LMSpell: Neural Spell Checking for Low-Resource Languages
作者: Akesh Gunathilake, Nadil Karunarathna, Tharusha Bandaranayake, Nisansa de Silva, Surangika Ranathunga
分类: cs.CL
发布日期: 2025-12-05 (更新: 2025-12-11)
💡 一句话要点
提出LMSpell,用于低资源语言的神经拼写检查工具包
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源语言 拼写校正 预训练语言模型 大型语言模型 神经拼写检查
📋 核心要点
- 低资源语言的拼写校正面临数据稀缺和模型泛化能力不足的挑战。
- LMSpell利用大型语言模型(LLMs)的强大能力,并通过微调适应低资源语言的拼写校正任务。
- 实验表明,即使LLM未在目标语言上预训练,也能通过微调获得显著的性能提升,并发布易用工具包。
📝 摘要(中文)
拼写校正对于低资源语言(LRLs)仍然是一个具有挑战性的问题。虽然预训练语言模型(PLMs)已被用于拼写校正,但它们的使用仍然局限于少数几种语言,并且缺乏对不同PLM之间的适当比较。我们提出了第一个关于PLM在拼写校正方面的有效性的实证研究,其中包括LRLs。我们发现,当微调数据集很大时,大型语言模型(LLMs)优于其对应模型(基于编码器和编码器-解码器)。即使在LLM未经过预训练的语言中,这种观察结果也成立。我们发布了LMSpell,一个易于使用的跨PLM的拼写校正工具包。它包括一个评估函数,可以补偿LLM的幻觉问题。此外,我们提出了一个以僧伽罗语为例的案例研究,以阐明LRLs拼写校正的困境。
🔬 方法详解
问题定义:论文旨在解决低资源语言(LRLs)的拼写校正问题。现有的拼写校正方法在LRLs上表现不佳,主要原因是数据稀缺,以及预训练语言模型(PLMs)对这些语言的支持不足。此外,缺乏对不同PLM在拼写校正任务上的有效性进行比较的研究。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的语言建模能力,通过在少量目标语言数据上进行微调,使其适应LRLs的拼写校正任务。即使LLM没有在目标语言上进行预训练,其强大的泛化能力也能带来显著的性能提升。
技术框架:LMSpell工具包的核心是基于预训练语言模型的拼写校正流程。该流程包括以下几个主要阶段:1) 选择合适的预训练语言模型(如BERT、GPT等);2) 准备目标语言的拼写错误-正确文本对数据集;3) 使用该数据集对PLM进行微调,使其学习拼写校正任务;4) 使用微调后的模型进行拼写校正;5) 使用论文提出的评估函数对模型进行评估,该评估函数可以补偿LLM的幻觉问题。
关键创新:论文的关键创新在于:1) 首次对多种PLM在LRLs拼写校正任务上的有效性进行了比较研究;2) 发现大型语言模型(LLMs)在数据量充足的情况下,优于其他类型的PLM,即使LLM未在目标语言上预训练;3) 提出了一个可以补偿LLM幻觉问题的评估函数;4) 发布了一个易于使用的跨PLM的拼写校正工具包LMSpell。
关键设计:论文的关键设计包括:1) 针对LLM的微调策略,例如学习率、batch size等超参数的设置;2) 评估函数的具体实现,如何检测和惩罚LLM的幻觉输出;3) LMSpell工具包的易用性设计,例如提供清晰的API和文档,方便用户快速上手。
🖼️ 关键图片


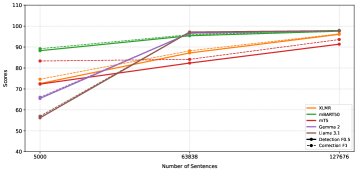
📊 实验亮点
实验结果表明,大型语言模型(LLMs)在低资源语言的拼写校正任务上表现出色,即使在未预训练的语言上也能取得显著的性能提升。与传统的基于编码器或编码器-解码器的模型相比,LLMs在数据量充足的情况下表现更优。LMSpell工具包的发布为LRLs的拼写校正提供了便捷的解决方案。
🎯 应用场景
该研究成果可应用于各种低资源语言的文本处理任务,例如机器翻译、信息检索、语音识别等。LMSpell工具包可以帮助开发者快速构建LRLs的拼写校正系统,提高文本处理的准确性和效率。未来,该研究可以扩展到其他自然语言处理任务,例如命名实体识别、情感分析等。
📄 摘要(原文)
Spell correction is still a challenging problem for low-resource languages (LRLs). While pretrained language models (PLMs) have been employed for spell correction, their use is still limited to a handful of languages, and there has been no proper comparison across PLMs. We present the first empirical study on the effectiveness of PLMs for spell correction, which includes LRLs. We find that Large Language Models (LLMs) outperform their counterparts (encoder-based and encoder-decoder) when the fine-tuning dataset is large. This observation holds even in languages for which the LLM is not pre-trained. We release LMSpell, an easy- to use spell correction toolkit across PLMs. It includes an evaluation function that compensates for the hallucination of LLMs. Further, we present a case study with Sinhala to shed light on the plight of spell correction for LRLs.