ArtistMus: A Globally Diverse, Artist-Centric Benchmark for Retrieval-Augmented Music Question Answering
作者: Daeyong Kwon, SeungHeon Doh, Juhan Nam
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2025-12-05
备注: Submitted to LREC 2026. This work is an evolution of our earlier preprint arXiv:2507.23334
💡 一句话要点
提出ArtistMus:一个以艺术家为中心的、全局多样性的音乐问答检索增强基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音乐问答 检索增强生成 知识库构建 大型语言模型 音乐信息检索
📋 核心要点
- 现有大型语言模型在音乐领域知识匮乏,限制了其在音乐问答任务中的表现。
- 论文提出MusWikiDB和ArtistMus,构建了大规模音乐知识库和多样化的音乐问答基准。
- 实验表明,检索增强生成(RAG)能显著提升音乐问答的事实准确性,RAG微调进一步提升性能。
📝 摘要(中文)
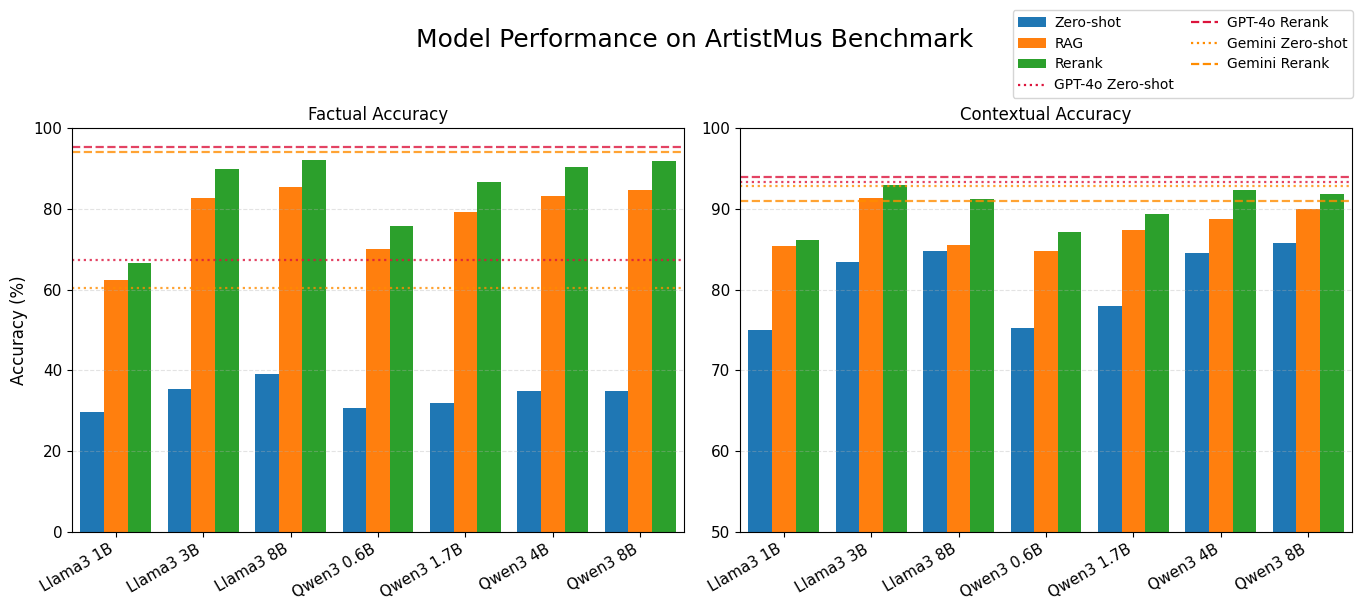
大型语言模型(LLMs)的最新进展改变了开放域问答,但由于预训练数据中稀疏的音乐知识,它们在音乐相关推理方面的有效性仍然有限。虽然音乐信息检索和计算音乐学已经探索了结构化和多模态理解,但很少有资源支持基于艺术家元数据或历史背景的事实和上下文音乐问答(MQA)。我们引入了MusWikiDB,一个包含来自14.4万个音乐相关维基百科页面的320万段落的向量数据库,以及ArtistMus,一个包含关于500位不同艺术家的1000个问题的基准,这些艺术家具有流派、出道年份和主题等元数据。这些资源能够系统地评估用于MQA的检索增强生成(RAG)。实验表明,RAG显著提高了事实准确性;开源模型获得了高达+56.8个百分点的提升(例如,Qwen3 8B从35.0提高到91.8),接近专有模型的性能。RAG风格的微调进一步提高了事实召回率和上下文推理能力,从而提高了在域内和域外基准上的结果。MusWikiDB还比通用维基百科语料库产生大约6个百分点的更高准确率和40%的更快检索速度。我们发布MusWikiDB和ArtistMus,以推进音乐信息检索和特定领域问答的研究,为音乐等文化丰富领域的检索增强推理奠定基础。
🔬 方法详解
问题定义:现有的大型语言模型在音乐领域的知识储备不足,导致在音乐问答任务中表现不佳,尤其是在需要事实性知识和上下文理解的场景下。缺乏专门的音乐知识库和评估基准,使得难以系统地评估和提升模型在音乐领域的问答能力。
核心思路:论文的核心思路是利用检索增强生成(RAG)框架,通过构建大规模的音乐知识库MusWikiDB,并结合多样化的音乐问答基准ArtistMus,来提升模型在音乐领域的问答能力。RAG框架通过检索相关知识来增强生成过程,从而提高答案的事实准确性和上下文相关性。
技术框架:整体框架包含以下几个主要模块:1) MusWikiDB构建:从音乐相关的维基百科页面中提取文本段落,构建向量数据库。2) ArtistMus基准构建:收集关于500位不同艺术家的1000个问题,并标注答案。3) RAG模型训练:使用RAG框架,结合MusWikiDB和ArtistMus,训练音乐问答模型。4) RAG微调:对RAG模型进行微调,进一步提升性能。
关键创新:论文的关键创新在于构建了专门针对音乐领域的知识库MusWikiDB和问答基准ArtistMus。MusWikiDB包含大量的音乐相关信息,可以有效地支持RAG模型进行知识检索。ArtistMus基准涵盖了多样化的艺术家和问题,可以全面评估模型的音乐问答能力。此外,论文还探索了RAG风格的微调方法,进一步提升了模型的性能。
