Efficient Text Classification with Conformal In-Context Learning
作者: Ippokratis Pantelidis, Korbinian Randl, Aron Henriksson
分类: cs.CL, cs.AI
发布日期: 2025-12-05
备注: 10 pages, 4 tables, 2 figures
💡 一句话要点
提出Conformal In-Context Learning (CICLe)框架,提升LLM文本分类效率与泛化性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本分类 大型语言模型 上下文学习 Conformal Prediction 效率优化
📋 核心要点
- 现有LLM文本分类依赖提示工程,计算成本高,泛化性受限。
- CICLe框架结合轻量级分类器和Conformal Prediction,自适应减少LLM候选类别。
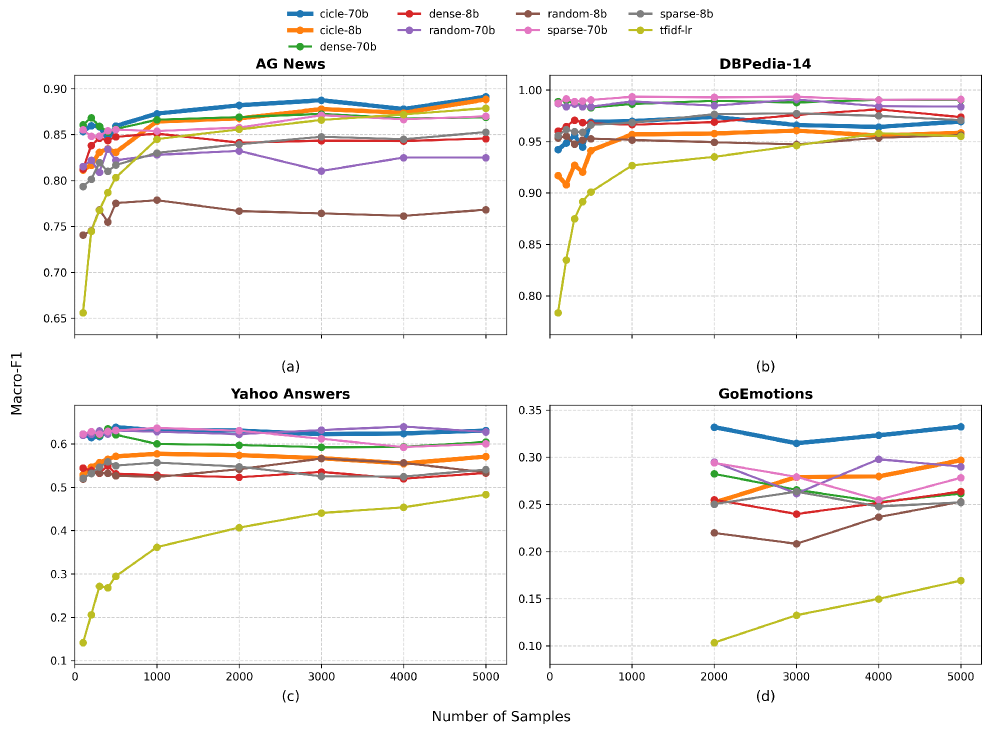
- 实验表明CICLe在多种NLP任务上提升了效率和性能,尤其擅长处理类别不平衡问题。
📝 摘要(中文)
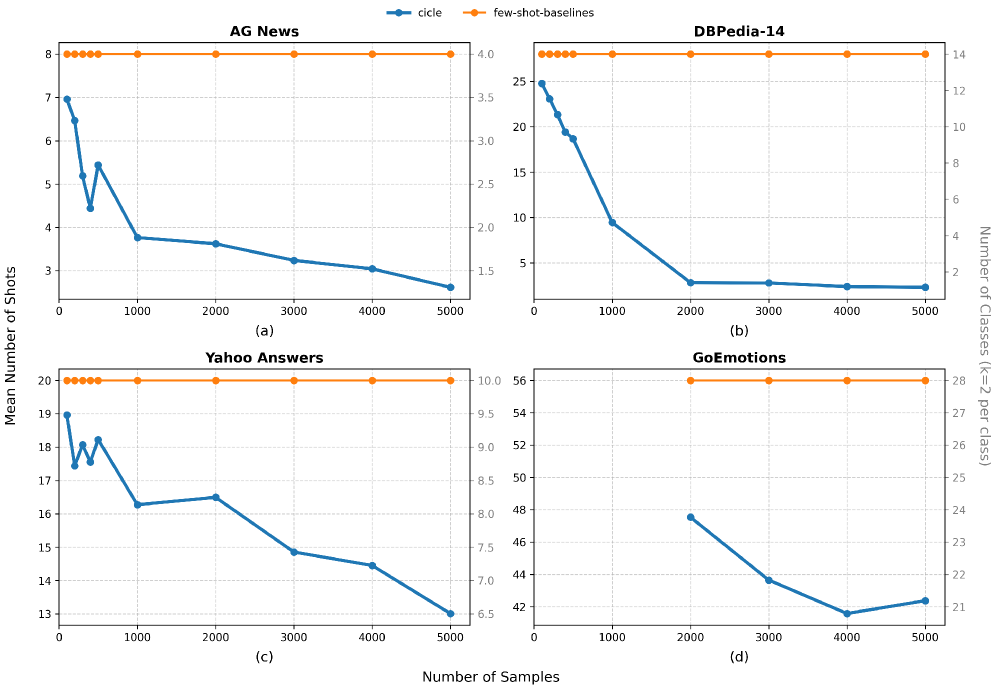
大型语言模型(LLMs)展现了强大的上下文学习能力,但其在文本分类中的有效性严重依赖于提示设计,并且计算成本高昂。Conformal In-Context Learning (CICLe)被提出作为一个资源高效的框架,它将轻量级的基础分类器与Conformal Prediction相结合,通过自适应地减少候选类别集合来指导LLM提示。然而,其在单个领域之外的更广泛适用性和效率优势尚未得到系统地探索。本文对CICLe在各种NLP分类基准上进行了全面评估。结果表明,当样本量足以训练基础分类器时,CICLe始终优于其基础分类器,并且优于少样本提示基线,并且在低数据情况下表现相当。在效率方面,CICLe分别将shots数量和提示长度最多减少了34.45%和25.16%,并能够使用具有竞争力的性能的较小模型。此外,CICLe对于具有高类别不平衡的文本分类任务特别有利。这些发现突出了CICLe作为一种实用且可扩展的有效文本分类方法,它结合了传统分类器的鲁棒性和LLM的适应性,并在数据和计算效率方面实现了显著的提升。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在文本分类任务中效率低下的问题。现有方法依赖于复杂的提示工程,计算成本高昂,并且在不同领域和数据集上的泛化能力有限。特别是在类别不平衡的情况下,LLM的性能会进一步下降。
核心思路:论文的核心思路是利用一个轻量级的基础分类器来预先筛选候选类别,从而减少LLM需要考虑的类别数量。通过结合Conformal Prediction,CICLe能够自适应地调整候选类别集合,平衡准确性和效率。这种方法旨在结合传统分类器的鲁棒性和LLM的上下文学习能力。
技术框架:CICLe框架包含以下主要模块:1) 基础分类器:使用轻量级的分类器(如逻辑回归或支持向量机)对输入文本进行初步分类,预测可能的类别。2) Conformal Prediction:利用Conformal Prediction技术,根据基础分类器的预测结果,生成一个置信集合,包含最有可能的类别。3) LLM Prompting:使用置信集合中的类别来构建LLM的提示,引导LLM进行更精确的分类。4) 最终分类:LLM根据提示进行分类,输出最终的预测结果。
关键创新:CICLe的关键创新在于将Conformal Prediction与LLM的上下文学习相结合,实现了一种自适应的提示策略。与传统的提示工程方法相比,CICLe能够自动地调整提示内容,减少了人工干预的需求,并且提高了效率。此外,CICLe还能够利用轻量级的基础分类器来降低计算成本,使得在资源受限的环境中使用LLM进行文本分类成为可能。
