Dynamic Alignment for Collective Agency: Toward a Scalable Self-Improving Framework for Open-Ended LLM Alignment
作者: Panatchakorn Anantaprayoon, Nataliia Babina, Jad Tarifi, Nima Asgharbeygi
分类: cs.CL, cs.AI
发布日期: 2025-12-05
备注: 8 pages, 4 figures, to appear in AAAI 2026 AIGOV Workshop
💡 一句话要点
提出动态对齐框架,实现LLM在集体能动性上的可扩展自改进对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型对齐 自改进学习 集体能动性 动态对齐 人工智能安全
📋 核心要点
- 现有LLM对齐方法依赖人类反馈或预定义原则,难以适应AGI/ASI发展,且扩展性受限。
- 提出动态对齐框架,通过集体能动性(CA)目标和自奖励机制,实现LLM的迭代自对齐。
- 实验表明,该方法成功将模型与CA对齐,同时保持了模型原有的自然语言处理能力。
📝 摘要(中文)
大型语言模型(LLM)通常使用偏好数据或预定义的原则(如乐于助人、诚实和无害)与人类价值观对齐。然而,随着人工智能系统向通用人工智能(AGI)和超人工智能(ASI)发展,这种价值体系可能变得不足。此外,基于人类反馈的对齐仍然是资源密集型且难以扩展的。虽然基于AI反馈的自改进对齐方法已被探索作为一种可扩展的替代方案,但它们在很大程度上仍受限于传统的对齐价值观。在这项工作中,我们探索了一个更全面的对齐目标和一个可扩展的自改进对齐方法。为了超越传统的对齐规范,我们引入了集体能动性(CA)——一种统一且开放式的对齐价值,鼓励整合的能动能力。我们还提出了动态对齐——一种对齐框架,使LLM能够迭代地自我对齐。动态对齐包括两个关键组成部分:(1)使用LLM自动生成训练数据集,以及(2)一种自我奖励机制,其中策略模型评估其自身的输出候选者,并为基于GRPO的学习分配奖励。实验结果表明,我们的方法成功地将模型与CA对齐,同时保留了一般的NLP能力。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法,如基于人类反馈的强化学习(RLHF),存在成本高昂、难以扩展的问题。此外,传统的对齐目标(如乐于助人、诚实和无害)可能不足以应对未来通用人工智能和超人工智能的需求。因此,需要一种可扩展的、能够适应更广泛价值体系的对齐方法。
核心思路:论文的核心思路是利用LLM自身的能力进行自改进对齐。通过引入“集体能动性”(Collective Agency,CA)这一更广泛的对齐目标,并设计一种动态对齐框架,使LLM能够迭代地生成训练数据、评估自身输出并进行自我奖励,从而实现持续的自我改进。这种方法旨在降低对人类反馈的依赖,并提高对齐过程的可扩展性。
技术框架:动态对齐框架包含两个主要组成部分:1) 自动训练数据集生成:利用LLM生成用于对齐训练的数据集,避免人工标注的成本。2) 自奖励机制:策略模型(policy model)生成输出候选,然后由模型自身评估这些候选,并根据GRPO(Generalized Preference Optimization)算法为学习过程分配奖励。整个过程迭代进行,使模型不断向集体能动性目标对齐。
关键创新:该论文的关键创新在于提出了一个完全基于LLM的自改进对齐框架,摆脱了对大量人工标注数据的依赖。此外,引入了“集体能动性”这一更具包容性的对齐目标,旨在超越传统的对齐价值观,使模型能够更好地适应未来人工智能的发展。
关键设计:论文使用了GRPO(Generalized Preference Optimization)作为奖励学习的算法。具体的技术细节包括如何设计提示词(prompts)来引导LLM生成高质量的训练数据,以及如何定义奖励函数来衡量输出候选的集体能动性。此外,论文还关注了如何平衡对齐目标和模型原有能力之间的关系,以避免过度优化导致模型性能下降。
