Interleaved Latent Visual Reasoning with Selective Perceptual Modeling
作者: Shuai Dong, Siyuan Wang, Xingyu Liu, Chenglin Li, Haowen Hou, Zhongyu Wei
分类: cs.CL, cs.CV
发布日期: 2025-12-05 (更新: 2026-01-21)
备注: 18 pages, 11 figures. Code available at https://github.com/XD111ds/ILVR
🔗 代码/项目: GITHUB
💡 一句话要点
提出ILVR框架,通过交错潜在视觉推理提升多模态大语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 交错推理 潜在视觉推理 自监督学习 视觉问答 图像描述 动态状态演化
📋 核心要点
- 现有交错推理范式因重复编码图像计算成本高昂,限制了多模态大语言模型的能力。
- ILVR框架通过交错潜在视觉表征与文本生成,并利用自监督学习动态演化视觉线索,实现精确感知建模。
- 实验结果表明,ILVR在多模态推理任务上超越现有方法,提升了细粒度感知和序列推理能力。
📝 摘要(中文)
本文提出了一种交错潜在视觉推理(ILVR)框架,旨在提升多模态大语言模型(MLLMs)的性能,同时克服了像素密集图像重复编码带来的计算成本问题。ILVR框架统一了动态状态演化和精确感知建模。通过交错文本生成与潜在视觉表示,将后者作为后续推理的特定演化线索。该方法采用自监督策略,利用动量教师模型选择性地将来自真实中间图像的相关特征提炼为稀疏监督目标。这种自适应选择机制引导模型自主生成上下文感知的视觉信号。在多模态推理基准上的大量实验表明,ILVR优于现有方法,有效弥合了细粒度感知和序列多模态推理之间的差距。
🔬 方法详解
问题定义:现有的交错推理方法在多模态大语言模型中面临挑战。直接对像素级图像进行重复编码计算成本过高,而潜在视觉推理方法要么无法捕捉中间状态的演化(单步推理),要么过度压缩特征,牺牲了精确的感知建模能力。因此,如何高效地进行交错视觉推理,同时保持精确的感知建模是本文要解决的核心问题。
核心思路:ILVR的核心思路是将文本生成与潜在视觉表征交错进行,利用潜在视觉表征作为特定且不断演化的线索,指导后续的推理过程。通过这种交错的方式,模型可以动态地更新和调整其对视觉信息的理解,从而更好地进行多模态推理。
技术框架:ILVR框架包含以下主要模块:1) 文本编码器:用于编码输入的文本信息。2) 潜在视觉编码器:将图像编码为潜在视觉表示。3) 交错推理模块:交替进行文本生成和潜在视觉推理,利用潜在视觉表示作为线索指导文本生成,并根据生成的文本更新潜在视觉表示。4) 自监督学习模块:利用动量教师模型从真实中间图像中提取相关特征,作为稀疏监督信号,指导潜在视觉编码器的学习。
关键创新:ILVR的关键创新在于:1) 交错推理结构:通过交错文本生成和潜在视觉推理,实现了动态的状态演化。2) 自适应选择机制:利用动量教师模型选择性地提取相关特征,生成上下文感知的视觉信号,避免了过度压缩特征。3) 稀疏监督:使用稀疏监督目标,降低了计算成本,并提高了模型的泛化能力。
关键设计:ILVR的关键设计包括:1) 动量教师模型:用于生成高质量的监督信号。2) 自适应选择策略:根据上下文信息选择相关的视觉特征。3) 损失函数:包括文本生成损失和视觉表示学习损失,通过联合优化这两个损失函数,提高模型的整体性能。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


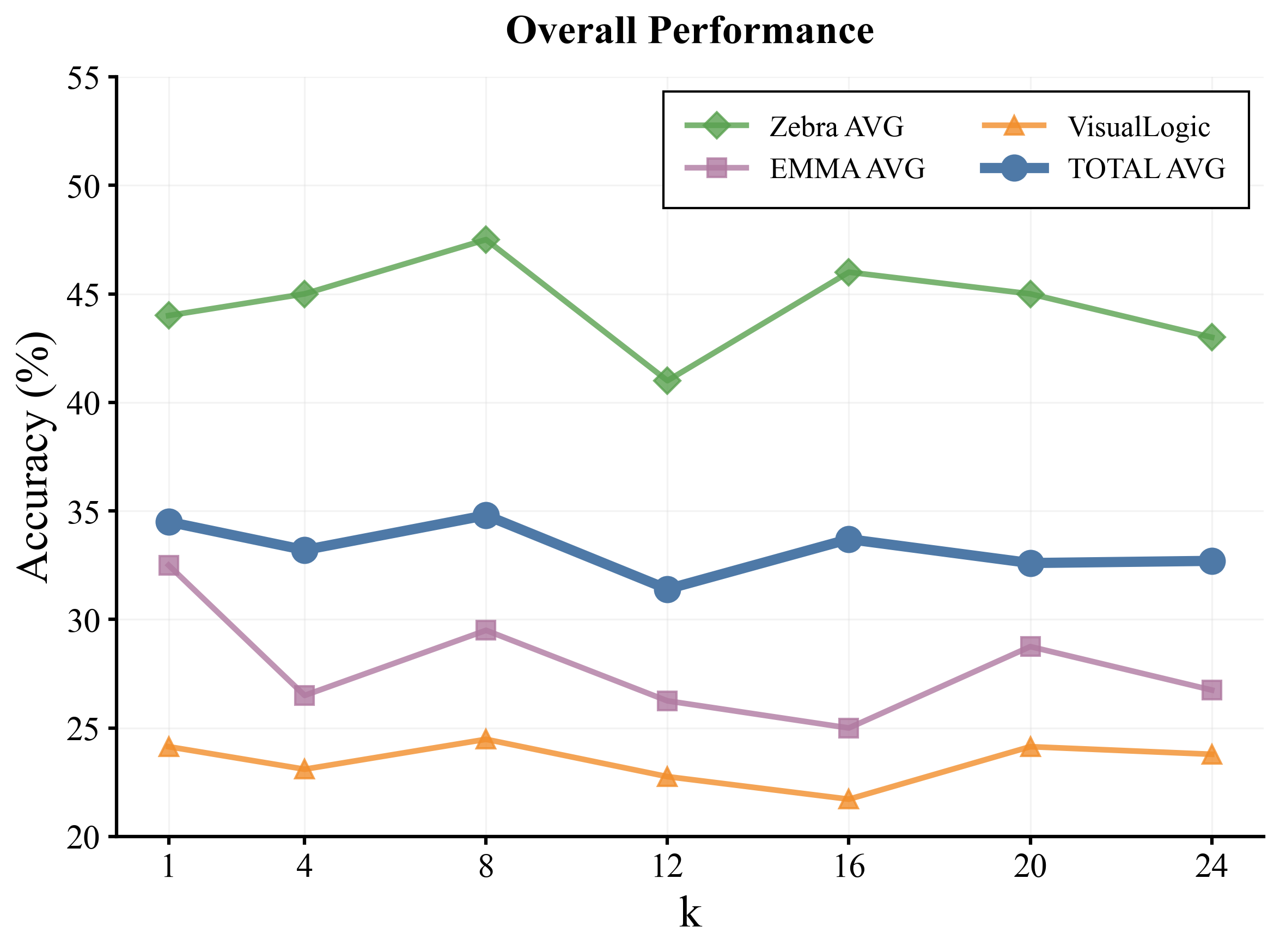