关键设计:CICLe的关键设计包括:1) 基础分类器的选择:论文中使用了逻辑回归作为基础分类器,但也可以根据具体任务选择其他轻量级的分类器。2) Conformal Prediction的置信水平:置信水平决定了置信集合的大小,需要在准确性和效率之间进行权衡。3) LLM提示的设计:提示的设计需要考虑到LLM的特点,尽可能清晰地表达分类任务的目标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CICLe在多个NLP分类基准上优于基础分类器和少样本提示基线。CICLe最多可将shots数量减少34.45%,提示长度减少25.16%。此外,CICLe在处理类别不平衡问题时表现出显著优势,并且能够使用更小的模型达到具有竞争力的性能。这些结果表明CICLe在效率和准确性方面都具有显著的优势。
🎯 应用场景
CICLe框架可应用于各种文本分类场景,如情感分析、主题分类、垃圾邮件检测等。尤其适用于需要高效率和低计算成本的应用,例如移动设备上的文本分类、实时信息过滤等。该研究有助于推动LLM在资源受限环境下的应用,并为构建更智能、更高效的文本分类系统提供了一种新的思路。
📄 摘要(原文)
Large Language Models (LLMs) demonstrate strong in-context learning abilities, yet their effectiveness in text classification depends heavily on prompt design and incurs substantial computational cost. Conformal In-Context Learning (CICLe) has been proposed as a resource-efficient framework that integrates a lightweight base classifier with Conformal Prediction to guide LLM prompting by adaptively reducing the set of candidate classes. However, its broader applicability and efficiency benefits beyond a single domain have not yet been systematically explored. In this paper, we present a comprehensive evaluation of CICLe across diverse NLP classification benchmarks. The results show that CICLe consistently improves over its base classifier and outperforms few-shot prompting baselines when the sample size is sufficient for training the base classifier, and performs comparably in low-data regimes. In terms of efficiency, CICLe reduces the number of shots and prompt length by up to 34.45% and 25.16%, respectively, and enables the use of smaller models with competitive performance. CICLe is furthermore particularly advantageous for text classification tasks with high class imbalance. These findings highlight CICLe as a practical and scalable approach for efficient text classification, combining the robustness of traditional classifiers with the adaptability of LLMs, and achieving substantial gains in data and computational efficiency.