的性能。
核心思路:论文的核心思路是构建一个专门针对电信表格理解的基准数据集TeleTables。通过该数据集,可以系统地评估LLMs在理解和推理电信标准表格方面的能力,并促进领域特定模型的开发和优化。该数据集的构建过程侧重于从3GPP标准中提取真实世界的表格数据,并生成高质量的问答对,以确保评估的准确性和可靠性。
技术框架:TeleTables的构建流程包含以下主要阶段: 1. 表格提取:从3GPP标准文档中提取表格数据。 2. 问题生成:使用多模态和推理导向的LLMs,基于提取的表格生成问题。 3. 答案生成:使用LLMs生成与问题相对应的答案。 4. 人工验证:人工审核和验证生成的问答对,确保质量和准确性。 5. 格式转换:将表格数据转换为多种格式,以适应不同的模型输入要求。
关键创新:TeleTables的关键创新在于其数据生成流程,该流程结合了LLMs的自动生成能力和人工验证的质量控制,从而构建了一个高质量、领域特定的表格理解数据集。此外,TeleTables还提供了多种表格格式,以支持不同模型的输入需求。与现有数据集相比,TeleTables更侧重于电信领域的表格数据,能够更准确地评估LLMs在该领域的性能。
关键设计:在问题生成阶段,论文使用了多模态LLMs,允许模型同时考虑表格的结构和内容。在人工验证阶段,论文采用了严格的审核标准,确保问答对的准确性和相关性。此外,论文还考虑了表格数据的多样性,包括不同类型的表格结构和内容,以提高数据集的泛化能力。具体参数设置和损失函数的使用取决于所使用的LLM模型,论文未详细说明。
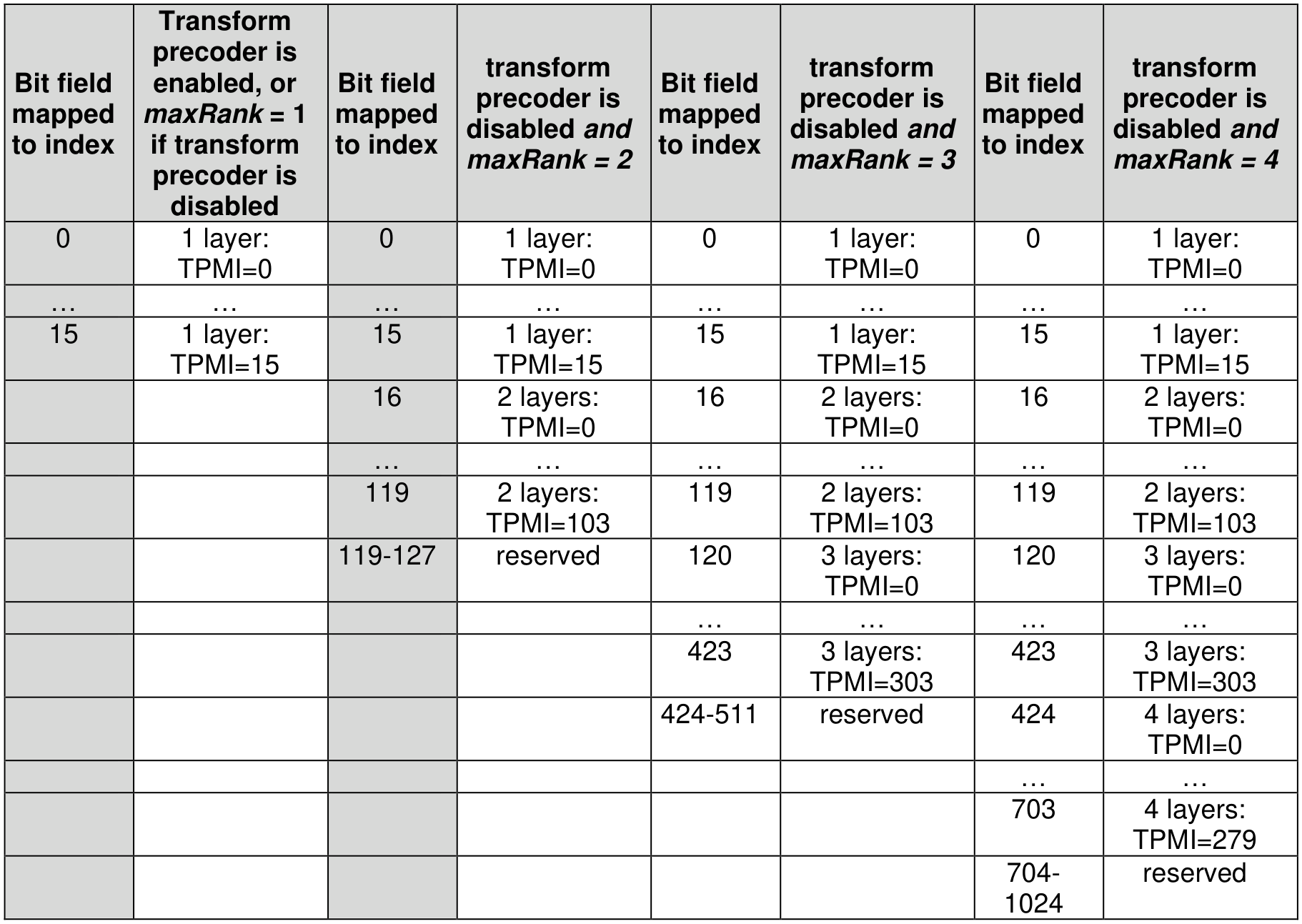
🖼️ 关键图片

📊 实验亮点
TeleTables数据集的评估结果表明,小型LLMs(<10B参数)在电信表格理解方面表现不佳,而大型LLMs展现出更强的推理能力。这一结果强调了领域专业化微调对于提高LLMs在特定领域(如电信)的性能至关重要。该数据集的发布将促进相关研究,并推动电信领域LLM应用的进一步发展。
🎯 应用场景
TeleTables的研究成果可应用于电信行业的多个领域,例如自动化文档处理、智能故障排除、工程知识库构建等。通过提高LLMs对电信表格的理解能力,可以显著提升工作效率,降低运营成本,并促进电信技术的创新发展。未来,该数据集可以用于开发更强大的领域特定LLMs,为电信行业提供更智能化的解决方案。
📄 摘要(原文)
Language Models (LLMs) are increasingly explored in the telecom industry to support engineering tasks, accelerate troubleshooting, and assist in interpreting complex technical documents. However, recent studies show that LLMs perform poorly on telecom standards, particularly 3GPP specifications. We argue that a key reason is that these standards densely include tables to present essential information, yet the LLM knowledge and interpretation ability of such tables remains largely unexamined. To address this gap, we introduce TeleTables, a benchmark designed to evaluate both the implicit knowledge LLMs have about tables in technical specifications and their explicit ability to interpret them. TeleTables is built through a novel multi-stage data generation pipeline that extracts tables from 3GPP standards and uses multimodal and reasoning-oriented LLMs to generate and validate questions. The resulting dataset, which is publicly available, comprises 500 human-verified question-answer pairs, each associated with the corresponding table in multiple formats. Our evaluation shows that, smaller models (under 10B parameters) struggle both to recall 3GPP knowledge and to interpret tables, indicating the limited exposure to telecom standards in their pretraining and the insufficient inductive biases for navigating complex technical material. Larger models, on the other hand, show stronger reasoning on table interpretation. Overall, TeleTables highlights the need for domain-specialized fine-tuning to reliably interpret and reason over telecom standards.