🖼️ 关键图片


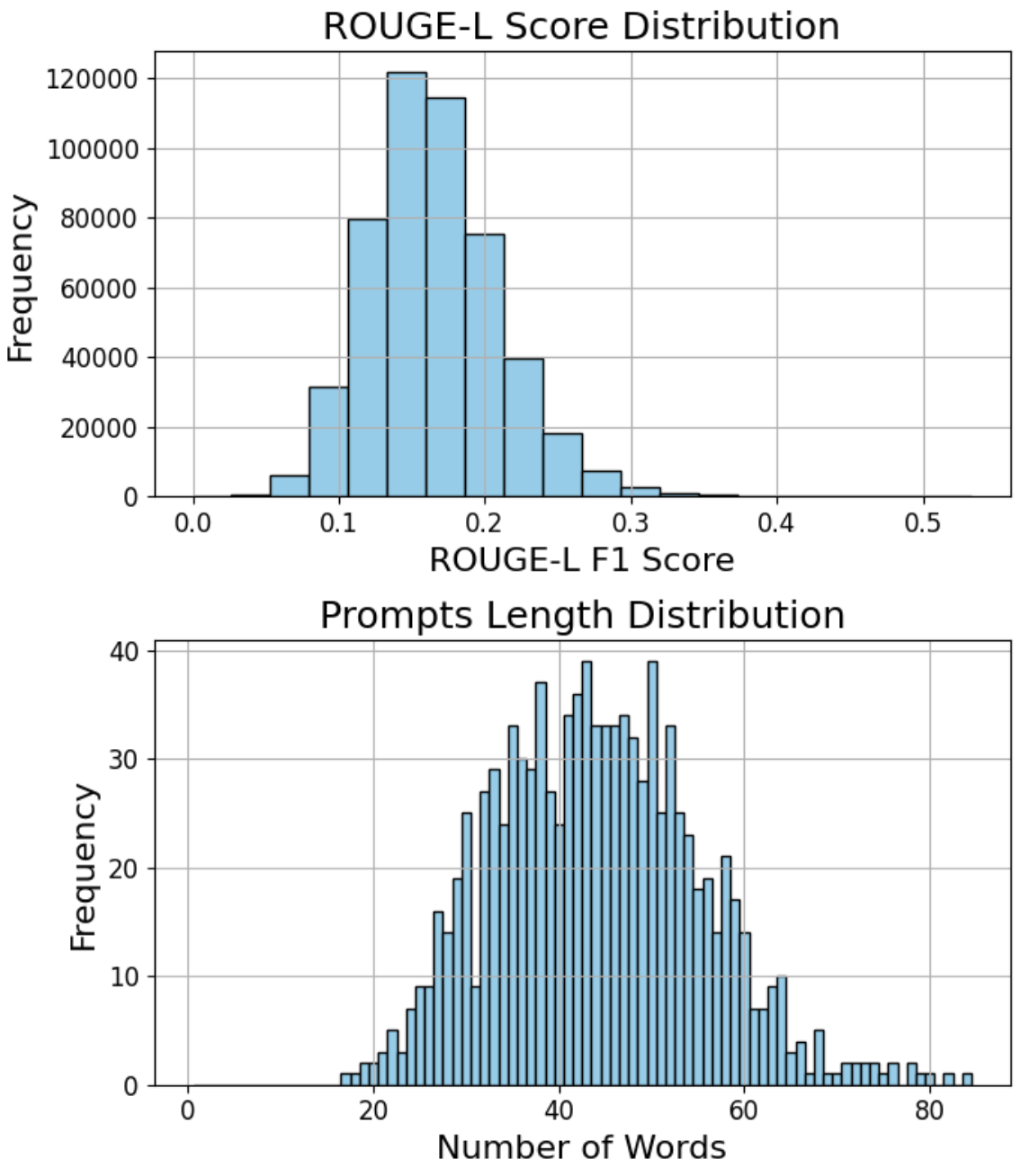
📊 实验亮点
实验结果表明,提出的动态对齐框架能够成功地将LLM与集体能动性(CA)对齐,同时保持了模型原有的自然语言处理能力。具体性能数据未知,但论文强调该方法在实现对齐的同时,避免了模型性能的显著下降。
🎯 应用场景
该研究成果可应用于构建更安全、更可靠、更符合人类价值观的通用人工智能系统。通过自改进对齐,LLM能够更好地理解和适应复杂环境,并在各种任务中表现出更强的能动性和协作能力。此外,该方法有望降低LLM对齐的成本,加速人工智能技术的普及和应用。
📄 摘要(原文)
Large Language Models (LLMs) are typically aligned with human values using preference data or predefined principles such as helpfulness, honesty, and harmlessness. However, as AI systems progress toward Artificial General Intelligence (AGI) and Artificial Superintelligence (ASI), such value systems may become insufficient. In addition, human feedback-based alignment remains resource-intensive and difficult to scale. While AI-feedback-based self-improving alignment methods have been explored as a scalable alternative, they have largely remained constrained to conventional alignment values. In this work, we explore both a more holistic alignment objective and a scalable, self-improving alignment approach. Aiming to transcend conventional alignment norms, we introduce Collective Agency (CA)-a unified and open-ended alignment value that encourages integrated agentic capabilities. We also propose Dynamic Alignment-an alignment framework that enables an LLM to iteratively align itself. Dynamic Alignment comprises two key components: (1) automated training dataset generation with LLMs, and (2) a self-rewarding mechanism, where the policy model evaluates its own output candidates and assigns rewards for GRPO-based learning. Experimental results demonstrate that our approach successfully aligns the model to CA while preserving general NLP capabilities.