M4-RAG: A Massive-Scale Multilingual Multi-Cultural Multimodal RAG
作者: David Anugraha, Patrick Amadeus Irawan, Anshul Singh, En-Shiun Annie Lee, Genta Indra Winata
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-12-05
备注: Preprint
💡 一句话要点
提出M4-RAG,一个大规模多语言多文化多模态RAG基准,用于评估跨语言和模态的检索增强VQA。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言 多模态 检索增强生成 视觉问答 文化多样性
📋 核心要点
- 现有视觉语言模型受限于静态训练数据,缺乏对最新、多语言和文化信息的有效利用。
- M4-RAG通过构建大规模多语言多文化多模态基准,促进检索增强VQA在跨语言和模态场景下的研究。
- 实验表明,RAG对小型VLM有益,但对大型模型效果不佳,揭示了模型大小与检索有效性之间的不匹配。
📝 摘要(中文)
视觉语言模型(VLMs)在视觉问答(VQA)方面取得了显著的性能,但仍然受到静态训练数据的限制。检索增强生成(RAG)通过提供对最新、具有文化背景和多语言信息的访问来缓解这一限制;然而,多语言多模态RAG在很大程度上仍未被探索。我们引入M4-RAG,一个大规模基准,涵盖42种语言和56种区域方言和语域,包含超过80,000个具有文化多样性的图像-问题对,用于评估跨语言和模态的检索增强VQA。为了平衡真实性和可重复性,我们构建了一个受控的检索环境,其中包含数百万个与查询领域相关的、经过精心策划的多语言文档,在确保一致实验的同时,近似模拟真实世界的检索条件。我们的系统评估表明,虽然RAG始终有益于较小的VLM,但它无法扩展到更大的模型,甚至常常会降低它们的性能,这暴露了模型大小与当前检索有效性之间的严重不匹配。M4-RAG为推进下一代RAG系统奠定了基础,这些系统能够跨语言、模态和文化背景无缝地进行推理。
🔬 方法详解
问题定义:论文旨在解决多语言多文化场景下,视觉问答模型缺乏有效检索增强的问题。现有方法难以处理大规模、多语言、文化背景差异大的信息检索,导致VQA性能受限。特别是大型VLM,RAG反而会降低性能。
核心思路:论文的核心思路是构建一个大规模、多语言、多文化的基准数据集M4-RAG,并在此基础上评估现有RAG方法在VQA任务中的表现。通过该基准,可以系统地研究RAG方法在不同语言、文化和模型规模下的有效性,从而促进更有效的多语言多模态RAG系统的发展。