📊 实验亮点
ILVR在多个多模态推理基准测试中取得了显著的性能提升,证明了其有效性。具体而言,ILVR在视觉问答任务上超越了现有方法,并在图像描述任务上生成了更准确和更丰富的描述。实验结果表明,ILVR能够有效弥合细粒度感知和序列多模态推理之间的差距,为多模态人工智能的发展提供了新的思路。
🎯 应用场景
ILVR框架可应用于需要视觉信息辅助的各种任务,例如视觉问答、图像描述、机器人导航等。该研究有助于提升多模态人工智能系统的理解和推理能力,使其能够更好地理解和响应真实世界的复杂场景。未来,该方法有望应用于自动驾驶、智能家居、医疗诊断等领域。
📄 摘要(原文)
Interleaved reasoning paradigms enhance Multimodal Large Language Models (MLLMs) with visual feedback but are hindered by the prohibitive computational cost of re-encoding pixel-dense images. A promising alternative, latent visual reasoning, circumvents this bottleneck yet faces limitations: methods either fail to capture intermediate state evolution due to single-step, non-interleaved structures, or sacrifice precise perceptual modeling by over-compressing features. We introduce Interleaved Latent Visual Reasoning (ILVR), a framework that unifies dynamic state evolution with precise perceptual modeling. ILVR interleaves textual generation with latent visual representations that act as specific, evolving cues for subsequent reasoning. Specifically, we employ a self-supervision strategy where a momentum teacher model selectively distills relevant features from ground-truth intermediate images into sparse supervision targets. This adaptive selection mechanism guides the model to autonomously generate context-aware visual signals. Extensive experiments on multimodal reasoning benchmarks demonstrate that ILVR outperforms existing approaches, effectively bridging the gap between fine-grained perception and sequential multimodal reasoning. The code is available at https://github.com/XD111ds/ILVR.