Attribute-Aware Controlled Product Generation with LLMs for E-commerce
作者: Virginia Negri, Víctor Martínez Gómez, Sergio A. Balanya, Subburam Rajaram
分类: cs.CL, cs.AI
发布日期: 2025-12-05
备注: AAAI'26 Workshop on Shaping Responsible Synthetic Data in the Era of Foundation Models (RSD)
💡 一句话要点
提出一种基于LLM的属性感知控制产品生成框架,用于电商数据增强。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电商 数据增强 大型语言模型 属性感知 合成数据生成 产品信息提取 可控生成
📋 核心要点
- 电商领域高质量标注数据稀缺,限制了产品信息提取模型的性能提升。
- 利用大型语言模型,通过属性感知的提示和可控修改策略,生成高质量的合成数据。
- 实验表明,合成数据在产品信息提取任务上与真实数据性能相当,混合使用效果更佳。
📝 摘要(中文)
本文提出了一种系统的电商产品数据生成方法,利用大型语言模型(LLM)和可控修改框架,包含属性保持修改、受控负例生成和系统性属性移除三种策略。通过属性感知的提示,在保证产品一致性的同时,强制执行商店约束。对2000个合成产品的评估显示,99.6%被认为是自然的,96.5%包含有效的属性值,超过90%表现出一致的属性使用。在MAVE数据集上,合成数据达到60.5%的准确率,与真实训练数据(60.8%)相当,远超零样本基线(13.4%)。合成数据与真实数据的混合配置进一步提升性能,达到68.8%的准确率。该框架为电商数据集增强提供了一种实用的解决方案,尤其适用于低资源场景。
🔬 方法详解
问题定义:电商产品信息提取依赖于高质量的标注数据集,但获取成本高昂。现有方法难以生成既符合电商规则、又具有足够多样性的合成数据,限制了模型的泛化能力。
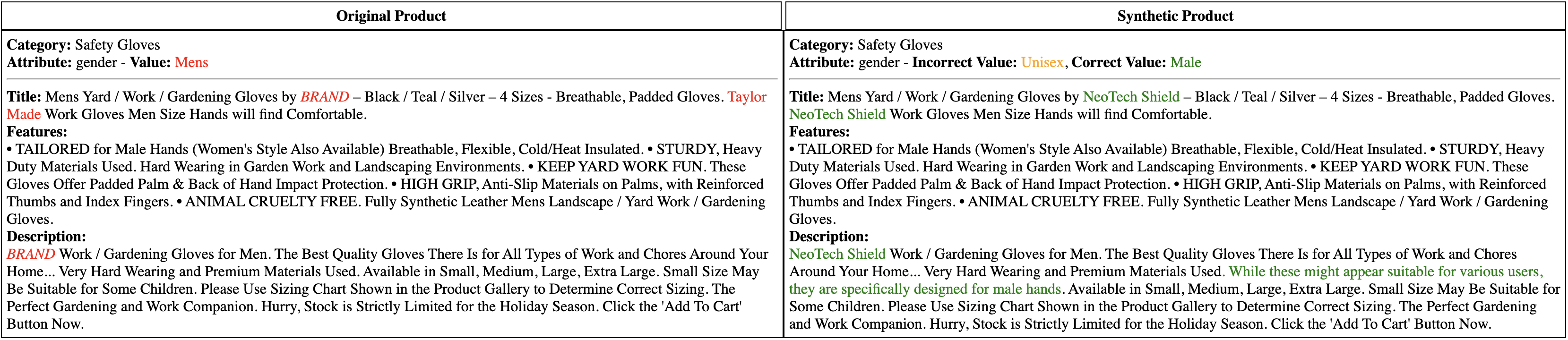
核心思路:利用大型语言模型强大的生成能力,结合属性感知的提示工程,控制生成过程,确保合成数据的质量和多样性。通过可控修改框架,实现对属性的精确控制,生成不同类型的合成数据,包括正例、负例和属性缺失的样本。
技术框架:该框架包含三个主要阶段:1) 属性感知提示:设计包含属性信息的提示,引导LLM生成符合特定属性约束的产品描述。2) 可控修改:实施三种修改策略:属性保持修改(保持核心属性不变)、受控负例生成(修改关键属性生成负例)、系统性属性移除(模拟属性缺失场景)。3) 数据评估:通过人工评估和模型性能评估,验证合成数据的质量和有效性。
关键创新:该方法的核心创新在于将大型语言模型的生成能力与属性感知的控制机制相结合,实现了对电商产品数据的精确生成和修改。与传统的数据增强方法相比,该方法能够生成更具多样性和真实性的合成数据,有效提升模型的泛化能力。
关键设计:在属性感知提示方面,使用了详细的属性描述和约束条件,以引导LLM生成符合要求的文本。在可控修改方面,设计了三种不同的修改策略,以生成不同类型的合成数据。在数据评估方面,采用了人工评估和模型性能评估相结合的方式,全面评估合成数据的质量和有效性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用合成数据训练的模型在MAVE数据集上达到了60.5%的准确率,与使用真实数据训练的模型(60.8%)性能相当,远高于零样本基线(13.4%)。将合成数据与真实数据混合训练,进一步将准确率提升至68.8%,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于电商领域的数据增强,解决标注数据稀缺的问题,提升产品信息提取、属性识别、产品分类等任务的性能。此外,该方法还可用于生成对抗样本,提升模型的鲁棒性,或用于模拟用户行为,进行推荐系统优化。
📄 摘要(原文)
Product information extraction is crucial for e-commerce services, but obtaining high-quality labeled datasets remains challenging. We present a systematic approach for generating synthetic e-commerce product data using Large Language Models (LLMs), introducing a controlled modification framework with three strategies: attribute-preserving modification, controlled negative example generation, and systematic attribute removal. Using a state-of-the-art LLM with attribute-aware prompts, we enforce store constraints while maintaining product coherence. Human evaluation of 2000 synthetic products demonstrates high effectiveness, with 99.6% rated as natural, 96.5% containing valid attribute values, and over 90% showing consistent attribute usage. On the public MAVE dataset, our synthetic data achieves 60.5% accuracy, performing on par with real training data (60.8%) and significantly improving upon the 13.4% zero-shot baseline. Hybrid configurations combining synthetic and real data further improve performance, reaching 68.8% accuracy. Our framework provides a practical solution for augmenting e-commerce datasets, particularly valuable for low-resource scenarios.