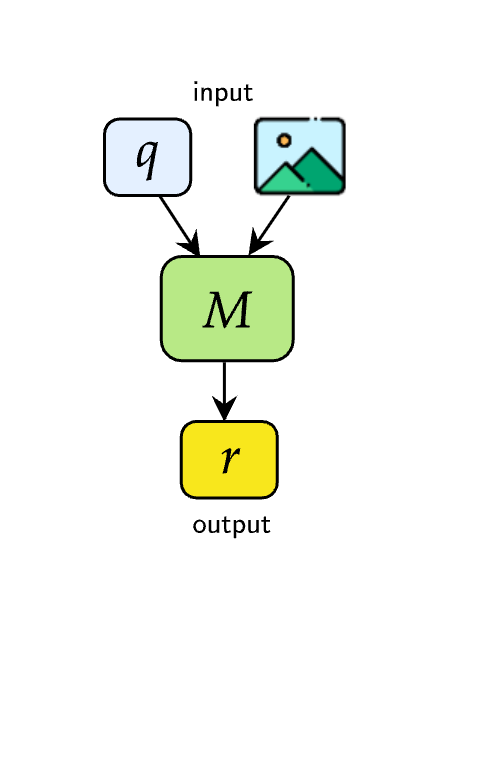
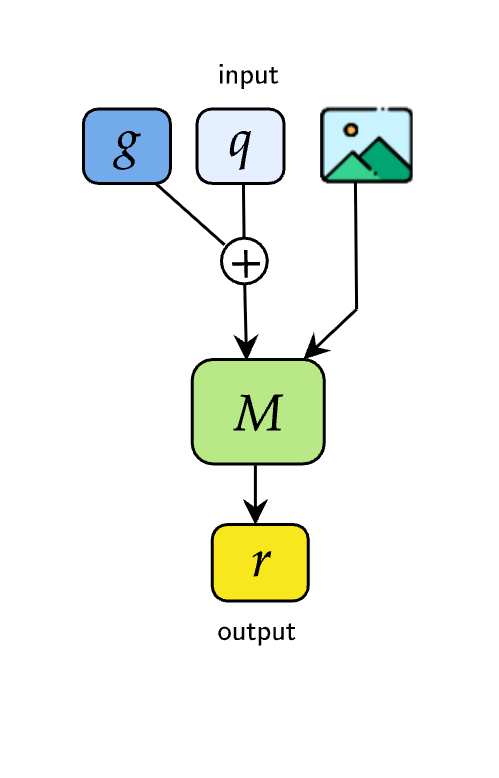
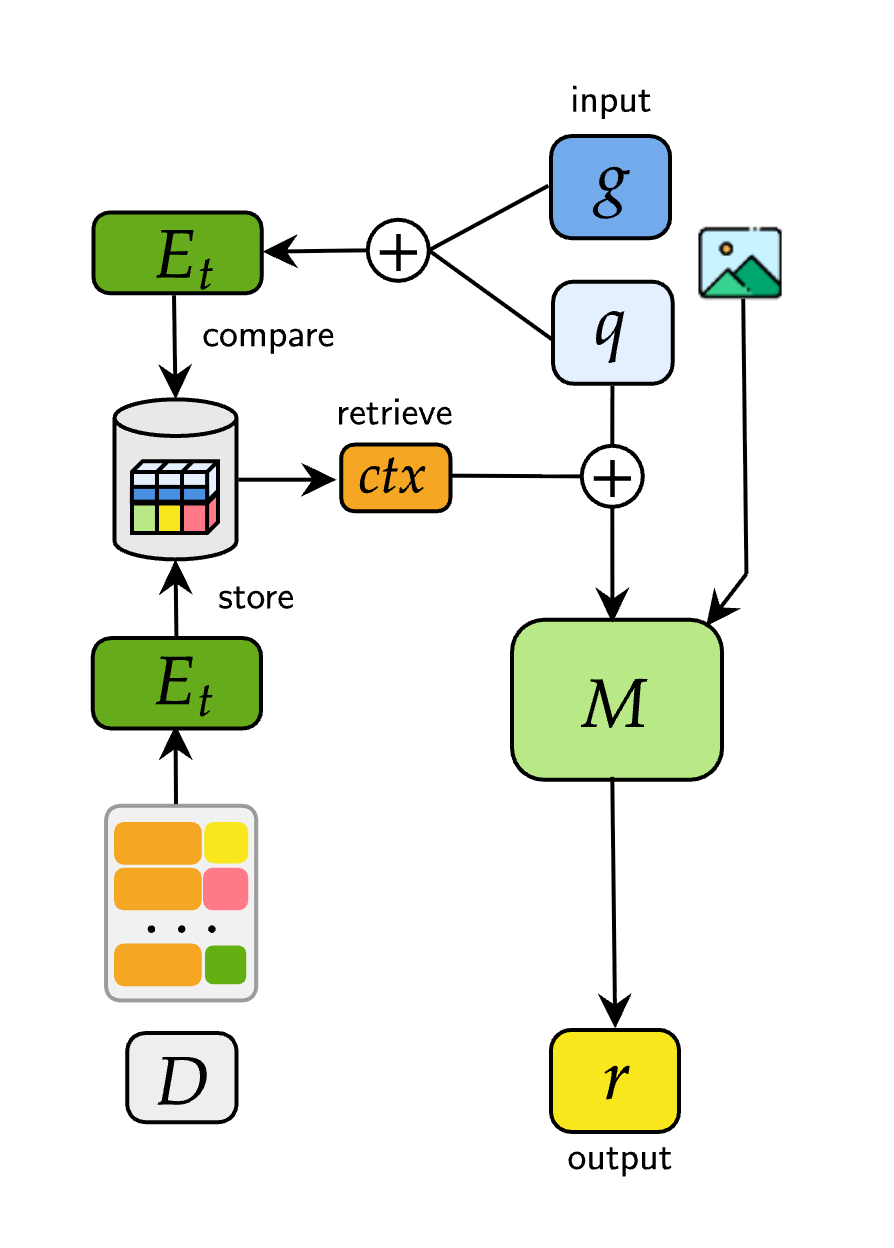
技术框架:M4-RAG基准包含以下几个关键组成部分:1) 一个包含超过80,000个图像-问题对的数据集,覆盖42种语言和56种区域方言和语域,保证文化多样性。2) 一个受控的检索环境,包含数百万个与查询领域相关的多语言文档,用于模拟真实世界的检索条件。3) 一套评估流程,用于评估不同RAG方法在VQA任务中的性能。整体流程是:给定图像和问题,模型首先从检索环境中检索相关文档,然后利用检索到的信息生成答案。
关键创新:M4-RAG的主要创新在于其大规模、多语言、多文化的特性,以及构建的受控检索环境。与现有VQA数据集相比,M4-RAG更贴近真实世界的应用场景,能够更全面地评估RAG方法在不同语言和文化背景下的性能。此外,受控检索环境保证了实验的可重复性和一致性。
关键设计:M4-RAG数据集的构建过程中,作者们精心挑选了具有文化代表性的图像和问题,并进行了多语言翻译和校对,以保证数据的质量和多样性。受控检索环境的构建过程中,作者们收集了大量的多语言文档,并进行了清洗和索引,以保证检索的效率和准确性。具体的参数设置、损失函数、网络结构等技术细节取决于具体的RAG模型,论文主要关注基准数据集的构建和评估。
🖼️ 关键图片
📊 实验亮点
M4-RAG的实验结果表明,RAG方法对小型VLM有显著的性能提升,但对大型VLM的提升效果不明显,甚至可能降低性能。这一发现揭示了当前RAG方法在模型规模扩展方面存在瓶颈,需要进一步研究更有效的检索和融合策略。例如,在某些语言上,RAG甚至导致了5%以上的性能下降。
🎯 应用场景
M4-RAG的研究成果可应用于多语言智能客服、跨文化教育、全球内容推荐等领域。通过提升多语言多模态RAG系统的性能,可以更好地服务于全球用户,促进不同文化之间的交流和理解。未来,该研究有望推动通用人工智能的发展,使其能够更好地理解和处理不同语言和文化的信息。
📄 摘要(原文)
Vision-language models (VLMs) have achieved strong performance in visual question answering (VQA), yet they remain constrained by static training data. Retrieval-Augmented Generation (RAG) mitigates this limitation by enabling access to up-to-date, culturally grounded, and multilingual information; however, multilingual multimodal RAG remains largely underexplored. We introduce M4-RAG, a massive-scale benchmark covering 42 languages and 56 regional dialects and registers, comprising over 80,000 culturally diverse image-question pairs for evaluating retrieval-augmented VQA across languages and modalities. To balance realism with reproducibility, we build a controlled retrieval environment containing millions of carefully curated multilingual documents relevant to the query domains, approximating real-world retrieval conditions while ensuring consistent experimentation. Our systematic evaluation reveals that although RAG consistently benefits smaller VLMs, it fails to scale to larger models and often even degrades their performance, exposing a critical mismatch between model size and current retrieval effectiveness. M4-RAG provides a foundation for advancing next-generation RAG systems capable of reasoning seamlessly across languages, modalities, and cultural contexts.