关键设计:MusWikiDB使用向量数据库来存储文本段落,以便快速检索相关知识。ArtistMus基准中的问题涵盖了艺术家的元数据(如流派、出道年份)和历史背景。RAG模型使用预训练的语言模型作为生成器,并使用余弦相似度等方法来检索相关知识。RAG微调使用交叉熵损失函数来优化模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RAG显著提高了音乐问答的事实准确性,开源模型Qwen3 8B的准确率从35.0%提升到91.8%,接近专有模型的性能。MusWikiDB比通用维基百科语料库产生大约6个百分点的更高准确率和40%的更快检索速度。RAG风格的微调进一步提高了事实召回率和上下文推理能力。
🎯 应用场景
该研究成果可应用于智能音乐助手、音乐知识图谱构建、音乐教育等领域。通过提供准确、全面的音乐知识问答服务,可以提升用户体验,促进音乐文化的传播和学习。未来,该研究可以扩展到其他文化领域,构建更广泛的知识问答系统。
📄 摘要(原文)
Recent advances in large language models (LLMs) have transformed open-domain question answering, yet their effectiveness in music-related reasoning remains limited due to sparse music knowledge in pretraining data. While music information retrieval and computational musicology have explored structured and multimodal understanding, few resources support factual and contextual music question answering (MQA) grounded in artist metadata or historical context. We introduce MusWikiDB, a vector database of 3.2M passages from 144K music-related Wikipedia pages, and ArtistMus, a benchmark of 1,000 questions on 500 diverse artists with metadata such as genre, debut year, and topic. These resources enable systematic evaluation of retrieval-augmented generation (RAG) for MQA. Experiments show that RAG markedly improves factual accuracy; open-source models gain up to +56.8 percentage points (for example, Qwen3 8B improves from 35.0 to 91.8), approaching proprietary model performance. RAG-style fine-tuning further boosts both factual recall and contextual reasoning, improving results on both in-domain and out-of-domain benchmarks. MusWikiDB also yields approximately 6 percentage points higher accuracy and 40% faster retrieval than a general-purpose Wikipedia corpus. We release MusWikiDB and ArtistMus to advance research in music information retrieval and domain-specific question answering, establishing a foundation for retrieval-augmented reasoning in culturally rich domains such as music.